{% include header.html %}
+ {% seo %}
{{ content }}
diff --git a/_layouts/post.html b/_layouts/post.html
index c1f9c45114..8535db8947 100755
--- a/_layouts/post.html
+++ b/_layouts/post.html
@@ -6,14 +6,14 @@  +{% if page.image %}
+
+{% if page.image %}
+  {% endif %}
{{ content }}
- Written on
+ {{ site.data.settings.post_date_prefix }}
{% assign d = page.date | date: "%-d" %}
{{ page.date | date: "%B" }}
{% case d %}
@@ -26,7 +26,7 @@
{% endif %}
{{ content }}
- Written on
+ {{ site.data.settings.post_date_prefix }}
{% assign d = page.date | date: "%-d" %}
{{ page.date | date: "%B" }}
{% case d %}
@@ -26,7 +26,7 @@
{% include related-posts.html %}
{% if site.data.settings.disqus.comments %}
+
+
+
+
{% include disqus.html %}
{% endif %}
diff --git a/_plugins/jekyll-crosspost-to-medium.rb b/_plugins/jekyll-crosspost-to-medium.rb
new file mode 100644
index 0000000000..11a272bfc6
--- /dev/null
+++ b/_plugins/jekyll-crosspost-to-medium.rb
@@ -0,0 +1,217 @@
+# By Aaron Gustafson, based on the work of Jeremy Keith
+# https://github.com/aarongustafson/jekyll-crosspost_to_medium
+# https://gist.github.com/adactio/c174a4a68498e30babfd
+# Licence : MIT
+#
+# This generator cross-posts entries to Medium. To work, this script requires
+# a MEDIUM_USER_ID environment variable and a MEDIUM_INTEGRATION_TOKEN.
+#
+# The generator will only pick up posts with the following front matter:
+#
+# `crosspost_to_medium: true`
+#
+# You can control crossposting globally by setting `enabled: true` under the
+# `jekyll-crosspost_to_medium` variable in your Jekyll configuration file.
+# Setting it to false will skip the processing loop entirely which can be
+# useful for local preview builds.
+
+require 'json'
+require 'net/http'
+require 'net/https'
+require 'uri'
+require 'date'
+
+module Jekyll
+ class MediumCrossPostGenerator < Generator
+ safe true
+ priority :low
+
+ def generate(site)
+ @site = site
+
+ @settings = @site.config['jekyll-crosspost_to_medium'] || {}
+ globally_enabled = if @settings.has_key? 'enabled' then @settings['enabled'] else true end
+ cache_dir = @settings['cache'] || @site.config['source'] + '/.jekyll-crosspost_to_medium'
+ backdate = if @settings.has_key? 'backdate' then @settings['backdate'] else true end
+ @crossposted_file = File.join(cache_dir, "medium_crossposted.yml")
+
+ if globally_enabled
+ # puts "Cross-posting enabled"
+ user_id = ENV['MEDIUM_USER_ID'] or false
+ token = ENV['MEDIUM_INTEGRATION_TOKEN'] or false
+
+ if ! user_id or ! token
+ raise ArgumentError, "MediumCrossPostGenerator: Environment variables not found"
+ return
+ end
+
+ if defined?(cache_dir)
+ FileUtils.mkdir_p(cache_dir)
+
+ if File.exists?(@crossposted_file)
+ crossposted = open(@crossposted_file) { |f| YAML.load(f) }
+ # convert from an array to a hash (upgrading older versions of this plugin)
+ if crossposted.kind_of?(Array)
+ new_crossposted = {}
+ crossposted.each do |url|
+ new_crossposted[url] = 'unknown'
+ end
+ crossposted = new_crossposted
+ end
+ # end upgrade
+ else
+ crossposted = {}
+ end
+
+ # If Jekyll 3.0, use hooks
+ if (Jekyll.const_defined? :Hooks)
+ Jekyll::Hooks.register :posts, :post_render do |post|
+ if ! post.published?
+ next
+ end
+
+ crosspost = post.data.include? 'crosspost_to_medium'
+ if ! crosspost or ! post.data['crosspost_to_medium']
+ next
+ end
+
+ content = post.content
+ url = "#{@site.config['url']}#{post.url}"
+ title = post.data['title']
+
+ published_at = backdate ? post.date : DateTime.now
+
+ crosspost_payload(crossposted, post, content, title, url, published_at)
+ end
+ else
+
+ # post Jekyll commit 0c0aea3
+ # https://github.com/jekyll/jekyll/commit/0c0aea3ad7d2605325d420a23d21729c5cf7cf88
+ if defined? site.find_converter_instance
+ markdown_converter = @site.find_converter_instance(Jekyll::Converters::Markdown)
+ # Prior to Jekyll commit 0c0aea3
+ else
+ markdown_converter = @site.getConverterImpl(Jekyll::Converters::Markdown)
+ end
+
+ @site.posts.each do |post|
+
+ if ! post.published?
+ next
+ end
+
+ crosspost = post.data.include? 'crosspost_to_medium'
+ if ! crosspost or ! post.data['crosspost_to_medium']
+ next
+ end
+
+ # Convert the content
+ content = markdown_converter.convert(post.content)
+ # Render any plugins
+ content = (Liquid::Template.parse content).render @site.site_payload
+
+ url = "#{@site.config['url']}#{post.url}"
+ title = post.title
+
+ published_at = backdate ? post.date : DateTime.now
+
+ crosspost_payload(crossposted, post, content, title, url, published_at)
+
+ end
+ end
+ end
+ end
+ end
+
+
+ def crosspost_payload(crossposted, post, content, title, url, published_at)
+ # Update any absolute URLs
+ # But don’t clobber protocol-less (i.e. "//") URLs
+ content = content.gsub /href=(["'])\/(?!\/)/, "href=\\1#{@site.config['url']}/"
+ content = content.gsub /src=(["'])\/(?!\/)/, "src=\\1#{@site.config['url']}/"
+ # puts content
+
+ # Save canonical URL
+ canonical_url = url
+
+ # Prepend the title and add a link back to originating site
+ content.prepend("
Deleted text should use `` and inserted text should use ``.
-- Superscript text uses `` and subscript text uses ``.
-
-Most of these elements are styled by browsers with few modifications on our part.
-
-### Heading
-
-Vivamus sagittis lacus vel augue rutrum faucibus dolor auctor. Duis mollis, est non commodo luctus, nisi erat porttitor ligula, eget lacinia odio sem nec elit. Morbi leo risus, porta ac consectetur ac, vestibulum at eros.
-
-### Code
-
-Cum sociis natoque penatibus et magnis dis `code element` montes, nascetur ridiculus mus.
-
-```js
-// Example can be run directly in your JavaScript console
-
-// Create a function that takes two arguments and returns the sum of those arguments
-var adder = new Function("a", "b", "return a + b");
-
-// Call the function
-adder(2, 6);
-// > 8
-```
-
-Aenean lacinia bibendum nulla sed consectetur. Etiam porta sem malesuada magna mollis euismod. Fusce dapibus, tellus ac cursus commodo, tortor mauris condimentum nibh, ut fermentum massa.
-
-### Lists
-
-Cum sociis natoque penatibus et magnis dis parturient montes, nascetur ridiculus mus. Aenean lacinia bibendum nulla sed consectetur. Etiam porta sem malesuada magna mollis euismod. Fusce dapibus, tellus ac cursus commodo, tortor mauris condimentum nibh, ut fermentum massa justo sit amet risus.
-
-* Praesent commodo cursus magna, vel scelerisque nisl consectetur et.
-* Donec id elit non mi porta gravida at eget metus.
-* Nulla vitae elit libero, a pharetra augue.
-
-Donec ullamcorper nulla non metus auctor fringilla. Nulla vitae elit libero, a pharetra augue.
-
-1. Vestibulum id ligula porta felis euismod semper.
-2. Cum sociis natoque penatibus et magnis dis parturient montes, nascetur ridiculus mus.
-3. Maecenas sed diam eget risus varius blandit sit amet non magna.
-
-Integer posuere erat a ante venenatis dapibus posuere velit aliquet. Morbi leo risus, porta ac consectetur ac, vestibulum at eros. Nullam quis risus eget urna mollis ornare vel eu leo.
-
-### Tables
-
-Aenean lacinia bibendum nulla sed consectetur. Lorem ipsum dolor sit amet, consectetur adipiscing elit.
-
-
-
-
-
-Nullam id dolor id nibh ultricies vehicula ut id elit. Sed posuere consectetur est at lobortis. Nullam quis risus eget urna mollis ornare vel eu leo.
-
-
-A variety of common markup showing how the theme styles them.
-
-### Blockquotes
-
-Single line blockquote:
-
-> Stay hungry. Stay foolish.
-
-Multi line blockquote with a cite reference:
-
-> People think focus means saying yes to the thing you've got to focus on. But that's not what it means at all. It means saying no to the hundred other good ideas that there are. You have to pick carefully. I'm actually as proud of the things we haven't done as the things I have done. Innovation is saying no to 1,000 things.
-
-Steve Jobs --- Apple Worldwide Developers' Conference, 1997
-{: .small}
-
-### Tables
-
-| Header1 | Header2 | Header3 |
-|:--------|:-------:|--------:|
-| cell1 | cell2 | cell3 |
-| cell4 | cell5 | cell6 |
-|-----------------------------|
-| cell1 | cell2 | cell3 |
-| cell4 | cell5 | cell6 |
-|=============================|
-| Foot1 | Foot2 | Foot3 |
-
-### Unordered Lists (Nested)
-
- * List item one
- * List item one
- * List item one
- * List item two
- * List item three
- * List item four
- * List item two
- * List item three
- * List item four
- * List item two
- * List item three
- * List item four
-
-### Ordered List (Nested)
-
- 1. List item one
- 1. List item one
- 1. List item one
- 2. List item two
- 3. List item three
- 4. List item four
- 2. List item two
- 3. List item three
- 4. List item four
- 2. List item two
- 3. List item three
- 4. List item four
-
-### HTML Tags
-
-### Address Tag
-
-
- 1 Infinite Loop
Cupertino, CA 95014
United States - - -### Anchor Tag (aka. Link) - -This is an example of a [link](http://apple.com "Apple"). - -### Abbreviation Tag - -The abbreviation CSS stands for "Cascading Style Sheets". - -*[CSS]: Cascading Style Sheets - -### Cite Tag - -"Code is poetry." ---Automattic - -### Code Tag - -You will learn later on in these tests that `word-wrap: break-word;` will be your best friend. - -### Strike Tag - -This tag will let youstrikeout text.
-
-### Emphasize Tag
-
-The emphasize tag should _italicize_ text.
-
-### Insert Tag
-
-This tag should denote inserted text.
-
-### Keyboard Tag
-
-This scarcely known tag emulates keyboard text, which is usually styled like the `
{{ page.title }}
-{% if page.image.feature %} -
+{% if page.image %}
+
{% endif %}
{{ content }}
- Written on
+ {{ site.data.settings.post_date_prefix }}
{% assign d = page.date | date: "%-d" %}
{{ page.date | date: "%B" }}
{% case d %}
@@ -26,7 +26,7 @@ {% if page.author %} {{ page.author }} {% else %} - {{ site.data.authors.primary.name }} + {{ site.author }} {% endif %}
@@ -35,5 +35,21 @@
{% include related-posts.html %}
{% if site.data.settings.disqus.comments %}
+
+
+
+
{% include disqus.html %}
{% endif %}
diff --git a/_plugins/jekyll-crosspost-to-medium.rb b/_plugins/jekyll-crosspost-to-medium.rb
new file mode 100644
index 0000000000..11a272bfc6
--- /dev/null
+++ b/_plugins/jekyll-crosspost-to-medium.rb
@@ -0,0 +1,217 @@
+# By Aaron Gustafson, based on the work of Jeremy Keith
+# https://github.com/aarongustafson/jekyll-crosspost_to_medium
+# https://gist.github.com/adactio/c174a4a68498e30babfd
+# Licence : MIT
+#
+# This generator cross-posts entries to Medium. To work, this script requires
+# a MEDIUM_USER_ID environment variable and a MEDIUM_INTEGRATION_TOKEN.
+#
+# The generator will only pick up posts with the following front matter:
+#
+# `crosspost_to_medium: true`
+#
+# You can control crossposting globally by setting `enabled: true` under the
+# `jekyll-crosspost_to_medium` variable in your Jekyll configuration file.
+# Setting it to false will skip the processing loop entirely which can be
+# useful for local preview builds.
