https://huggingface.co/learn/diffusion-course/unit0/1
noise_scheduler.alphas_cumprod 就已经有了
DDPMScheduler(num_train_timesteps=1000, beta_start=0.001, beta_end=0.004)
噪音少.
noise_scheduler = DDPMScheduler(num_train_timesteps=1000, beta_schedule='squaredcos_cap_v2') 增加的很慢, 相当于 warmup 和退火, 小 image 更好, 不会一开始就太大.
noise = torch.randn(clean_images.shape).to(clean_images.device)
noisy_images = noise_scheduler.add_noise(clean_images, noise, timesteps)
noise_pred = model(noisy_images, timesteps, return_dict=False)[0]
loss = F.mse_loss(noise_pred, noise)
保存 ckpt:
image_pipe = DDPMPipeline(unet=model, scheduler=noise_scheduler)
pipeline_output = image_pipe()
pipeline_output.images[0]
image_pipe.save_pretrained("my_pipeline")
反向采样:
for i, t in enumerate(noise_scheduler.timesteps):
with torch.no_grad():
residual = model(sample, t).sample # 得到随机噪声项
# Update sample with step
sample = noise_scheduler.step(residual, t, sample).prev_sample
前向过程是随机的,反向过程也必须是随机的,否则采样出来的样本分布不对。
ddim 通过修改调度公式可以 去掉随机噪声,仍然生成高质量样本 步数少很多.
不加随机性, 所以可以跳步. 确定性近似.
DDIM 的反向采样公式可以简化理解为:
x_{t-1} = (预测的 x₀) + (指向 xₜ 的方向) + (随机噪声)
其更具体的公式形式为:
x_{t-1} = sqrt(α_{t-1}) * (预测的 x₀) + sqrt(1 - α_{t-1} - σ_t²) * (预测的噪声) + σ_t * z
这里的关键在于 σ_t 的定义,它与 η 直接相关:
σ_t = η * sqrt((1 - α_{t-1}) / (1 - α_t)) * sqrt(1 - α_t / α_{t-1})
