-
数组:具有随机访问的特点。在内存中划分出一些连续的空格子以备使用。内存中的每个格子都有自己的地址。
- 是一种线性表数据结构。它用一组连续的内存空间,来存储一组具有相同类型的数据。
- 最大的特点就是支持随机访问,但插入、删除操作也因此变得比较低效,平均情况时间复杂度为 O(n)。
-
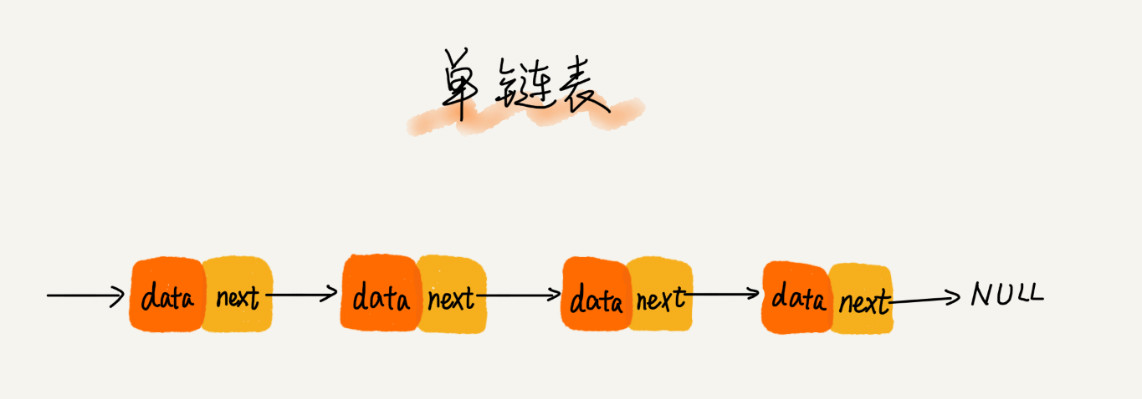
链表:链表不支持随机访问。由一系列分布在内存的各个角落的节点组成,每个节点除了保存数据,还保存着链表的下一个节点的内存地址。
- 单向链表:节点保存数据+下一个节点的内存地址
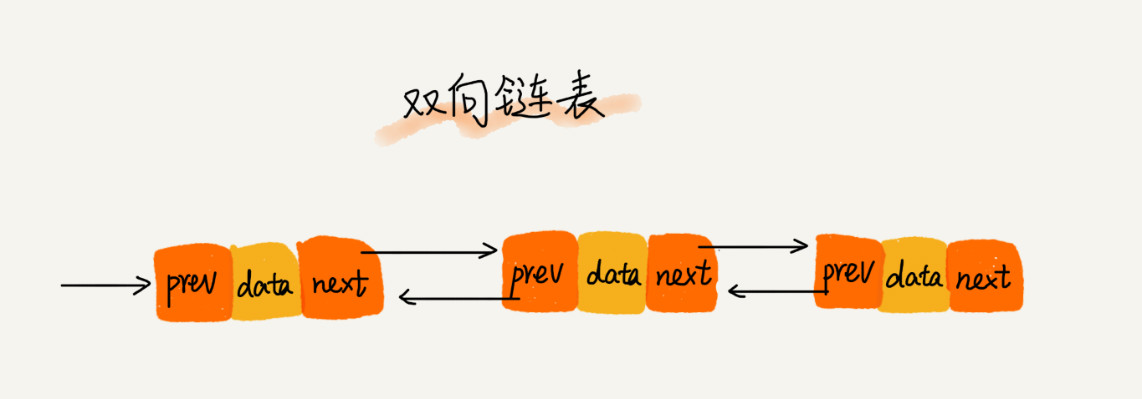
- 双向链表:节点保存数据+下一个节点内存地址+上一个节点内存地址
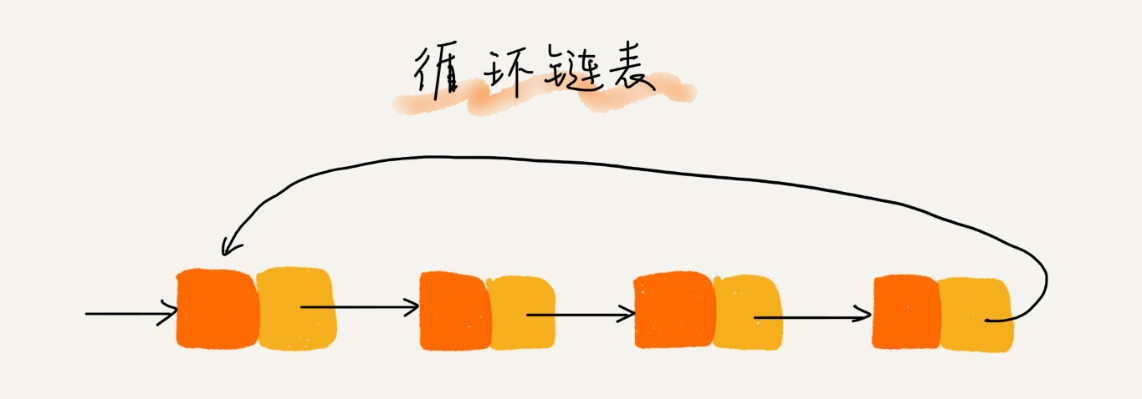
- 循环链表:尾结点指针是指向链表的头结点
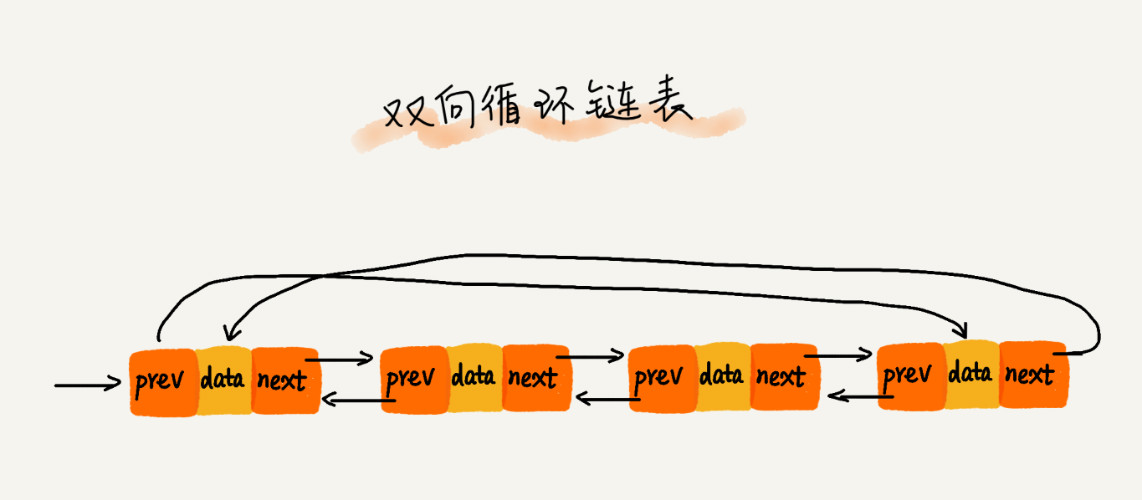
- 双向循环链表:
- 节点:把第一个结点叫作头结点,把最后一个结点叫作尾结点。其中,头结点用来记录链表的基地址。有了它,我们就可以遍历得到整条链表。而尾结点特殊的地方是:指针不是指向下一个结点,而是指向一个空地址 NULL,表示这是链表上最后一个结点。
-
栈
- 只能在末尾(栈顶)插入数据,压栈
- 只能读取末尾(栈顶)的数据
- 只能移除末尾(栈顶)的数据,出栈
-
队列
- 只能在末尾插入数据,入队
- 只能读取开头的数据
- 只能移除开头的数据,出队
- 使用双向链表,作为队列的底层数据结构,能实现插入和删除都为O(1)
-
哈希表/散列表,查找值的速度为O(1),适用于检查数据的存在性。
-
树:基于节点,每个接待你可用饱含多个链分别指向其他多个节点