+
+require 'json'
+require 'net/http'
+require 'net/https'
+require 'uri'
+require 'date'
+
+module Jekyll
+ class MediumCrossPostGenerator < Generator
+ safe true
+ priority :low
+
+ def generate(site)
+ @site = site
+
+ @settings = @site.config['jekyll-crosspost_to_medium'] || {}
+ globally_enabled = if @settings.has_key? 'enabled' then @settings['enabled'] else true end
+ cache_dir = @settings['cache'] || @site.config['source'] + '/.jekyll-crosspost_to_medium'
+ backdate = if @settings.has_key? 'backdate' then @settings['backdate'] else true end
+ @crossposted_file = File.join(cache_dir, "medium_crossposted.yml")
+
+ if globally_enabled
+ # puts "Cross-posting enabled"
+ user_id = ENV['MEDIUM_USER_ID'] or false
+ token = ENV['MEDIUM_INTEGRATION_TOKEN'] or false
+
+ if ! user_id or ! token
+ raise ArgumentError, "MediumCrossPostGenerator: Environment variables not found"
+ return
+ end
+
+ if defined?(cache_dir)
+ FileUtils.mkdir_p(cache_dir)
+
+ if File.exists?(@crossposted_file)
+ crossposted = open(@crossposted_file) { |f| YAML.load(f) }
+ # convert from an array to a hash (upgrading older versions of this plugin)
+ if crossposted.kind_of?(Array)
+ new_crossposted = {}
+ crossposted.each do |url|
+ new_crossposted[url] = 'unknown'
+ end
+ crossposted = new_crossposted
+ end
+ # end upgrade
+ else
+ crossposted = {}
+ end
+
+ # If Jekyll 3.0, use hooks
+ if (Jekyll.const_defined? :Hooks)
+ Jekyll::Hooks.register :posts, :post_render do |post|
+ if ! post.published?
+ next
+ end
+
+ crosspost = post.data.include? 'crosspost_to_medium'
+ if ! crosspost or ! post.data['crosspost_to_medium']
+ next
+ end
+
+ content = post.content
+ url = "#{@site.config['url']}#{post.url}"
+ title = post.data['title']
+
+ published_at = backdate ? post.date : DateTime.now
+
+ crosspost_payload(crossposted, post, content, title, url, published_at)
+ end
+ else
+
+ # post Jekyll commit 0c0aea3
+ # https://github.com/jekyll/jekyll/commit/0c0aea3ad7d2605325d420a23d21729c5cf7cf88
+ if defined? site.find_converter_instance
+ markdown_converter = @site.find_converter_instance(Jekyll::Converters::Markdown)
+ # Prior to Jekyll commit 0c0aea3
+ else
+ markdown_converter = @site.getConverterImpl(Jekyll::Converters::Markdown)
+ end
+
+ @site.posts.each do |post|
+
+ if ! post.published?
+ next
+ end
+
+ crosspost = post.data.include? 'crosspost_to_medium'
+ if ! crosspost or ! post.data['crosspost_to_medium']
+ next
+ end
+
+ # Convert the content
+ content = markdown_converter.convert(post.content)
+ # Render any plugins
+ content = (Liquid::Template.parse content).render @site.site_payload
+
+ url = "#{@site.config['url']}#{post.url}"
+ title = post.title
+
+ published_at = backdate ? post.date : DateTime.now
+
+ crosspost_payload(crossposted, post, content, title, url, published_at)
+
+ end
+ end
+ end
+ end
+ end
+
+
+ def crosspost_payload(crossposted, post, content, title, url, published_at)
+ # Update any absolute URLs
+ # But don’t clobber protocol-less (i.e. "//") URLs
+ content = content.gsub /href=(["'])\/(?!\/)/, "href=\\1#{@site.config['url']}/"
+ content = content.gsub /src=(["'])\/(?!\/)/, "src=\\1#{@site.config['url']}/"
+ # puts content
+
+ # Save canonical URL
+ canonical_url = url
+
+ # Prepend the title and add a link back to originating site
+ content.prepend("#{title}
")
+ # Append a canonical link and text
+ # TODO Accept a position option, e.g., top, bottom.
+ #
+ # Use the user's config if it exists
+ if @settings['text']
+ canonical_text = "#{@settings['text']}"
+ canonical_text = canonical_text.gsub /{{ url }}/, canonical_url
+ # Otherwise, use boilerplate
+ else
+ canonical_text = "
This article was originally posted on my own site.
" + end + content << canonical_text + + # Strip domain name from the URL we check against + url = url.sub(/^#{@site.config['url']}?/,'') + + # coerce tage to an array + tags = post.data['tags'] + if tags.kind_of? String + tags = tags.split(',') + end + + # Only cross-post if content has not already been cross-posted + if url and ! crossposted.has_key? url + payload = { + 'title' => title, + 'contentFormat' => "html", + 'content' => content, + 'tags' => tags, + 'publishStatus' => @settings['status'] || "public", + 'publishedAt' => published_at.iso8601, + 'license' => @settings['license'] || "all-rights-reserved", + 'canonicalUrl' => canonical_url + } + + if medium_url = crosspost_to_medium(payload) + crossposted[url] = medium_url + # Update cache + File.open(@crossposted_file, 'w') { |f| YAML.dump(crossposted, f) } + end + end + end + + + def crosspost_to_medium(payload) + user_id = ENV['MEDIUM_USER_ID'] or false + token = ENV['MEDIUM_INTEGRATION_TOKEN'] or false + medium_api = URI.parse("https://api.medium.com/v1/users/#{user_id}/posts") + + # Build the connection + https = Net::HTTP.new(medium_api.host, medium_api.port) + https.use_ssl = true + request = Net::HTTP::Post.new(medium_api.path) + + # Set the headers + request['Authorization'] = "Bearer #{token}" + request['Content-Type'] = "application/json" + request['Accept'] = "application/json" + request['Accept-Charset'] = "utf-8" + + # Set the payload + request.body = JSON.generate(payload) + + # Post it + response = https.request(request) + + if response.code == '201' + medium_response = JSON.parse(response.body) + puts "Posted '#{payload['title']}' to Medium as #{payload['publishStatus']} (#{medium_response['data']['url']})" + return medium_response['data']['url'] + else + puts "Attempted to post '#{payload['title']}' to Medium. They responded #{response.body}" + return false + end + end + + end + +end diff --git a/_posts/2013-01-01-post-content-styles.md b/_posts/2013-01-01-post-content-styles.md deleted file mode 100755 index 6768a96afa..0000000000 --- a/_posts/2013-01-01-post-content-styles.md +++ /dev/null @@ -1,109 +0,0 @@ ---- -layout: post -title: "Post Content Styles" -author: "Paul Le" -categories: journal -tags: [documentation,sample] -image: - feature: cards.jpg - credit: - creditlink: ---- - -Lorem ipsum dolor sit amet, consectetur adipiscing elit. Fusce bibendum neque eget nunc mattis eu sollicitudin enim tincidunt. Vestibulum lacus tortor, ultricies id dignissim ac, bibendum in velit. - -## Some great heading (h2) - -Proin convallis mi ac felis pharetra aliquam. Curabitur dignissim accumsan rutrum. In arcu magna, aliquet vel pretium et, molestie et arcu. - -Mauris lobortis nulla et felis ullamcorper bibendum. Phasellus et hendrerit mauris. Proin eget nibh a massa vestibulum pretium. Suspendisse eu nisl a ante aliquet bibendum quis a nunc. Praesent varius interdum vehicula. Aenean risus libero, placerat at vestibulum eget, ultricies eu enim. Praesent nulla tortor, malesuada adipiscing adipiscing sollicitudin, adipiscing eget est. - -## Another great heading (h2) - -Lorem ipsum dolor sit amet, consectetur adipiscing elit. Fusce bibendum neque eget nunc mattis eu sollicitudin enim tincidunt. Vestibulum lacus tortor, ultricies id dignissim ac, bibendum in velit. - -### Some great subheading (h3) - -Proin convallis mi ac felis pharetra aliquam. Curabitur dignissim accumsan rutrum. In arcu magna, aliquet vel pretium et, molestie et arcu. Mauris lobortis nulla et felis ullamcorper bibendum. - -Phasellus et hendrerit mauris. Proin eget nibh a massa vestibulum pretium. Suspendisse eu nisl a ante aliquet bibendum quis a nunc. - -### Some great subheading (h3) - -Praesent varius interdum vehicula. Aenean risus libero, placerat at vestibulum eget, ultricies eu enim. Praesent nulla tortor, malesuada adipiscing adipiscing sollicitudin, adipiscing eget est. - -> This quote will change your life. It will reveal the secrets of the universe, and all the wonders of humanity. Don't misuse it. - -Lorem ipsum dolor sit amet, consectetur adipiscing elit. Fusce bibendum neque eget nunc mattis eu sollicitudin enim tincidunt. - -### Some great subheading (h3) - -Vestibulum lacus tortor, ultricies id dignissim ac, bibendum in velit. Proin convallis mi ac felis pharetra aliquam. Curabitur dignissim accumsan rutrum. - -```html - - - - -Hello, World!
- - -``` - - -In arcu magna, aliquet vel pretium et, molestie et arcu. Mauris lobortis nulla et felis ullamcorper bibendum. Phasellus et hendrerit mauris. - -#### You might want a sub-subheading (h4) - -In arcu magna, aliquet vel pretium et, molestie et arcu. Mauris lobortis nulla et felis ullamcorper bibendum. Phasellus et hendrerit mauris. - -In arcu magna, aliquet vel pretium et, molestie et arcu. Mauris lobortis nulla et felis ullamcorper bibendum. Phasellus et hendrerit mauris. - -#### But it's probably overkill (h4) - -In arcu magna, aliquet vel pretium et, molestie et arcu. Mauris lobortis nulla et felis ullamcorper bibendum. Phasellus et hendrerit mauris. - -### Oh hai, an unordered list!! - -In arcu magna, aliquet vel pretium et, molestie et arcu. Mauris lobortis nulla et felis ullamcorper bibendum. Phasellus et hendrerit mauris. - -- First item, yo -- Second item, dawg -- Third item, what what?! -- Fourth item, fo sheezy my neezy - -### Oh hai, an ordered list!! - -In arcu magna, aliquet vel pretium et, molestie et arcu. Mauris lobortis nulla et felis ullamcorper bibendum. Phasellus et hendrerit mauris. - -1. First item, yo -2. Second item, dawg -3. Third item, what what?! -4. Fourth item, fo sheezy my neezy - - - -## Headings are cool! (h2) - -Proin eget nibh a massa vestibulum pretium. Suspendisse eu nisl a ante aliquet bibendum quis a nunc. Praesent varius interdum vehicula. Aenean risus libero, placerat at vestibulum eget, ultricies eu enim. Praesent nulla tortor, malesuada adipiscing adipiscing sollicitudin, adipiscing eget est. - -Praesent nulla tortor, malesuada adipiscing adipiscing sollicitudin, adipiscing eget est. - -Proin eget nibh a massa vestibulum pretium. Suspendisse eu nisl a ante aliquet bibendum quis a nunc. - -### Tables - -Title 1 | Title 2 | Title 3 | Title 4 ---------------------- | --------------------- | --------------------- | --------------------- -lorem | lorem ipsum | lorem ipsum dolor | lorem ipsum dolor sit -lorem ipsum dolor sit | lorem ipsum dolor sit | lorem ipsum dolor sit | lorem ipsum dolor sit -lorem ipsum dolor sit | lorem ipsum dolor sit | lorem ipsum dolor sit | lorem ipsum dolor sit -lorem ipsum dolor sit | lorem ipsum dolor sit | lorem ipsum dolor sit | lorem ipsum dolor sit - - -Title 1 | Title 2 | Title 3 | Title 4 ---- | --- | --- | --- -lorem | lorem ipsum | lorem ipsum dolor | lorem ipsum dolor sit -lorem ipsum dolor sit amet | lorem ipsum dolor sit amet consectetur | lorem ipsum dolor sit amet | lorem ipsum dolor sit -lorem ipsum dolor | lorem ipsum | lorem | lorem ipsum -lorem ipsum dolor | lorem ipsum dolor sit | lorem ipsum dolor sit amet | lorem ipsum dolor sit amet consectetur diff --git a/_posts/2015-04-04-About-the-author.md b/_posts/2015-04-04-About-the-author.md deleted file mode 100755 index 62e744b9d0..0000000000 --- a/_posts/2015-04-04-About-the-author.md +++ /dev/null @@ -1,19 +0,0 @@ ---- -layout: post -title: "About the Author" -author: "Paul Le" -categories: journal -tags: [documentation,sample] -image: - feature: cutting.jpg - credit: - creditlink: ---- - -Hi there! I'm Paul. I’m a physics major turned programmer. Ever since I first learned how to program while taking a scientific computing for physics course, I have pursued programming as a passion, and as a career. Below is a compilation of some of my favourite things that I have built over the years. You may find everything else on my Github and Code Pen profiles. - -### Jekyll Website Theme for Blogging - -Millennial is a minimalist Jekyll blog theme that I built from scratch. The purpose of this theme is to provide a simple, clean, content-focused publishing platform for a publication or blog. This theme is currently being used by about three dozen people, with this number growing every day. - -Feel free to check out the demo, where you’ll also find instructions on how to use install and use the theme. diff --git a/_posts/2015-04-04-about-the-author.md b/_posts/2015-04-04-about-the-author.md deleted file mode 100755 index 62e744b9d0..0000000000 --- a/_posts/2015-04-04-about-the-author.md +++ /dev/null @@ -1,19 +0,0 @@ ---- -layout: post -title: "About the Author" -author: "Paul Le" -categories: journal -tags: [documentation,sample] -image: - feature: cutting.jpg - credit: - creditlink: ---- - -Hi there! I'm Paul. I’m a physics major turned programmer. Ever since I first learned how to program while taking a scientific computing for physics course, I have pursued programming as a passion, and as a career. Below is a compilation of some of my favourite things that I have built over the years. You may find everything else on my Github and Code Pen profiles. - -### Jekyll Website Theme for Blogging - -Millennial is a minimalist Jekyll blog theme that I built from scratch. The purpose of this theme is to provide a simple, clean, content-focused publishing platform for a publication or blog. This theme is currently being used by about three dozen people, with this number growing every day. - -Feel free to check out the demo, where you’ll also find instructions on how to use install and use the theme. diff --git a/_posts/2015-09-09-Text-Formatting.md b/_posts/2015-09-09-Text-Formatting.md deleted file mode 100755 index 8a8b6641ce..0000000000 --- a/_posts/2015-09-09-Text-Formatting.md +++ /dev/null @@ -1,309 +0,0 @@ ---- -layout: post -title: "Text Formatting" -author: "Paul Le" -categories: journal -tags: [documentation,sample] -image: - feature: spools.jpg - credit: - creditlink: ---- - -## Introduction - -Howdy! This is an example blog post that shows several types of HTML content supported in this theme. - -As always, Jekyll offers support for GitHub Flavored Markdown, which allows you to format your posts using the [Markdown syntax](https://guides.github.com/features/mastering-markdown/). Examples of these text formatting features can be seen below. You can find this post in the `_posts` directory. - -# Heading One - -## Heading Two - -### Heading Three - -#### Heading Four - -##### Heading Five - -###### Heading Six - -Cum sociis natoque penatibus et magnis dis parturient montes, nascetur ridiculus mus. *Aenean eu leo quam.* Pellentesque ornare sem lacinia quam venenatis vestibulum. Sed posuere consectetur est at lobortis. Cras mattis consectetur purus sit amet fermentum. - -> Curabitur blandit tempus porttitor. Nullam quis risus eget urna mollis ornare vel eu leo. Nullam id dolor id nibh ultricies vehicula ut id elit. - -Etiam porta **sem malesuada magna** mollis euismod. Cras mattis consectetur purus sit amet fermentum. Aenean lacinia bibendum nulla sed consectetur. - -### Inline HTML elements - -HTML defines a long list of available inline tags, a complete list of which can be found on the [Mozilla Developer Network](https://developer.mozilla.org/en-US/docs/Web/HTML/Element). - -- **To bold text**, use ``. -- *To italicize text*, use ``. -- Abbreviations, like HTML should use ``, with an optional `title` attribute for the full phrase. -- Citations, like — Mark otto, should use ``. --| Name | -Upvotes | -Downvotes | -
|---|---|---|
| Totals | -21 | -23 | -
| Alice | -10 | -11 | -
| Bob | -4 | -3 | -
| Charlie | -7 | -9 | -
Cupertino, CA 95014
United States - - -### Anchor Tag (aka. Link) - -This is an example of a [link](http://apple.com "Apple"). - -### Abbreviation Tag - -The abbreviation CSS stands for "Cascading Style Sheets". - -*[CSS]: Cascading Style Sheets - -### Cite Tag - -"Code is poetry." ---Automattic - -### Code Tag - -You will learn later on in these tests that `word-wrap: break-word;` will be your best friend. - -### Strike Tag - -This tag will let you
` tag.