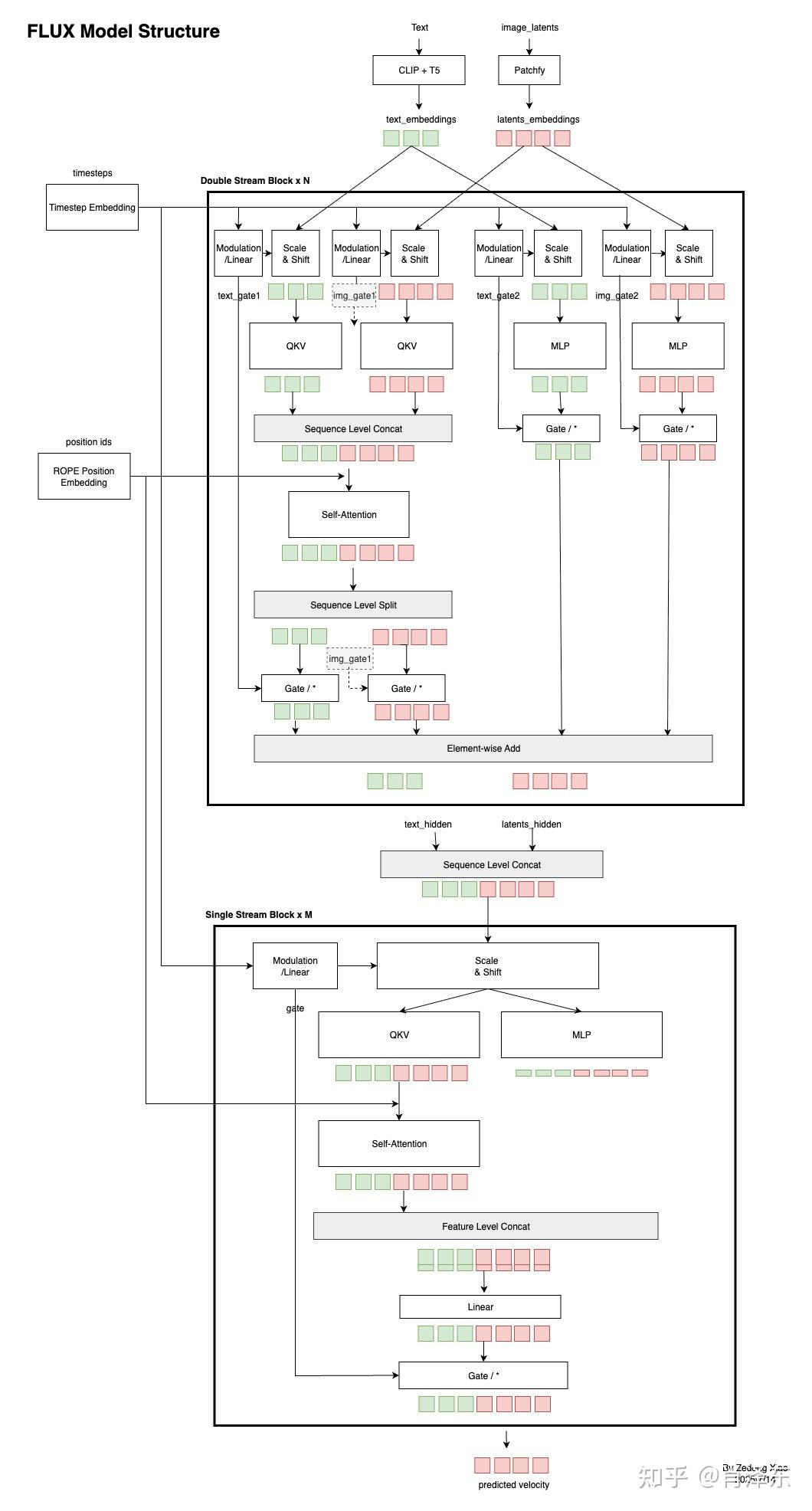
当 η = 0 时:σ_t 项变为 0,公式中的随机噪声项 z 被消除。此时,给定相同的初始噪声 xₜ,生成过程将是完全确定的(Deterministic)为啥 flux 要用双流?
每个流专注处理自己的模态特征,避免梯度互相污染。
为啥要有 gate mlp?
让模型自动学习每一层需要多少语言信息。 加入 gate(通常初始化为 0 或很小)能保证:模型先学“如何画好图像” 再逐渐学“文本怎么影响图像”.
一文读懂Stable Diffusion 论文原理+代码超详细解读 - 蓝色仙女的文章 - 知乎 https://zhuanlan.zhihu.com/p/640545463
Unet: https://pic3.zhimg.com/v2-03cf776c6281ff727e157e6088dbb394_r.jpg
{kind=link}
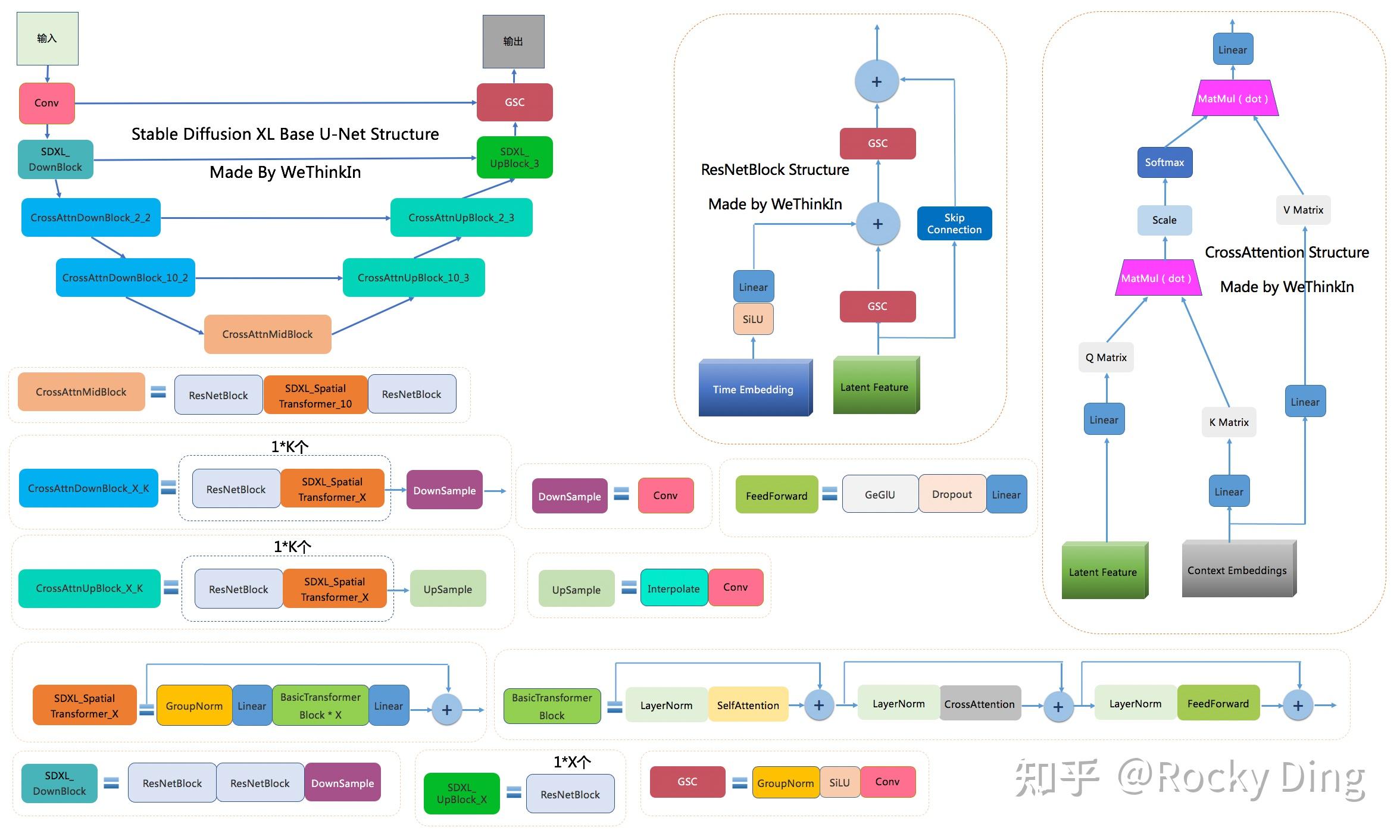
深入浅出完整解析Stable Diffusion XL(SDXL)核心基础知识 - Rocky Ding的文章 - 知乎 https://zhuanlan.zhihu.com/p/643420260
目录 https://www.zhihu.com/column/c_1646154470676168704