- 根
- 父节点
- 子节点
-
二叉树,查找的时间复杂度为O(logn)
- 每个节点的子节点数量可为0、1、2
- 如果有两个子节点,则其中一个子节点的值必须小于父节点,另一个子节点的值必须大于等于父节点
- 二叉树的查找算法先从根节点开始
- 检视该节点的值,如果正是所要找的值,正好
- 如果要找的值小于当前节点的值,则在该节点的左子树查找
- 如果要找的值大于当前节点的值,则在该节点的右子树查找
- 二叉树的删除算法
- 如果要删除的节点没有子节点,那直接删除掉它
- 如果要删除的节点有一个子节点,那删除掉它之后,还要将子节点填到被删除节点的位置上
- 如果要删除的节点有两个子节点,则将该节点替换成其后继节点。一个节点的后继节点,就是所有比被删除节点大的子节点中,最小的那个
- 如果后继节点带有右子节点,则在后继节点填补被删除节点以后,用此右子节点替代后继节点的父节点的左子节点。
- 前序遍历(深度优先遍历),输出顺序是根节点、左子树、右子树
- 中序遍历(深度优先遍历),输出顺序是左子树、根节点、右子树
- 后序遍历(深度优先遍历),输出顺序是左子树、右子树、根节点
- 层序遍历(广度优先遍历) 递归是实现中序遍历的有力工具
-
如果此节点有左子节点,则在左子节点上调用自己(traverse
-
访问此节点
-
如果此节点有右子节点,则在右子节点上调用自己(traverse
-
图:是一种善于处理关系型数据的数据结构,使用它可用轻松地表示数据之间是如何关联的。
- 有向图
- 无向图
- 广度优先搜索,O(V+E)--->O(N)
- 深度优先搜索
- 加权利图,解决最短路径问题,Dijkstra算法
def search(value, node):
if node is None or node.value == value