-
-### Preformatted Tag
-
-This tag styles large blocks of code.
-
-
-.post-title {
- margin: 0 0 5px;
- font-weight: bold;
- font-size: 38px;
- line-height: 1.2;
- and here's a line of some really, really, really, really long text, just to see how the PRE tag handles it and to find out how it overflows;
-}
-
-
-### Quote Tag
-
-Developers, developers, developers…
–Steve Ballmer
-
-### Strong Tag
-
-This tag shows **bold text**.
-
-### Subscript Tag
-
-Getting our science styling on with H2O, which should push the "2" down.
-
-### Superscript Tag
-
-Still sticking with science and Isaac Newton's E = MC2, which should lift the 2 up.
-
-### Variable Tag
-
-This allows you to denote variables.
-
-### MathJax Example
-
-The [Schrödinger equation](https://en.wikipedia.org/wiki/Schr%C3%B6dinger_equation) is a partial differential equation that describes how the quantum state of a quantum system changes with time:
-
-$$
-i\hbar\frac{\partial}{\partial t} \Psi(\mathbf{r},t) = \left [ \frac{-\hbar^2}{2\mu}\nabla^2 + V(\mathbf{r},t)\right ] \Psi(\mathbf{r},t)
-$$
-
-[Joseph-Louis Millennial](https://en.wikipedia.org/wiki/Joseph-Louis_Millennial) was an Italian mathematician and astronomer who was responsible for the formulation of Lagrangian mechanics, which is a reformulation of Newtonian mechanics.
-
-$$ \frac{\mathrm{d}}{\mathrm{d}t} \left ( \frac {\partial L}{\partial \dot{q}_j} \right ) = \frac {\partial L}{\partial q_j} $$
-
-### Code Highlighting
-
-You can find the full list of supported programming languages [here](https://github.com/jneen/rouge/wiki/List-of-supported-languages-and-lexers).
-
-```css
-#container {
- float: left;
- margin: 0 -240px 0 0;
- width: 100%;
-}
-```
-
-```ruby
-def print_hi(name)
- puts "Hi, #{name}"
-end
-print_hi('Tom')
-#=> prints 'Hi, Tom' to STDOUT.
-```
-
-Another option is to embed your code through [Gist](https://en.support.wordpress.com/gist/).
-
-### Embedding
-
-Plenty of social media sites offer the option of embedding certain parts of their site on your own site:
-
-
-
-New Collection
-
-The Baton Rouge gunman was a Marine who served in Iraq https://t.co/RHVAKTN2OV pic.twitter.com/sjfJb43GYs
— The New York Times (@nytimes) July 18, 2016
-
-
-
-
-
-National Park Tweets
diff --git a/_posts/2015-09-09-text-formatting.md b/_posts/2015-09-09-text-formatting.md
deleted file mode 100755
index 8a8b6641ce..0000000000
--- a/_posts/2015-09-09-text-formatting.md
+++ /dev/null
@@ -1,309 +0,0 @@
----
-layout: post
-title: "Text Formatting"
-author: "Paul Le"
-categories: journal
-tags: [documentation,sample]
-image:
- feature: spools.jpg
- credit:
- creditlink:
----
-
-## Introduction
-
-Howdy! This is an example blog post that shows several types of HTML content supported in this theme.
-
-As always, Jekyll offers support for GitHub Flavored Markdown, which allows you to format your posts using the [Markdown syntax](https://guides.github.com/features/mastering-markdown/). Examples of these text formatting features can be seen below. You can find this post in the `_posts` directory.
-
-# Heading One
-
-## Heading Two
-
-### Heading Three
-
-#### Heading Four
-
-##### Heading Five
-
-###### Heading Six
-
-Cum sociis natoque penatibus et magnis dis parturient montes, nascetur ridiculus mus. *Aenean eu leo quam.* Pellentesque ornare sem lacinia quam venenatis vestibulum. Sed posuere consectetur est at lobortis. Cras mattis consectetur purus sit amet fermentum.
-
-> Curabitur blandit tempus porttitor. Nullam quis risus eget urna mollis ornare vel eu leo. Nullam id dolor id nibh ultricies vehicula ut id elit.
-
-Etiam porta **sem malesuada magna** mollis euismod. Cras mattis consectetur purus sit amet fermentum. Aenean lacinia bibendum nulla sed consectetur.
-
-### Inline HTML elements
-
-HTML defines a long list of available inline tags, a complete list of which can be found on the [Mozilla Developer Network](https://developer.mozilla.org/en-US/docs/Web/HTML/Element).
-
-- **To bold text**, use ``.
-- *To italicize text*, use ``.
-- Abbreviations, like HTML should use ``, with an optional `title` attribute for the full phrase.
-- Citations, like — Mark otto, should use ``.
-- Deleted text should use `` and inserted text should use ``.
-- Superscript text uses `` and subscript text uses ``.
-
-Most of these elements are styled by browsers with few modifications on our part.
-
-### Heading
-
-Vivamus sagittis lacus vel augue rutrum faucibus dolor auctor. Duis mollis, est non commodo luctus, nisi erat porttitor ligula, eget lacinia odio sem nec elit. Morbi leo risus, porta ac consectetur ac, vestibulum at eros.
-
-### Code
-
-Cum sociis natoque penatibus et magnis dis `code element` montes, nascetur ridiculus mus.
-
-```js
-// Example can be run directly in your JavaScript console
-
-// Create a function that takes two arguments and returns the sum of those arguments
-var adder = new Function("a", "b", "return a + b");
-
-// Call the function
-adder(2, 6);
-// > 8
-```
-
-Aenean lacinia bibendum nulla sed consectetur. Etiam porta sem malesuada magna mollis euismod. Fusce dapibus, tellus ac cursus commodo, tortor mauris condimentum nibh, ut fermentum massa.
-
-### Lists
-
-Cum sociis natoque penatibus et magnis dis parturient montes, nascetur ridiculus mus. Aenean lacinia bibendum nulla sed consectetur. Etiam porta sem malesuada magna mollis euismod. Fusce dapibus, tellus ac cursus commodo, tortor mauris condimentum nibh, ut fermentum massa justo sit amet risus.
-
-* Praesent commodo cursus magna, vel scelerisque nisl consectetur et.
-* Donec id elit non mi porta gravida at eget metus.
-* Nulla vitae elit libero, a pharetra augue.
-
-Donec ullamcorper nulla non metus auctor fringilla. Nulla vitae elit libero, a pharetra augue.
-
-1. Vestibulum id ligula porta felis euismod semper.
-2. Cum sociis natoque penatibus et magnis dis parturient montes, nascetur ridiculus mus.
-3. Maecenas sed diam eget risus varius blandit sit amet non magna.
-
-Integer posuere erat a ante venenatis dapibus posuere velit aliquet. Morbi leo risus, porta ac consectetur ac, vestibulum at eros. Nullam quis risus eget urna mollis ornare vel eu leo.
-
-### Tables
-
-Aenean lacinia bibendum nulla sed consectetur. Lorem ipsum dolor sit amet, consectetur adipiscing elit.
-
-
-
-
- Name
- Upvotes
- Downvotes
-
-
-
-
- Totals
- 21
- 23
-
-
-
-
- Alice
- 10
- 11
-
-
- Bob
- 4
- 3
-
-
- Charlie
- 7
- 9
-
-
-
-
-Nullam id dolor id nibh ultricies vehicula ut id elit. Sed posuere consectetur est at lobortis. Nullam quis risus eget urna mollis ornare vel eu leo.
-
-
-A variety of common markup showing how the theme styles them.
-
-### Blockquotes
-
-Single line blockquote:
-
-> Stay hungry. Stay foolish.
-
-Multi line blockquote with a cite reference:
-
-> People think focus means saying yes to the thing you've got to focus on. But that's not what it means at all. It means saying no to the hundred other good ideas that there are. You have to pick carefully. I'm actually as proud of the things we haven't done as the things I have done. Innovation is saying no to 1,000 things.
-
-Steve Jobs --- Apple Worldwide Developers' Conference, 1997
-{: .small}
-
-### Tables
-
-| Header1 | Header2 | Header3 |
-|:--------|:-------:|--------:|
-| cell1 | cell2 | cell3 |
-| cell4 | cell5 | cell6 |
-|-----------------------------|
-| cell1 | cell2 | cell3 |
-| cell4 | cell5 | cell6 |
-|=============================|
-| Foot1 | Foot2 | Foot3 |
-
-### Unordered Lists (Nested)
-
- * List item one
- * List item one
- * List item one
- * List item two
- * List item three
- * List item four
- * List item two
- * List item three
- * List item four
- * List item two
- * List item three
- * List item four
-
-### Ordered List (Nested)
-
- 1. List item one
- 1. List item one
- 1. List item one
- 2. List item two
- 3. List item three
- 4. List item four
- 2. List item two
- 3. List item three
- 4. List item four
- 2. List item two
- 3. List item three
- 4. List item four
-
-### HTML Tags
-
-### Address Tag
-
-
- 1 Infinite Loop
Cupertino, CA 95014
United States
-
-
-### Anchor Tag (aka. Link)
-
-This is an example of a [link](http://apple.com "Apple").
-
-### Abbreviation Tag
-
-The abbreviation CSS stands for "Cascading Style Sheets".
-
-*[CSS]: Cascading Style Sheets
-
-### Cite Tag
-
-"Code is poetry." ---Automattic
-
-### Code Tag
-
-You will learn later on in these tests that `word-wrap: break-word;` will be your best friend.
-
-### Strike Tag
-
-This tag will let you strikeout text.
-
-### Emphasize Tag
-
-The emphasize tag should _italicize_ text.
-
-### Insert Tag
-
-This tag should denote inserted text.
-
-### Keyboard Tag
-
-This scarcely known tag emulates keyboard text, which is usually styled like the `` tag.
-
-### Preformatted Tag
-
-This tag styles large blocks of code.
-
-
-.post-title {
- margin: 0 0 5px;
- font-weight: bold;
- font-size: 38px;
- line-height: 1.2;
- and here's a line of some really, really, really, really long text, just to see how the PRE tag handles it and to find out how it overflows;
-}
-
-
-### Quote Tag
-
-Developers, developers, developers…
–Steve Ballmer
-
-### Strong Tag
-
-This tag shows **bold text**.