vae : https://pic3.zhimg.com/v2-a390d53cc59c0e76b0bbc86864f226ac_r.jpg
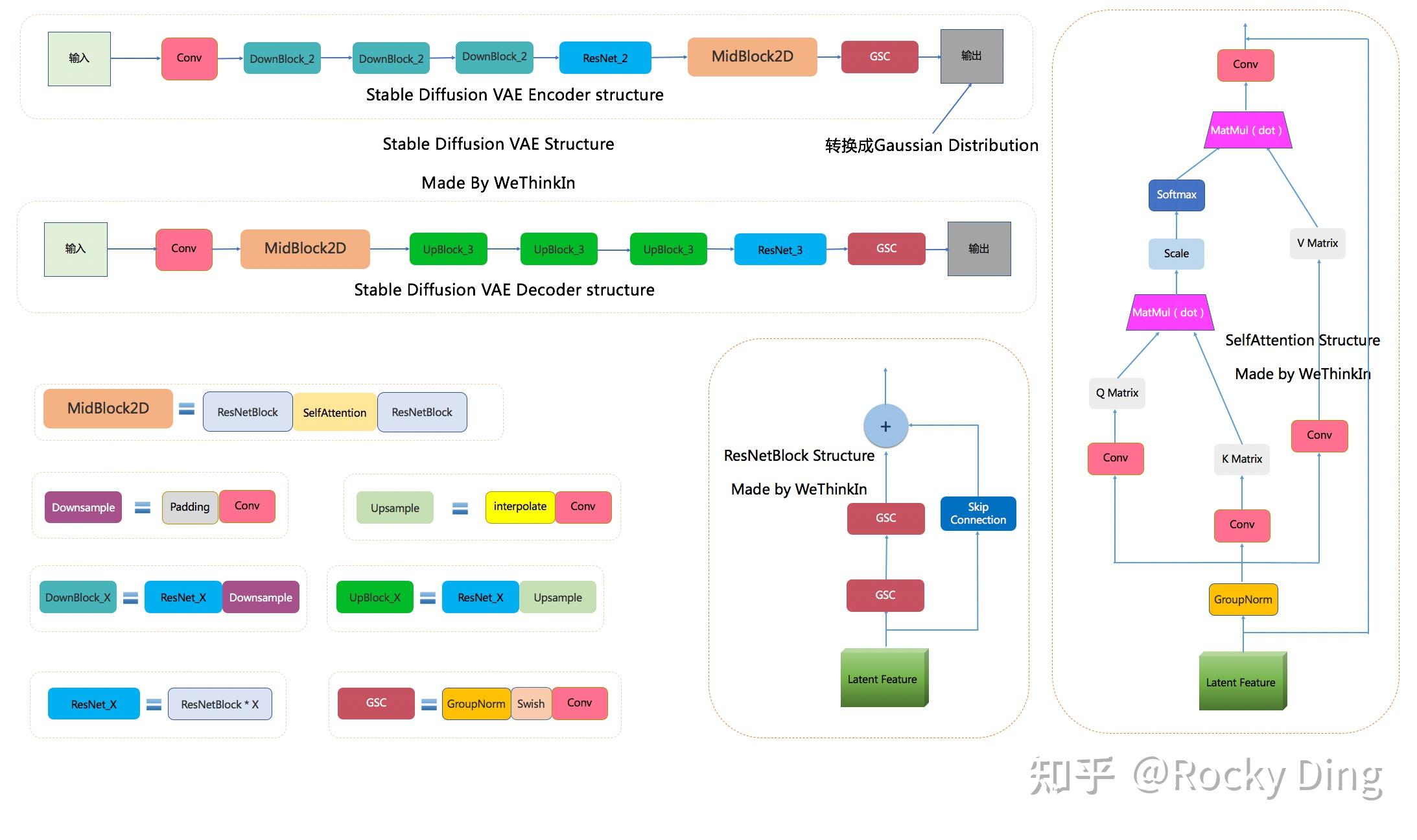{kind=link}
stable diffusion training, teacher是冻结的, 训练student vae+ Unet + encoder, 两个loss 加起来. 辨别器会平衡到50% 输出达到真假难辨.
在扩散模型中,如果定义了 3 个反向去噪的步骤(Step),UNet 会在每个步骤中执行一次。每一步都会将当前的带噪数据传递给 UNet,让其去噪并生成一个更接近最终输出的数据。因此,经过 3 个步骤,UNet 就会被调用 3 次。
python scripts/txt2img.py --prompt "a professional photograph of an astronaut riding a horse" --ckpt /root/share/stablediffusion/checkpoints --config /root/share/stablediffusion/configs/stable-diffusion/v2-inference.yaml
需要numpy 1.24 高了低了都不行.
turbo 不是ckpt, 但是sd 的pytorch 需要ckpt. 怎么办? 我写了一个试试.
ckpt被废弃了, 这两个仓库也被废弃了, 大家都在用diffusers.