return node
elif value < node.value:
return search(value, node.leftChild)
else:
return search(value, node.rightChild)
- 二叉堆(优先队列)
数据结构一般都有以下4种操作:
- 读取:查看数据结构中某一位置上的数据。
- 查找:从数据结构中找出某给数据所在的位置。
- 插入:给数据结构增加一个数据值。
- 删除:从数据结构中移除一个数据值。
操作的速度,并不按时间计算,而是按步骤计算。操作的速度常被称为时间复杂度。
计算机之所以在读取数组中某个索引指向的值时,能直接跳到那个位置上,是因为它具备以下条件。
- 计算机可用一步就跳到任意一个内存地址上。(比如你知道大街123号在哪,就可以直奔过去。只不过需要点时间,但电脑很快)
- 数组本身会记有的一个格子的内存地址,因此,计算机知道这个数组的开头在哪里。
- 数组的索引从0算起。
集合:一种不允许元素重复的数据结构,在插入的时候很费时,因为需要遍历一遍看是否有重复的地方。(这里指的是使用数组作为集合的实现底层)
散列表的效率取决于以下因素:
- 要存多少数据
- 有多少可用的格子
- 用什么样的散列函数
使用散列表时所需要权衡的:既要避免冲突,又要节省空间 可使用计算机科学家研究出的黄金法则:每增加7个元素,就增加10个格子。 数据量与格子数的比值称为负载因子,理想的负载因子是0.7(7个元素/10个格子)
检查链表代码是否正确的边界条件有这样几个:
- 如果链表为空时,代码是否能正常工作?
- 如果链表只包含一个结点时,代码是否能正常工作?
- 如果链表只包含两个结点时,代码是否能正常工作?
- 代码逻辑在处理头结点和尾结点的时候,是否能正常工作?