-
-### Subscript Tag
-
-Getting our science styling on with H2O, which should push the "2" down.
-
-### Superscript Tag
-
-Still sticking with science and Isaac Newton's E = MC2, which should lift the 2 up.
-
-### Variable Tag
-
-This allows you to denote variables.
-
-### MathJax Example
-
-The [Schrödinger equation](https://en.wikipedia.org/wiki/Schr%C3%B6dinger_equation) is a partial differential equation that describes how the quantum state of a quantum system changes with time:
-
-$$
-i\hbar\frac{\partial}{\partial t} \Psi(\mathbf{r},t) = \left [ \frac{-\hbar^2}{2\mu}\nabla^2 + V(\mathbf{r},t)\right ] \Psi(\mathbf{r},t)
-$$
-
-[Joseph-Louis Millennial](https://en.wikipedia.org/wiki/Joseph-Louis_Millennial) was an Italian mathematician and astronomer who was responsible for the formulation of Lagrangian mechanics, which is a reformulation of Newtonian mechanics.
-
-$$ \frac{\mathrm{d}}{\mathrm{d}t} \left ( \frac {\partial L}{\partial \dot{q}_j} \right ) = \frac {\partial L}{\partial q_j} $$
-
-### Code Highlighting
-
-You can find the full list of supported programming languages [here](https://github.com/jneen/rouge/wiki/List-of-supported-languages-and-lexers).
-
-```css
-#container {
- float: left;
- margin: 0 -240px 0 0;
- width: 100%;
-}
-```
-
-```ruby
-def print_hi(name)
- puts "Hi, #{name}"
-end
-print_hi('Tom')
-#=> prints 'Hi, Tom' to STDOUT.
-```
-
-Another option is to embed your code through [Gist](https://en.support.wordpress.com/gist/).
-
-### Embedding
-
-Plenty of social media sites offer the option of embedding certain parts of their site on your own site:
-
-
-
-New Collection
-
-The Baton Rouge gunman was a Marine who served in Iraq https://t.co/RHVAKTN2OV pic.twitter.com/sjfJb43GYs
— The New York Times (@nytimes) July 18, 2016
-
-
-
-
-
-National Park Tweets
diff --git a/_posts/2015-10-10-getting-started.md b/_posts/2015-10-10-getting-started.md
deleted file mode 100755
index 4779fbd732..0000000000
--- a/_posts/2015-10-10-getting-started.md
+++ /dev/null
@@ -1,189 +0,0 @@
----
-layout: post
-title: "Getting Started"
-author: "Paul Le"
-categories: journal
-tags: [documentation,sample]
-image:
- feature: forest.jpg
- credit:
- creditlink:
----
-
-# Lagrange
-
-Lagrange is a minimalist Jekyll theme for running a personal blog or site for free through [Github Pages](https://pages.github.com/), or on your own server. Everything that you will ever need to know about this Jekyll theme is included in the README below, which you can also find in [the demo site](https://lenpaul.github.io/Lagrange/).
-
-
-
-## Table of Contents
-
-1. [Introduction](#introduction)
- 1. [What is Jekyll](#what-is-jekyll)
- 2. [Never Used Jeykll Before?](#never-used-jekyll-before)
-2. [Installation](#installation)
- 1. [GitHub Pages Installation](#github-pages-installation)
- 2. [Local Installation](#local-installation)
- 3. [Directory Structure](#directory-structure)
- 4. [Starting From Scratch](#starting-from-scratch)
-3. [Configuration](#configuration)
- 1. [Site Variables](#site-variables)
- 2. [Adding Menu Pages](#adding-menu-pages)
- 3. [Posts](#posts)
- 4. [Layouts](#layouts)
- 5. [YAML Front Block Matter](#yaml-front-block-matter)
-4. [Features](#features)
- 1. [Design Considerations](#design-considerations)
- 2. [Disqus](#disqus)
- 3. [Google Analytics](#google-analytics)
- 4. [RSS Feeds](#rss-feeds)
- 5. [Social Media Icons](#social-media-icons)
-5. [Everything Else](#everything-else)
-6. [Credits](#credits)
-7. [License](#license)
-
-## Introduction
-
-Lagrange is a Jekyll theme that was built to be 100% compatible with [GitHub Pages](https://pages.github.com/). If you are unfamiliar with GitHub Pages, you can check out [their documentation](https://help.github.com/categories/github-pages-basics/) for more information. [Jonathan McGlone's guide](http://jmcglone.com/guides/github-pages/) on creating and hosting a personal site on GitHub is also a good resource.
-
-### What is Jekyll?
-
-Jekyll is a simple, blog-aware, static site generator for personal, project, or organization sites. Basically, Jekyll takes your page content along with template files and produces a complete website. For more information, visit the [official Jekyll site](https://jekyllrb.com/docs/home/) for their documentation.
-
-### Never Used Jekyll Before?
-
-The beauty of hosting your website on GitHub is that you don't have to actually have Jekyll installed on your computer. Everything can be done through the GitHub code editor, with minimal knowledge of how to use Jekyll or the command line. All you have to do is add your posts to the `_posts` directory and edit the `_config.yml` file to change the site settings. With some rudimentary knowledge of HTML and CSS, you can even modify the site to your liking.
-
-This can all be done through the GitHub code editor, which acts like a content management system (CMS).
-
-## Installation
-
-### GitHub Pages Installation
-
-To start using Jekyll right away using GitHub Pages, [fork the Lagrange repository on GitHub](https://github.com/LeNPaul/Lagrange/fork). From there, you can rename your repository to 'USERNAME.github.io', where 'USERNAME' is your GitHub username, and edit the `settings.yml` file in the `_data` folder to your liking. Ensure that you have a branch named `gh-pages`. Your website should be ready immediately at 'http://USERNAME.github.io'.
-
-Head over to the `_posts` directory to view all the posts that are currently on the website, and to see examples of what post files generally look like. You can simply just duplicate the template post and start adding your own content.
-
-### Local Installation
-
-For a full local installation of Lagrange, [download your own copy of Lagrange](https://github.com/LeNPaul/Lagrange/archive/gh-pages.zip) and unzip it into it's own directory. From there, open up your favorite command line tool, and enter `jekyll serve`. Your site should be up and running locally at [http://localhost:4000](http://localhost:4000).
-
-### Directory Structure
-
-If you are familiar with Jekyll, then the Lagrange directory structure shouldn't be too difficult to navigate. The following some highlights of the differences you might notice between the default directory structure. More information on what these folders and files do can be found in the [Jekyll documentation site](https://jekyllrb.com/docs/structure/).
-
-```bash
-Lagrange
-
-├── _data # Data files
-| └── authors.yml # For managing multiple authors
-| └── settings.yml # Theme settings and custom text
-├── _includes # Theme includes
-├── _layouts # Theme layouts (see below for details)
-├── _posts # Where all your posts will go
-├── assets # Style sheets and images are found here
-| ├── css
-| | └── main.css
-| | └── syntax.css
-| └── img
-├── menu # Menu pages
-├── _config.yml # Site build settings
-└── index.md # Home page
-```
-
-### Starting From Scratch
-
-To completely start from scratch, simply delete all the files in the `_posts`, and `menu` folder, and add your own content. You may also replace the `README.md` file with your own README. Everything in the `_data` folder can be edited to suit your needs.
-
-## Configuration
-
-### Site Variables
-
-To change site build settings, edit the `_config.yml` file found in the root of your repository, which you can tweak however you like. More information on configuration settings can be found on [the Jekyll documentation site](https://jekyllrb.com/docs/configuration/).
-
-If you are hosting your site on GitHub Pages, then committing a change to the `_config.yml` file will force a rebuild of your site with Jekyll. Any changes made should be viewable soon after. If you are hosting your site locally, then you must run `jekyll serve` again for the changes to take place.
-
-In the `settings.yml` and `authors.yml` files found in the `_data` folder, you will be able to customize your site settings, such as the title of your site, what shows up in your menu, and social media information. To make author organization easier, especially if you have multiple authors, all author information is stored in the `authors.yml` file.
-
-### Adding Menu Pages
-
-The menu pages are found in the `menu` folder in the root directory, and can be added to your menu in the `settings.yml` file.
-
-### Posts
-
-You will find example posts in your `_posts` directory. Go ahead and edit any post and re-build the site to see your changes. You can rebuild the site in many different ways, but the most common way is to run `jekyll serve`, which launches a web server and auto-regenerates your site when a file is updated.
-
-To add new posts, simply add a file in the `_posts` directory that follows the convention of `YYYY-MM-DD-name-of-post.md` and includes the necessary front matter. Take a look at any sample post to get an idea about how it works. If you already have a website built with Jekyll, simply copy over your posts to migrate to Lagrange. Note: Images were designed to be 1024x600 pixels, with teaser images being 1024x380 pixels.
-
-### Layouts
-
-There are two main layout options that are included with Lagrange: post and page. Layouts are specified through the [YAML front block matter](https://jekyllrb.com/docs/frontmatter/). Any file that contains a YAML front block matter will be processed by Jekyll. For example:
-
-```
----
-layout: post
-title: "Example Post"
----
-```
-
-Examples of what posts looks like can be found in the `_posts` directory, which includes this post you are reading right now. Posts are the basic blog post layout, which includes a header image, post content, author name, date published, social media sharing links, and related posts.
-
-Pages are essentially the post layout without and of the extra features of the posts layout. An example of what pages look like can be found at the [About]({{ site.github.url }}/about.html) and [Contacts]({{ site.github.url }}/contacts.html).
-
-In addition to the two main layout options above, there are also custom layouts that have been created for the [home page]({{ site.github.url }}) and the [archives page]({{ site.github.url }}/writing.html). These are simply just page layouts with some [Liquid template code](https://shopify.github.io/liquid/). Check out the `index.html` and `writing.md` files in the root directory for what the code looks like.
-
-### YAML Front Block Matter
-
-The recommended YAML front block is:
-
-```
----
-layout:
-title:
-categories:
-tags: []
-image:
- feature:
- teaser:
- credit:
- creditlink:
-
----
-```
-
-`layout` specifies which layout to use, `title` is the page or post title, `categories` can be used to better organize your posts, `tags` are used to show related posts, as well as indicate what topics are related in a given post, and `image` specifies which images to use. There are two main types of images that can be used in a given post, the `feature` and the `teaser`, which are typically the same image, except the teaser image is cropped for the home page. You can give credit to images under `credit`, and provide a link if possible under `creditlink`.
-
-## Features
-
-### Design Considerations
-
-Lagrange was designed to be a minimalist theme in order for the focus to remain on your content. For example, links are signified mainly through an underline text-decoration, in order to maximize the perceived affordance of clickability (I originally just wanted to make the links a darker shade of grey).
-
-### Disqus
-
-Lagrange supports comments at the end of posts through [Disqus](https://disqus.com/). In order to activate Disqus commenting, set `disqus.comments` to true in the `settings.yml` file under `_data`. If you do not have a Disqus account already, you will have to set one up, and create a profile for your website. You will be given a `disqus_shortname` that will be used to generate the appropriate comments sections for your site. More information on [how to set up Disqus](http://www.perfectlyrandom.org/2014/06/29/adding-disqus-to-your-jekyll-powered-github-pages/).
-
-### Google Analytics
-
-It is possible to track your site statistics through [Google Analytics](https://www.google.com/analytics/). Similar to Disqus, you will have to create an account for Google Analytics, and enter the correct Google ID for your site under `google-ID` in the `settings.yml` file. More information on [how to set up Google Analytics](https://michaelsoolee.com/google-analytics-jekyll/).
-
-### RSS Feeds
-
-Atom is supported through [Jekyll-Feed](https://github.com/jekyll/jekyll-feed) and RSS 2.0 is supported through [RSS autodiscovery](http://www.rssboard.org/rss-autodiscovery).
-
-
-### Social Media icons
-
-All social media icons are courtesy of [Font Awesome](http://fontawesome.io/). You can change which icons appear, as well as the account that they link to, in the `settings.yml` file in the `_data` folder.
-
-## Everything Else
-
-Check out the [Jekyll docs][jekyll-docs] for more info on how to get the most out of Jekyll. File all bugs/feature requests at [Jekyll's GitHub repo][jekyll-gh]. If you have questions, you can ask them on [Jekyll Talk][jekyll-talk].
-
-[jekyll-docs]: http://jekyllrb.com/docs/home
-[jekyll-gh]: https://github.com/jekyll/jekyll
-[jekyll-talk]: https://talk.jekyllrb.com/
-
-## Credits
-
-## License
diff --git a/_posts/2016-01-01-Welcome-to-Lagrange.md b/_posts/2016-01-01-Welcome-to-Lagrange.md
deleted file mode 100755
index 9de724b1bc..0000000000
--- a/_posts/2016-01-01-Welcome-to-Lagrange.md
+++ /dev/null
@@ -1,25 +0,0 @@
----
-layout: post
-title: "Welcome to Lagrange!"