https://github.com/diStyApps/Safe-and-Stable-Ckpt2Safetensors-Conversion-Tool-GUI 也不好用.
https://github.com/Stability-AI/generative-models/blob/main/scripts/demo/turbo.py
可以用调试 unet_debugging = torch.load("unet.pth")
然后在debug里面看. 或者 print (unet.xxx.attention_head_dim) https://huggingface.co/docs/diffusers/en/api/models/unet2d-cond 找source找到
https://github.com/huggingface/diffusers/blob/v0.30.3/src/diffusers/models/unets/unet_2d_condition.py#L71
debug也挺好的, 可以看所有东西, 不用写很多print语句.
要么hack diffusers. 但是最大难点是代码量太大了, 不知道跳转到哪里去了,可以debug step in. 但是无关的代码太多也难研究.
但是不要随意乱改lib, 可能以后出错了, 环境调不对就不知道哪里出错了.
我找到了optimal, 就pip install -e .就行了. 先debug找到用了哪个模型,根据名字找到 UNet2DConditionModel.
scripts/demo/sampling.py 没有turbo, 可以显示图片.
PYTHONPATH=. streamlit run scripts/demo/turbo.py 不显示图片, 为什么?
要先点击load model
open_clip_pytorch_model.bin有10个G.
OOM了.
f16可以用吗? 怎么用?
f16也OOM.
diffusers似乎默认用Lora 就可以.
diffusers/src/diffusers/models/unets/unet_2d_condition.py
compile,太慢了. 用了7分49s. 第二次就是2分20s.
为了防止量化引起的任何数值问题,我们以 bfloat16 格式运行所有内容。
https://pytorch.org/blog/accelerating-generative-ai-3/
torchao,FP8 precision must be used on devices with NVIDIA H100 and above
https://huggingface.co/blog/simple_sdxl_optimizations
fuse所有activation.
f16, Peak GPU memory usage: 7.47GB , time 6.42s一张图. 30 step, 4.62s.
pipe.unet.set_default_attn_processor()
pipe.vae.set_default_attn_processor()
没有区别, 为啥?
Time taken: 7.13 seconds 慢了 7.13-6.42=0.71 , 慢了9.96%. sdpa可以快10%
Time taken: 4.37 seconds , 快了4.62-4.37=0.25,快了 5.72%
Peak GPU memory usage: 7.49
Turbo, total params memory size = 6558.89MB (VRAM 6558.89MB, RAM 0.00MB): clip 1564.36MB(VRAM), unet 4900.07MB(VRAM), vae 94.47MB(VRAM), controlnet 0.00MB(VRAM),
turbo就是 https://github.com/Stability-AI/generative-models
https://learn.microsoft.com/en-us/windows/ai/directml/dml-fused-activations
https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
X0->x1->x2 -> z
每次加一点高斯噪声.
用Unet, 每个step
跳过路径直接将丰富且相对更多的低级信息从 Di 转发到 Ui 。在 U-Net 架构中的前向传播期间,数据同时通过两条路径遍历:主分支和 skip 分支.
skip分支代码在哪里?hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
视野范围越来越大, 但是看不到小的了. 两个数之间 距离其实越来越大. 只能看到最big picture, 看不到细节. 所以需要大层面的resnet. 用concat.
attention和 spatial transformer 差异是啥?
量化可以节省显存, 省GPU, pruning可以吗? 可以
34w下载, stable-video-diffusion-img2vid-xt, 9.56gb, fp16是 4.2 GB. 但是还是跑不起来. 不支持bf16.
onediff的 int8 运行不起来, 没人管.
A100支持bf16.
加速 cogvideox 智普AI和清华的. cogvideox 有8w下载, 非常可以.
Function Runtimes (s)
-------------------------------------- --------------
_compile 146.867
OutputGraph.call_user_compiler 132.066
create_aot_dispatcher_function 132.273
compile_fx.<locals>.fw_compiler_base 113.608
compile的时间非常久.