-author: "Paul Le"
-categories: journal
-tags: [documentation,sample]
-image:
- feature: mountains.jpg
- credit: Death to Stock Photo
- creditlink: ""
----
-
-Lagrange is a minimalist Jekyll theme. The purpose of this theme is to provide a simple, clean, content-focused blogging platform for your personal site or blog. Below you can find everything you need to get started.
-
-### Getting Started
-
-[Getting Started]({{ site.github.url }}{% post_url 2015-10-10-getting-started %}): getting started with installing Lagrange, whether you are completely new to using Jekyll, or simply just migrating to a new Jekyll theme.
-
-### Example Content
-
-[Text and Formatting]({{ site.github.url }}{% post_url 2015-09-09-text-formatting %})
-
-### Questions?
-
-This theme is completely free and open source software. You may use it however you want, as it is distributed under the [MIT License](http://choosealicense.com/licenses/mit/). If you are having any problems, any questions or suggestions, feel free to [tweet at me](https://twitter.com/intent/tweet?text=My%question%about%Lagrange%is:%&via=paululele), or [file a GitHub issue](https://github.com/lenpaul/lagrange/issues/new).
diff --git a/_posts/2016-01-01-welcome-to-lagrange.md b/_posts/2016-01-01-welcome-to-lagrange.md
deleted file mode 100755
index 9de724b1bc..0000000000
--- a/_posts/2016-01-01-welcome-to-lagrange.md
+++ /dev/null
@@ -1,25 +0,0 @@
----
-layout: post
-title: "Welcome to Lagrange!"
-author: "Paul Le"
-categories: journal
-tags: [documentation,sample]
-image:
- feature: mountains.jpg
- credit: Death to Stock Photo
- creditlink: ""
----
-
-Lagrange is a minimalist Jekyll theme. The purpose of this theme is to provide a simple, clean, content-focused blogging platform for your personal site or blog. Below you can find everything you need to get started.
-
-### Getting Started
-
-[Getting Started]({{ site.github.url }}{% post_url 2015-10-10-getting-started %}): getting started with installing Lagrange, whether you are completely new to using Jekyll, or simply just migrating to a new Jekyll theme.
-
-### Example Content
-
-[Text and Formatting]({{ site.github.url }}{% post_url 2015-09-09-text-formatting %})
-
-### Questions?
-
-This theme is completely free and open source software. You may use it however you want, as it is distributed under the [MIT License](http://choosealicense.com/licenses/mit/). If you are having any problems, any questions or suggestions, feel free to [tweet at me](https://twitter.com/intent/tweet?text=My%question%about%Lagrange%is:%&via=paululele), or [file a GitHub issue](https://github.com/lenpaul/lagrange/issues/new).
diff --git a/_posts/2017-12-27-Bayesian-thinking.md b/_posts/2017-12-27-Bayesian-thinking.md
new file mode 100644
index 0000000000..6b1fd3b864
--- /dev/null
+++ b/_posts/2017-12-27-Bayesian-thinking.md
@@ -0,0 +1,115 @@
+---
+layout: post
+title: "Bayesian thinking- what can we learn about reasoning from the machines?"
+author: "Damian Bogunowicz"
+categories: blog
+tags: [AI, Bayes' theorem, mathematics, psychology]
+image: thinker.jpeg
+---
+
+
+
+
+Bayes' rule may be one of the numerous formulas students are introduced to during A-Level maths course. I believe that most pupils (including myself back in the days) usually learn it by heart, use it without thought during their statistics exam and quickly forget it. But Bayesian reasoning may actually be one of the most important mathematical tools we could apply in real life. It is a powerful mean to test and enhance our thinking so that we can overcome common fallacies of reasoning.
+
+## Table of Contents
+
+1. The number game- a simple thought experiment
+2. The baffling mathematics of drunk driving
+3. The Bias' theorem - how we pick our priors
+4. What we can learn from the robots to refine our reasoning
+
+## The number game- a simple thought experiment
+{:.no_toc}
+
+An elegant and simple introduction to Bayesian thinking is known as a number game (based on the [thesis by Josh Tenenbaum](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.33.212&rep=rep1&type=pdf)). Let's say I have a big bag of numbered balls (for simplicity, the numbers are integers from 1 to 100). The first question I want you to answer is:
+
+>If I take few balls randomly out the bag, what would be the most likely number to come up?
+
+Well, you don't know much about my bag. When I am about to pick a random ball, you are unable to say whether number 66 is more likely to be drawn than number 13. This means that probabilities of picking any number in the known range are the same.
+
+>Now, let me pick one random ball from the bag. There it is, number 16. Now, knowing that this number was in my bag, tell me which number is most likely to be selected next.
+
+Now, we have some new data which we can take into consideration. Since we know that 16 was present in our bag of numbers, we are may start reasoning, that we are more likely to expect 6 (since 16 and 6 have a common digit) or 17 (since it lies on a number line just next to 16) then say, 99. The actual results of this experiment are presented in the figure below.
+
+{:refdef: style="text-align: center;"}
+
+{: refdef}
+Source: Machine Learning: A Probabilistic Perspective (Kevin P. Murphy)
+
+>Now, let's choose four numbers. There they are- 16, 8, 2 and 64. Now, given theose numbers, what would be the most likely number to come up next?
+
+Now we get even more numbers. We may try to take advantage of the new data and match those values to some pattern or a rule. Which rule governs our set of numbers? Well, all numbers chosen are even. Should we expect an even number then? All numbers are also powers of 2! So maybe 32 would fit our prediction nicely? The following figure shows that those are all very good candidates for a prediction.
+
+{:refdef: style="text-align: center;"}
+
+{: refdef}
+
+>Last example. The selected numbers are 16, 23, 19 and 20. What's coming up next?
+
+Now the reasonable answer would be 17, 22 or 21, because the new data indicates that numbers in the bag have values close to to 20. The other possible predictions are as shown in the chart.
+
+{:refdef: style="text-align: center;"}
+
+{: refdef}
+
+In every scenario I have presented, we follow the same reasoning. Firstly, we have some the initial knowledge (we pick randomly from the set of integers from 1 to 100). Secondly, we are given some new data, which improves our current state of knowledge and can help us to make a correct guess.
+
+## The baffling mathematics of drunk driving
+Having vague understanding of the Bayes' theorem, we may use an example to illustrate how this rule can be applied in real-life. Imagine you pick up your girlfriend from a party in your car. While you are returning home you get pulled over by the police. The officer suspects that you have been drinking. Your car indeed smells like alcohol and cigarettes plus you look tired, so it is no surprise that you are asked to take a breathalyser test. Sadly, although you know you haven't had a sip of beer, the test indicates that you are drunk. How can you deal with this startling situation? This is where the Bayes' theorem comes in handy.
+
+Let's introduce some mathematical notation. We have an event D, which indicates if you are drunk or not. D=1 means that you have been drinking while D=0 indicates sobriety. An event B shows the result of the breathalyser test. B=1 means that the device says that you have been drinking. B=0 means that you have been identified as a sober driver. Simple right? Now let's investigate some basic probabilities:
+- Assume that the breathalyser test always detects a drunk person i.e. B=1 given D=1 is always 100%. This can be written as P(B=1|D=1)=100%.
+- Breathalysers are smart devices, but they are not perfect. It may happen (as it did in your case), with a probability of 5%, that somebody is identified as drunk while being actually sober. This means that P(B=1|D=0)=5%.
+
+In our current situation, we would like to know the answer to the following question:
+
+>What is the overall probability of that a driver has not been drinking, given that the breathalyser indicates otherwise?
+
+The mathematical formulation of the question can be expressed as finding the probability P(D=0|B=1). The first answer that comes to mind is obviously 5%, right? I have just said, that there is 5% chance of the test being wrong. Well, let's take advantage of the Bayes' theorem to clarify this conundrum.
+
+$$ P( D=0 | B=1) = \frac{P(B=1|D=0)P(D=0)}{P(B=1)} $$
+
+To solve our problem we need to evaluate two values P(D=0) and P(B=1). While P(B=1) can be easily calculated, the most important element of the equation is the term P(D=0).
+
+
+P(D=0) is known as a **base value** (or prior). It is a statistical piece of data, which helps us to get the full insight to evaluate the problem. By analogy to our number game, the base value was given by the numbers we have seen before guessing the number of a next ball. In our new example, the base value is the probability that a driver is not drunk, this is what P(D=0) stands for. For sake of our example we may say that, on average, 1 person out of 1000 people drives under influence of the alcohol, i.e. P(D=0)=999/1000.
+
+The probability of test being positive P(B=1), is the sum of two factors:
+- Test was positive and the driver was drunk, P(B=1,D=1)
+- Test was positive and the driver was sober, P(B=1,D=0)
+
+Now using Bayes' theorem and product rule for the denominator we may solve our equation.
+
+$$ P( D=0 | B=1) = \frac{P(B=1|D=0)P(D=0)}{P(B=1,D=0)+P(B=1,D=1)} $$
+
+$$ P( D=0 | B=1) = \frac{5\cdot 0.999}{5\cdot 0.999+ 100\cdot 0.001}=0.98 $$
+
+This means that there is 98% chance that the driver is sober, given that the test indicates otherwise! Suprising, isn't it? When we think about it for a while, it actually does make sense. There are so few people who are drunk driving, that a policeman must be aware of the fact, that most drivers who are pulled over and get identified as drunk, are most likely sober. But what if we happen to be pulled over by an officer who is not aware of that fact? The solution is straightforward. **Ask the policeman to redo the test and simply breath into a second device**. Mathematically it is equivalent to redoing our calculations. The only difference is, we use our old solution as a new base value. The new prior is richer in information and will deliver a better reflection of the reality. The new probability equals 71% and will continue to decrease with every new test. So the conclusion is: if you are sure that you are sober and the breathalyser indicates otherwise, ask for as many test as you possibly can and you are bound to be all right.
+That is a suprising and very neat mathematical lesson we could apply in real-life situation. Now, let's add some psychology to our story...
+
+
+## The Bias' theorem - how we pick our priors
+{:.no_toc}
+
+We may take a closer look at the psychological view on the Bayes' theorem. In his bestselling book [Thinking, Fast and Slow](https://www.goodreads.com/book/show/11468377-thinking-fast-and-slow) , Daniel Kahneman describes an interesting problem. Let's reverse roles by stepping into shoes of a police officer, whose task is to solve the following conundrum.
+
+Last night there was a hit and run case reported. All the witnesses confirm unanimously, that a pedestrian was hit by a cab. There are two taxi companies in our city, Company Red and Company Blue. We have access to the following data:
+- We know that 85% of all taxis in the city belong to the Company Red. The remaining 15% belongs to the Company Blue.
+- We have identified a witness, who could clearly see the accident. The witness is sure that the Red taxi had caused the accident. The court has established that there is 80% probability that witness' statement is true.
+
+So what is the probability that the accident was actually caused by the Red taxi?
+Well, we have already seen what happens when we think only about the core of the problem and forget about the base value. The study conducted by Kahneman confirms our observation- it has shown, that people neglect the prior and their reasoning is guided usually by the data provided by the witness. The answer given by the participants was in most cases 80%. The base value tends to be neglected due to the fact, that our brains have hard time dealing with purely statistical data. What is easier to digest and quickly draws our attention, is the relationship between the cause and the effect. After all, what does the number of cabs in the city has to do with the fact that this specific taxi driver has caused the accident?
+Now we do know, that the sole fact, that we are 6 times more likely to encounter the Red taxi then the Blue taxi on the street, may imply, that we are 6 times more likely the be hit by the Red taxi then the Blue taxi. This purely statistical fact is rarely taken into consideration. In the end, the probability that the accident was caused by the red taxi is actually 41%, which is far from 80% declared by the participants. Interestingly enough the study has shown that when we rephrase the prior in the more emotional way, say:
+
+>Both companies have the same number of taxis, but Red taxis cause 85% of all taxi accidents.
+
+people are more likely to reflect on the new prior, since now it makes the Red Company look bad, it conveys some intriguing, emotional message. This sentence makes us feel anxious about their drivers and we are very likely to remember this controversial piece of information and recall it e.g. during the trial. It satisfies our craving for the cause and the effect relationship, although it has identical mathematical meaning to our initial, vanilla prior.
+
+## What we can learn from the robots to refine our reasoning.
+{:.no_toc}
+
+Bayes' theorem is used widely in the field of artificial intelligence. There are numerous algorithms which base on this concept, such as Naive Bayes Classifier or Bayesian Networks. How a computer thinks is naturally very different from our reasoning. In the end, a human brain is one of the most astonishing gifts we have received from the nature. While being a superior to computers in many ways, it is very susceptible to prejudice, cognitive errors, erroneous generalizations and various mental shortcuts. That is why, when we are about to express our opinion or give a judgement, it may be helpful to step back, restrain our train of thought and question our state of knowledge. This can be done by taking advantage of hard, statistical facts to refine our reasoning. There are some more great examples [in the short video by Julia Galef](https://www.youtube.com/watch?v=BrK7X_XlGB8&t), which further demonstrate how to evaluate thought processes using the Bayesian legacy.
+
+
+Source of the cover image: http://www.visitphilly.com/
diff --git a/_posts/2018-04-01-Robot-Localization.md b/_posts/2018-04-01-Robot-Localization.md
new file mode 100644
index 0000000000..6f42253094
--- /dev/null
+++ b/_posts/2018-04-01-Robot-Localization.md
@@ -0,0 +1,303 @@
+---
+layout: post
+title: "Practical tutorial- Robot localization using Hidden Markov Models"
+author: "Damian Bogunowicz"
+categories: blog
+tags: [AI, hidden markov model, tutorial, python, programming, psychology]
+image: warehouse.jpg
+---
+
+In year 2003 the team of scientists from the Carnegie Mellon university [has created a mobile robot](https://www.cs.cmu.edu/~thrun/3D/mines/groundhog/index.html) called Groundhog, which could explore and create the map of an abandoned coal mine. The rover explored tunnels, which were too toxic for people to enter and where oxygen levels were too low for humans to remain concious. The task was not easy: navigate in the environment, which the robot has not seen before, and simultanously discover and create a map of those unknown tunnels.
+
+{:refdef: style="text-align: center;"}
+{:height="80%" width="80%"}
+{: refdef}
+The groundhog robot enters the abandoned coal mine. (source: www.cs.cmu.edu)
+
+Fifteen years later, the problem of constructing a map of an unknown environment, while keeping track of agent's location within it (the so called SLAM task- Simultaneous Localization And Mapping), is still being scrutinized by the researchers. This notion is not only used in the fields of self-driving cars or rovers, but is also present in case of domestic robots such as iRobot's Roomba. In the year 2017 Amazon [has doubled the number of its robotic fleet](https://www.technologyreview.com/the-download/609672/amazons-investment-in-robots-is-eliminating-human-jobs/). So far, the robo-workers are there to move packages through the gigantic warehouses, but it is only a matter of time until advanced robots will work hand in hand with actual people, performing more complicated tasks. This shows that given current state of the technology, the ability for robots to understand their position in the environment is indispensable.
+
+{:refdef: style="text-align: center;"}
+
+{: refdef}
+Chuck, a robotic warehouse assistant. Perhaps in the near future warehouses will be operated only by sophisticated robots... (source: www.cnbc.com)
+
+The goal of this tutorial is to tackle a simple case of mobile robot localization problem using Hidden Markov Models. Let's use an example of a mobile robot in a warehouse. The agent is randomly placed in an environment and we, its supervisors, cannot observe what happens in the room. The only information we receive are the sensor readings from the robot.
+
+## Table of Contents
+
+1. Case formulation
+ 1. Environment
+ 2. Sensors
+ 3. Hidden Markov Models
+2. The solution
+ 1. Transition model
+ 2. Initial state
+ 3. Sensor model
+ 4. Results
+ 5. Alternative possible solutions
+ 6. The code in Python
+
+## Case formulation
+
+>"An agent is anything that can be viewed as perceiving its environment through sensors and acting upon that environment through effectors"
+
+{:refdef: style="text-align: center;"}
+
+{: refdef}
+Source: Artificial Intelligence: A Modern Approach (S. Russell and P. Novig)
+
+To fully define a case we need to specify two pieces of information:
+* environment (the warehouse),
+* sensor model (how the robot perceives the environment)
+
+
+### Environment
+{:refdef: style="text-align: center;"}
+{:height="80%" width="80%"}
+{: refdef}
+Figure 1: Environment of the robot
+
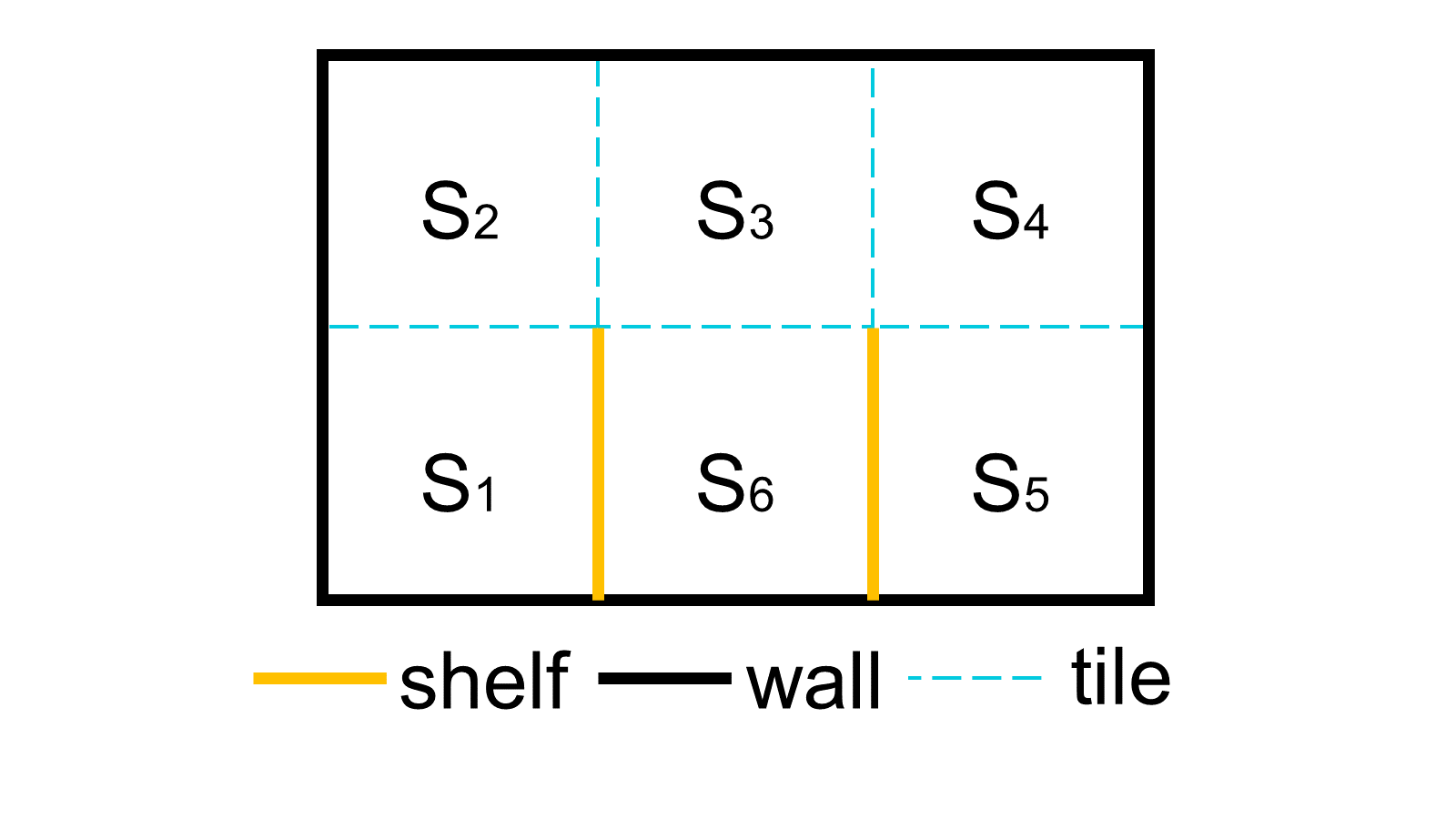
+The agent can move within an area of 6 square tiles. In the mini-warehouse there is one shelf located between tiles $$S_1$$ and $$S_6$$ and a second shelf between $$S_6$$ and $$S_5$$. In the technical jargon one may say, that the environment of the agent consists of six descrete states. The time is also descrete. At each subsequent time step the robot is programmed to change its position with a probability of 80% and moves randomly to a different neighboring tile. As soon as the robot makes a move, we receive four readings from the sensing system.
+
+{:refdef: style="text-align: center;"}
+{:height="100%" width="100%"}
+{: refdef}
+Figure 2: Probabilistic graphical model
+
+### Sensors
+Just as we humans can localizate ourselves using senses, robots use sensors. Our agent is equipped with the sensing system composed of a compass and a proximity sensor, which detects obstacles in four directions: north, south, east and west. The sensor values are conditionally independent given the position of the robot. Moreover, the device is not perfect, the sensor has an error rate of $$ e=25% $$.
+
+### Hidden Markov Models
+The Hidden Markov Model (HMM) is a simple way to model sequential data. There exists some state $$X$$ that changes over time. It is assumed that this state at time t depends only on previous state in time t-1 and not on the events that occurred before ( why
+known as Markov property). We wish to estimate this state $$X$$. Unfortunately, we cannot directly observe it, the state is not directly visible (hidden). However, we can observe a piece of information correlated with the state, the evidence $$E$$, which helps us to estimate $$X$$.
+
+{:refdef: style="text-align: center;"}
+{:height="80%" width="80%"}
+{: refdef}
+Figure 3: Temporal evolution of a hidden Markov model
+
+Our model consists of hidden states $$X_0,X_1,X_2,..., X_{t-2}, X_{t-1},X_t$$ (the unknown location of a robot in time) and known pieces of evidence $$E_1, E_2, ..., E_{t-2},E_{t-1},E_t$$ (the subsequent readings from the sensor).
+
+
+There are two tools which we use to localize the robot:
+
+* filtering- estimation of the state in time $$X_t$$, knowing the state $$X_{t-1}$$ and evidence $$E_{t}$$.
+
+$${f_{1:t}= \alpha*O_t*T*f_{1:t-1}}$$
+
+* prediction- filtering without evidence. We make a guess about the $$X_t$$knowing only state $$X_{t-1}$$.
+
+ $${f_{1:t}= \alpha*T*f_{1:t-1}}$$
+
+where:
+* $${f_{1:t}}$$ current probability vector in time t
+* $${f_{1:t-1}}$$ previous probability vector in time t-1
+* $${\alpha}$$ normalization constant
+* $${O_t}$$ observation matrix for the evidence in time t
+* $${T}$$ transition matrix
+
+# Let's solve the problem!
+
+## Transition model
+The transition model is the probability of a transition from state i to state j . This can be mathematically expressed as:
+
+$$ T_{i,j} = {P(X_t=j|X_{t-1}=i)} $$
+
+What is the meaning of this formula? Knowing that at time t-1 the agent was in state i, it gives us the probability of the agent being in state j in the current time t . To make it clearer, let's give an example.
+
+The robot changes his position from tile 1 to tile 2.
+This means the transition from $$S_1$$ to $$S_2$$ . We see from figure 2, that the probability of this transition equals 80%.
+
+$$ T_{S_1,S_2} = {P(X_t=S_2|X_{t-1}=S_1)}=0.8 $$
+
+This solution is only one of many transitions possible for the robot in our environment. The domain of the state variable $$X_t$$ is a set of all the possible tiles in the environment: $$<{S_1,S_2,S_3,S_4,S_5,S_6}>$$ . Hence, the full transition matrix, which contains all the possible transitions from state i to state j, will have 6x6=36 entries.
+
+$$ T\mathbf = \begin{pmatrix}
+ T_{S_1,S_1} & T_{S_2,S_1} & T_{S_3,S_1} & T_{S_4,S_1} & T_{S_5,S_1} & T_{S_6,S_1} \\
+ T_{S_1,S_2} & T_{S_2,S_2} & T_{S_3,S_2} & T_{S_4,S_2} & T_{S_5,S_2} & T_{S_6,S_2} \\
+ T_{S_1,S_3} & T_{S_2,S_3} & T_{S_3,S_2} & T_{S_4,S_3} & T_{S_5,S_3} & T_{S_6,S_3} \\
+ T_{S_1,S_4} & T_{S_2,S_4} & T_{S_3,S_2} & T_{S_4,S_4} & T_{S_5,S_4} & T_{S_6,S_4} \\
+ T_{S_1,S_5} & T_{S_2,S_5} & T_{S_3,S_2} & T_{S_4,S_5} & T_{S_5,S_5} & T_{S_6,S_5} \\
+ T_{S_1,S_6} & T_{S_2,S_6} & T_{S_3,S_2} & T_{S_4,S_6} & T_{S_5,S_6} & T_{S_6,S_6} \\
+ \end{pmatrix} =\\=
+ \begin{pmatrix}
+ 0.2 & 0.4 & 0 & 0 & 0 & 0 \\
+ 0.8 & 0.2 & 0.27 & 0 & 0 & 0 \\
+ 0 & 0.4 & 0.2 & 0.4 & 0 & 0.8 \\
+ 0 & 0 & 0.27 & 0.2 & 0.8 & 0 \\
+ 0 & 0 & 0 & 0.4 & 0.2 & 0 \\
+ 0 & 0 & 0.27 & 0 & 0 & 0.2\\
+ \end{pmatrix} $$
+
+## Initial state
+To make the problem more interesting, let's assume that we do not know the initial position of the robot. The logical approach is to assume a uniform probability distribution over all tiles of the grid. Since our environment consists of 6 states, we can say that for any of those 6 states (let's call this hypothetical state i ), the probability that the agent starts its adventure in square i is:
+
+$$ {P(X_0=i)=1/6} $$
+
+We can express this probability for all six states using vector notation:
+
+$$ f_{0}=\begin{pmatrix}
+ P(X_0=S_1) \\
+ P(X_0=S_2) \\
+ P(X_0=S_3) \\
+ P(X_0=S_4) \\
+ P(X_0=S_5) \\
+ P(X_0=S_6) \\
+ \end{pmatrix} =
+
+ \begin{pmatrix}
+ 1/6 \\
+ 1/6 \\
+ 1/6 \\
+ 1/6 \\
+ 1/6 \\
+ 1/6 \\
+ \end{pmatrix} $$
+
+## Sensor model
+Sensor model consists out of evidence, which allows to make inference about the agent's position in the environment.
+In the first time step robot detects a wall in directions: south, west and east. How can we express this information in the mathematical notation? We want to find the answer to the question: given that we are in state i, what is the probability that the sensor returns reading $$ {E=j} $$? That is:
+
+$$ {O_{i,j}=P(E=j| X=i)=(1-e)^{4-d}*e^d}$$
+
+where e is an error rate of a sensor and d is the discrepancy- a number of signals that are different- between the true values for tile i and the actual reading. This means that the probability that a sensor got all directions right is $$ {(1-e)^{4}}$$ and probability of getting them all wrong is $${e^4}$$. Assume that the sensor returns reading SWE at time step 1 while robot is in state 2. It detects an eastern wall, but does not take into account the northern wall and reports obstacles in directions south and east, which are actually not there. This means that one out of four sensors returns a correct measurement, so:
+
+$$ {P(E_1=SWE| X_1=2)=(1-0.25)^{3}*0.25=0.11}$$
+
+Let us assume the following sequence of readings for the robot: SWE, NW, N, NE, SWE. Each piece of evidence is represented as a diagonal matrix O of a same shape as the transition matrix. For a reading in NW direction, the observation matrix looks as follows:
+
+$$ O_{NW}\mathbf = \begin{pmatrix}
+ O_{NW,S_1} & 0 & 0 & 0 & 0 & 0 \\
+ 0 & O_{NW,S_2} & 0 & 0 & 0 & 0 \\
+ 0 & 0 & O_{NW,S_3} & 0 & 0 & 0 \\
+ 0 & 0 & 0 & O_{NW,S_4} & 0 & 0 \\
+ 0 & 0 & 0 & 0 & O_{NW,S_5} & 0 \\
+ 0 & 0 & 0 & 0 & 0 & O_{NW,S_6} \\
+ \end{pmatrix} =\\=
+ \begin{pmatrix}
+ 0.01 & 0 & 0 & 0 & 0 & 0 \\
+ 0 & 0.32 & 0 & 0 & 0 & 0 \\
+ 0 & 0 & 0.11 & 0 & 0 & 0 \\
+ 0 & 0 & 0 & 0.04 & 0 & 0 \\
+ 0 & 0 & 0 & 0 & 0.01 & 0 \\
+ 0 & 0 & 0 & 0 & 0 & 0.01 \\
+ \end{pmatrix} $$
+
+## Results
+{:refdef: style="text-align: center;"}
+
+{: refdef}
+Figure 5: Filtering in HMM for 5 time steps
+
+Using the code in Python we may create different scenarios for the robot. We assume, that evidence gathered by the sensor are readings in directions SWE, NW, N, NE, SWE. Figure 5 shows us the probability plots for 5 timesteps. The xy plane is the grid of the warehouse while the z axis indicates the probability of the agent being present in the given tile in each time step. The size of each bar in the chart corresponds to the probability that the robot is at that location. In any time step the algorithm makes inference about the probability of the agent being in a given tile.
+
+{:refdef: style="text-align: center;"}
+{:height="80%" width="80%"}
+{: refdef}
+Figure 6: The inferred path of the robot
+
+We can see, that given our sensor data, we may deduce the most possible locationin every time step. The robot probably starts his adventure in state 1, then advances to state 2, state 3, state 4 and approaches the shelf in state 5. Although, the error rate of 0.25 is pretty high, the algorithm manages to deliver statisfying results (given a fairly simple environment).
+
+{:refdef: style="text-align: center;"}
+
+{: refdef}
+Figure 7: Filtering in HMM for time steps 1,2,3 and then prediction for 4,5
+
+Here, we try to estimate where the robot might be, while lacking the evidence for time steps 4 and 5. When the agent fails to deliver the evidence, we predict its position basing solely on its previous state. That is why our model evaluates that in time step 4, the robot has very high probability of being in tiles neighbouring to the state in the time step 3. Then, in time step 5, the model is pretty confident that the robot returns to $$S_3$$, however it gives quite high probabilities to all the other scenarios.
+
+## Alternative possible solutions
+It is important to stress that our implementation treats every timestep sequentially. To find the most likely __sequence of states__ for a Markov Hidden Model, we should implement the Viterbi algorithm. Filtering and prediction give us marginal probability for each individual state, while Viterbi gives probability of the most likely sequence of states. So our HMM implementation evaluates the probability of robot being in some state for each time step; Viterbi would give the most likely sequence of states, and the probability of this sequence. Another cool tool which we can use to localize a robot is particle filtering- a very elegant and efficient algorithm. I can highly recommend [a great video](https://www.youtube.com/watch?v=aUkBa1zMKv4) by Andreas Svensson to get an intuition on how the particle filtering works.
+
+## The code in Python
+
+```python
+import numpy as np
+import matplotlib.pyplot as plt
+import seaborn
+from mpl_toolkits.mplot3d import Axes3D
+
+class HMM(object):
+
+ def __init__(self, transition_matrix_matrix,current_state):
+ self.transition_matrix = transition_matrix
+ self.current_state = current_state
+
+ def filtering(self,observation_matrix):
+ new_state = np.dot(observation_matrix,np.dot(self.transition_matrix,self.current_state))
+ new_state_normalized = new_state/np.sum(new_state)
+ self.current_state = new_state_normalized
+ return new_state_normalized
+
+ def prediction(self):
+ new_state = np.dot(self.transition_matrix,self.current_state)
+ new_state_normalized = new_state/np.sum(new_state)
+ self.current_state=new_state_normalized
+ return new_state_normalized
+
+ def plot_state(self):
+ fig = plt.figure()
+ ax1 = fig.add_subplot(111, projection='3d')
+ xpos = [0,0,1,2,2,1]
+ ypos = [0,1,1,1,0,0]
+ zpos = np.zeros(len(initial_state.shape))
+ dx = np.ones(len(initial_state.shape))
+ dy = np.ones(len(initial_state.shape))
+ dz = self.current_state
+ ax1.bar3d(xpos, ypos, zpos, dx, dy, dz, color='#ce8900')
+ ax1.set_xticks([0., 1., 2.,3.])
+ ax1.set_yticks([0., 1., 2.])
+ plt.show()
+
+ def create_observation_matrix(self,error_rate, no_discrepancies):
+ sensor_list=[]
+ for number in no_discrepancies:
+ probability=(1-error_rate)**(4-number)*error_rate**number
+ sensor_list.append(probability)
+ observation_matrix = np.zeros((len(sensor_list),len(sensor_list)))
+ np.fill_diagonal(observation_matrix,sensor_list)
+ return observation_matrix
+
+# define two models
+transition_matrix = np.array([[0.2,0.4,0,0,0,0],
+ [0.8,0.2,0.267,0,0,0],
+ [0,0.4,0.2,0.4,0,0.8],
+ [0,0,0.267,0.2,0.8,0],
+ [0,0,0,0.4,0.2,0],
+ [0,0,0.267,0,0,0.2]])
+
+initial_state=np.array([1/6,1/6,1/6,1/6,1/6,1/6])
+
+Model = HMM(transition_matrix,initial_state)
+Model2 = HMM(transition_matrix,initial_state)
+
+# create observation matrices
+observation_matrix_SWE = Model.create_observation_matrix(0.25,[0,3,4,3,0,0])
+observation_matrix_NW = Model.create_observation_matrix(0.25,[3,0,1,2,3,3])
+observation_matrix_N = Model.create_observation_matrix(0.25, [4,1,0,1,4,4])
+observation_matrix_NE = Model.create_observation_matrix(0.25, [3,2,1,0,3,3])
+
+# localize of the robot using filtering
+state_1 = Model.filtering(observation_matrix_SWE)
+Model.plot_state()
+state_2 = Model.filtering(observation_matrix_NW)
+Model.plot_state()
+state_3 = Model.filtering(observation_matrix_N)
+Model.plot_state()
+state_4 = Model.filtering(observation_matrix_NE)
+Model.plot_state()
+state_5 = Model.filtering(observation_matrix_SWE)
+Model.plot_state()
+
+# localize of the robot using filtering (three first timesteps) and prediction (two last timesteps)
+state_6 = Model2.filtering(observation_matrix_SWE)
+Model2.plot_state()
+state_7 = Model2.filtering(observation_matrix_NW)
+Model2.plot_state()
+state_8 = Model2.filtering(observation_matrix_N)
+Model2.plot_state()
+prediction_1 = Model2.prediction()
+Model2.plot_state()
+prediction_2 = Model2.prediction()
+Model2.plot_state()
+```
+Source of the cover image: http://www.bleum.com
diff --git a/_posts/2018-05-19-Under-the-hood-LSTM.md b/_posts/2018-05-19-Under-the-hood-LSTM.md
new file mode 100644
index 0000000000..1565665883
--- /dev/null
+++ b/_posts/2018-05-19-Under-the-hood-LSTM.md
@@ -0,0 +1,258 @@
+---
+layout: post
+title: "Practical tutorial- LSTM neural network: A closer look under the hood"
+author: "Damian Bogunowicz"
+categories: blog
+tags: [deep learning, neural network, tutorial, python, programming, LSTM, recurrent neural network]
+image: underthehood.jpg
+---
+
+Since I have learned about long short-term memory (LSTM) networks, I have always wanted to apply those algorithms in practice. Recently I had a chance to work on a project which requires deeper understanding of the mathematical foundations behind LSTM models. I have been investigating how LSTMs are implemented in the source code of Keras library in Python. To my surprise, I found out that the implementation is not as straightforward as I thought. There are some interesting differences between the theory I have learned at the university and the actual source code in Keras.
+
+The great Richard Feynman said once:
+>What I cannot create, I do not understand.
+
+To my mind, this means that one of the best methods to comprehend a concept is to recreate it from the scratch. By doing so, one gets a deeper understanding of a concept and hopefully is able to share knowledge with others. This is the exact purpose of this article so let's get to it!
+
+The goal of this tutorial is to perform a forward pass through LSTM network using two methods. The first approach is to use a model compiled using Keras library. The second method is to extract weights from Keras model and implement the forward pass ourselves using only numpy library. I will only scratch the surface when it comes to the theory behind LSTM networks. For people who are allergic to research papers (otherwise please refer to Hochreiter, S.; Schmidhuber, J. (1997). "Long Short-Term Memory") the concept has been beautifully explained in [the blog post by Christopher Olah](http://colah.github.io/posts/2015-08-Understanding-LSTMs/). I would also recommend to read a [very elegant tutorial by Aidan Gomez](https://medium.com/@aidangomez/let-s-do-this-f9b699de31d9), where the author shows a numerical example of a forward and backward pass in a LSTM network. My final implementation (code in Python) can be found at the end of this article.
+
+## Table of Contents
+
+1. Architecture and the parameters of the LSTM network
+2. Retrieving weight matrices from the Keras mode
+3. Defining a model in Keras
+4. Defining our custom-made model
+5. Implementation)
+6. Comparison and summary
+7. The full code in Python
+
+## Architecture and the parameters of the LSTM network
+
+Firstly, let's discuss how an input to the network looks like. A model takes a sequence of __samples__ (observations) as an input and returns a single number (result) as an output. I call one sequence of observations a __batch__. Thus, a single batch is an input sequence to the network.
+Parameter __timesteps__ defines the length of a sequence. This means that the number of timesteps is equal to the number of samples in a batch. Additionally, since our input has only one feature, the dimension of the input is set to one.
+
+Mathematically, we may say that a batch $$x$$ is a vector $$x\in \Bbb{R}^{timesteps}$$ and the model outputs a value $$y\in \Bbb{R}$$.
+
+According to the [classification done by Andrej Karpathy](http://karpathy.github.io/2015/05/21/rnn-effectiveness), we call such a model a many-to-one model . Let's say that that our timesteps parameter equals 3. This means that an arbitary sequence of a length three $$x=\begin{bmatrix}x_{1}\\x_{2}\\x_{3}\end{bmatrix}$$ returns a single value $$y$$ as shown below:
+
+{:refdef: style="text-align: center;"}
+{:height="50%" width="50%"}
+{: refdef}
+Figure 1: Our example of many-to-one LSTM implementation
+
+Finally, we define usual neural network parameters such as the number of LSTM layers and amount of hidden units in every layer. Our parameters are set to:
+- timesteps = 20
+- no_of_batches = 150
+- no_of_layers = 3
+- no_of_units = 10
+
+For simplification we assume that every LSTM layer has the same number of hidden units. Many-to-one model requires, that after passing through all LSTM layers the intermediate result is finally processed by a single dense layer, which returns the final value $$y$$. That implies that our neural network has the following architecture:
+
+Layer (type) | Output Shape | Param # |
+--------------------- | :-------------------: | :-------------------- :|
+lstm_1 (LSTM) |(None, 20, 10) | 480 |
+lstm_2 (LSTM) | (None, 20, 10) | 840 |
+lstm_3 (LSTM)| (None, 10)| 840 |
+dense_1 (Dense) | (None, 1) | 11 |
+
+Figure 2: Model used in our example
+
+By the way, we can directly see that the shape of the array which is being propagated during the foreward pass in LSTM layers depends on the parameters (no_of_units and timesteps).
+
+## Retrieving weight matrices from the Keras model
+
+```python
+def import_weights(no_of_layers, hidden_units):
+ layer_no = 0
+ for index in range(1, no_of_layers+1):
+ for matrix_type in ['W', 'U', 'b']:
+ if matrix_type != 'b':
+ weights_dictionary["LSTM{0}_i_{1}".format(index, matrix_type)] = model_weights[layer_no][:,:hidden_units]
+ weights_dictionary["LSTM{0}_f_{1}".format(index, matrix_type)] = model_weights[layer_no][:,hidden_units:hidden_units * 2]
+ weights_dictionary["LSTM{0}_c_{1}".format(index, matrix_type)] = model_weights[layer_no][:,hidden_units * 2:hidden_units * 3]
+ weights_dictionary["LSTM{0}_o_{1}".format(index, matrix_type)] = model_weights[layer_no][:,hidden_units * 3:]
+ layer_no = layer_no + 1
+ else:
+ weights_dictionary["LSTM{0}_i_{1}".format(index, matrix_type)] = model_weights[layer_no][:hidden_units]
+ weights_dictionary["LSTM{0}_f_{1}".format(index, matrix_type)] = model_weights[layer_no][hidden_units:hidden_units * 2]
+ weights_dictionary["LSTM{0}_c_{1}".format(index, matrix_type)] = model_weights[layer_no][hidden_units * 2:hidden_units * 3]
+ weights_dictionary["LSTM{0}_o_{1}".format(index, matrix_type)] = model_weights[layer_no][hidden_units * 3:]
+ layer_no = layer_no + 1
+
+ weights_dictionary["W_dense"] = model_weights[layer_no]
+ weights_dictionary["b_dense"] = model_weights[layer_no + 1]
+```
+Our next step involves extracting weights in form of numpy arrays from the Keras model. For every LSTM layer created in our Keras model, the method returns three arrays:
+
+- first array (a kernel) stores weights which correspond to $$W$$ weights for each of four LSTM gates: input gate, forget gate, cell state gate and output gate.
+- second array (called a reccurent kernel) contains respective $$U$$ weights
+- the last, third array (bias) stores respective $$b$$ values.
+
+Function import_weights allows us to quickly extract weights from the Keras model and store them in weights_dictionary, where keys of the dictionary are array names and values are the respective numpy arrays. Taking into account the nature of our model, the last component of the network is a dense layer, so we additionally read off weights for that element.
+
+
+## Defining a model in Keras
+
+```python
+class LSTM_Keras(object):
+ def __init__(self, no_hidden_units, timesteps):
+ self.timesteps = timesteps
+ self.no_hidden_units = no_hidden_units
+ model = Sequential()
+ model.add(LSTM(units = self.no_hidden_units, return_sequences = True, input_shape = (self.timesteps, 1)))
+ model.add(LSTM(units = self.no_hidden_units, return_sequences = True))
+ model.add(LSTM(units = self.no_hidden_units, return_sequences = False))
+ model.add(Dense(units = 1))
+ self.model = model
+```
+
+The object of the class LSTM_Keras returns a model of a neural network. We need this element to:
+- obtain weights for our custom-made model.
+- compare results between Keras implementation and our custom-made implementation.
+
+
+## Defining our custom-made model
+
+```python
+class custom_LSTM(object):
+
+ def __init__(self, timesteps, no_of_units):
+ self.timesteps = timesteps
+ self.no_hidden_units = no_of_units
+ self.hidden = np.zeros((self.timesteps, self.no_hidden_units),dtype = np.float32)
+ self.cell_state = np.zeros((self.timesteps, self.no_hidden_units),dtype = np.float32)
+ self.output_array = []
+
+ def hard_sigmoid(self, x):
+ slope = 0.2
+ shift = 0.5
+ x = (x * slope) + shift
+ x = np.clip(x, 0, 1)
+ return x
+
+ def tanh(self, x):
+ return np.tanh(x)
+
+ def layer(self, xt, Wf, Wi, Wo, Wc, Uf, Ui, Uo, Uc, bf, bi, bo, bc):
+ ft = self.hard_sigmoid(np.dot(xt, Wf) + np.dot(self.hidden, Uf) + bf)
+ it = self.hard_sigmoid(np.dot(xt, Wi) + np.dot(self.hidden, Ui) + bi)
+ ot = self.hard_sigmoid(np.dot(xt, Wo) + np.dot(self.hidden, Uo) + bo)
+ ct = (ft * self.cell_state)+(it * self.tanh(np.dot(xt, Wc) + np.dot(self.hidden, Uc) + bc))
+ ht = ot * self.tanh(ct)
+ self.hidden = ht
+ self.cell_state = ct
+ return self.hidden
+
+ def reset_state(self):
+ self.hidden = np.zeros((self.timesteps, self.no_hidden_units),dtype = np.float32)
+ self.cell_state = np.zeros((self.timesteps, self.no_hidden_units),dtype = np.float32)
+
+ def dense(self, x, weights, bias):
+ result = np.dot(x, weights)+bias
+ self.result=result[0]
+ return result[0]
+
+ def output_array_append(self):
+ self.output_array.append(self.result[0])
+```
+The class custom_LSTM is the core of the code. Its task is to simulate a single LSTM layer in our network. The method layer is the actual implementation of the LSTM equations:
+
+$$f_t=\sigma(W_f*x_t+U_f*h_{t-1}+b_f)$$
+
+$$i_t=\sigma(W_i*x_t+U_i*h_{t-1}+b_i)$$
+
+$$o_t=\sigma(W_o*x_t+U_o*h_{t-1}+b_o)$$
+
+$$c_t={f_t}\circ{c_{t-1}}+i_t*tanh(W_c*x+U_c*h_{t-1}+b_c)$$
+
+$${h_t=o_t * tanh(c_t)}$$
+
+The basic functionality of the custom-made LSTM layer is
+- change the internal state during forward propagation of the batch
+- return an intermediate (hidden) result, which flows from LSTM cell (layer) to the consecutive layer.
+
+The thing which surprised me while I was reading the Keras source code, is that an ordinary sigmoid function has been replaced by a hard sigmoid. The standard logistic function may be sometimes slow to compute because it requires calculating the exponential function. Usually the high-precision result is not needed and an approximation suffices. This is why the hard sigmoid is being used here, to approximate the standard sigmoid and accelerate the computation.
+
+Additional methods of the class allow us to:
+- reset state of a layer.
+- implement the dense layer, which returns a final output.
+
+
+## Implementation
+
+```python
+for batch in range(input_to_keras.shape[0]):
+
+ LSTM_layer_1.reset_state()
+ LSTM_layer_2.reset_state()
+ LSTM_layer_3.reset_state()
+
+ for timestep in range(input_to_keras.shape[1]):
+
+ output_from_LSTM_1 = LSTM_layer_1.layer(input_to_keras[batch,timestep,:], weights_dictionary['LSTM1_f_W'], weights_dictionary['LSTM1_i_W'],
+ weights_dictionary['LSTM1_o_W'], weights_dictionary['LSTM1_c_W'],
+ weights_dictionary['LSTM1_f_U'], weights_dictionary['LSTM1_i_U'],
+ weights_dictionary['LSTM1_o_U'], weights_dictionary['LSTM1_c_U'],
+ weights_dictionary['LSTM1_f_b'], weights_dictionary['LSTM1_i_b'],
+ weights_dictionary['LSTM1_o_b'], weights_dictionary['LSTM1_c_b'])
+
+ output_from_LSTM_2 = LSTM_layer_2.layer(output_from_LSTM_1, weights_dictionary['LSTM2_f_W'], weights_dictionary['LSTM2_i_W'],
+ weights_dictionary['LSTM2_o_W'], weights_dictionary['LSTM2_c_W'],
+ weights_dictionary['LSTM2_f_U'], weights_dictionary['LSTM2_i_U'],
+ weights_dictionary['LSTM2_o_U'], weights_dictionary['LSTM2_c_U'],
+ weights_dictionary['LSTM2_f_b'], weights_dictionary['LSTM2_i_b'],
+ weights_dictionary['LSTM2_o_b'], weights_dictionary['LSTM2_c_b'])
+
+ output_from_LSTM_3 = LSTM_layer_3.layer(output_from_LSTM_2, weights_dictionary['LSTM3_f_W'], weights_dictionary['LSTM3_i_W'],
+ weights_dictionary['LSTM3_o_W'], weights_dictionary['LSTM3_c_W'],
+ weights_dictionary['LSTM3_f_U'], weights_dictionary['LSTM3_i_U'],
+ weights_dictionary['LSTM3_o_U'], weights_dictionary['LSTM3_c_U'],
+ weights_dictionary['LSTM3_f_b'], weights_dictionary['LSTM3_i_b'],
+ weights_dictionary['LSTM3_o_b'], weights_dictionary['LSTM3_c_b'])
+
+ LSTM_layer_3.dense(output_from_LSTM_3, weights_dictionary['W_dense'], weights_dictionary['b_dense'])
+ LSTM_layer_3.output_array_append()
+```
+Having defined all the helper functions and classes, we can finally implement our custom-made LSTM (main part of the code).
+
+Firstly, we initialize a model in Keras. The weights are automatically created using default settings (kernel weights initialized according to Xavier's initialization, recurrent kernel weights initialized as a random orthogonal matrix, bias set to zero). Secondly, we create three custom-made LSTM layers. Thirdly, we create an input to the network. It is a sequence of a pre-defined size of random integers in range 0 to 100. Finally, we start a loop, which computes the result of our custom-made neural network.
+To illustrate the flow of variables for a sample network, which takes batches of two samples, please see figure 3:
+
+{:refdef: style="text-align: center;"}
+
+{: refdef}
+Figure 3: Variable flow through a network. Blue colour indicates internal state change of an LSTM cell
+
+For every batch, when all samples have passed through the architecture, the last sample enters the dense layer. This results in the final output for the given batch. Additionally, the state of every LSTM layer is reset. This is to simulate what happens in Keras after each batch has been processed. By default, when defining an [LSTM layer](https://keras.io/layers/recurrent/#lstm), the argument stateful= False. If it were True,
+
+> the last state for each sample a batch would be used as initial state for the first in the following batch.
+
+In our case, for every new batch the internal state of every LSTM cell is being reset.
+Now every output $$y$$ returned by a given batch is being appended to the list output_array. This structure holds results returned by our network for every batch of observations. Having all results saved to one list, we may now compare our solution with the one returned by Keras.
+
+## Comparison and summary
+
+We run the code with the specified parameters. One can immediately observe, that by playing with the parameters (increasing the number of timesteps, batches and layers), we radically increase the runtime. In practice it is much more efficient to do the prediction (forward propagation) step directly in Keras. In the end, smart implementation aces our sluggish for-loops out. Our complicated and time-consuming implementation may be wrapped up by a single line of code in Keras:
+
+> model.predict (x)
+
+Let's take a look at the results:
+
+{:refdef: style="text-align: center;"}
+
+{: refdef}
+Figure 4: Results from our implementations and Keras overlap tightly
+
+result_custom = [-0.0865001, -0.0895177, -0.0988678, ... ]
+
+result_keras = [-0.0865001, -0.0895177, -0.0988678, ...]
+
+
+We see that our implementation and results returned by Keras match very accurately (up to eight decimal places)!
+This is only a basic breakdown of an basic LSTM model. It has simple, numerical data with a single feature as an input. Still, the code should give a good insight (a glimpse under the hood) into the mathematical operations behind LSTMs.
+
+## The full code in Python
+
+For condensed, full code please visit my [github](https://github.com/dtransposed/dtransposed-blog-codes/blob/master/Numpy%20implementation%20of%20LSTM%20neural%20networks.py).
+
+Source of the cover image: http://www.partservice.co.uk
diff --git a/_posts/2018-12-31-Best-of-GANs-2018 (Part 1 out of 2).md b/_posts/2018-12-31-Best-of-GANs-2018 (Part 1 out of 2).md
new file mode 100644
index 0000000000..20a8ccd5e4
--- /dev/null
+++ b/_posts/2018-12-31-Best-of-GANs-2018 (Part 1 out of 2).md
@@ -0,0 +1,175 @@
+---
+layout: post
+title: "The best of GAN papers in the year 2018"
+author: "Damian Bogunowicz"
+categories: blog
+tags: [computer vision, neural networks, generative adversarial networks]
+image: gan.jpg
+---
+This year I had a great pleasure to be involved in a research project, which required me to get familiar with a substantial number of publications from the domain of deep learning for computer vision. It allowed me to take a deep dive into the field and I was amazed by the progress done in the last 2-3 years. It is truly exciting and motivating how all different subfields such as image inpainting, adversarial examples, super-resolution or 3D reconstruction have greatly benefited from the recent advances. However, there is one type of neural networks, which has earned truly massive amounts of hype (in my humble opinion definitely for a reason)- __Generative Adversarial Networks__ (GANs). I can agree that those models are fascinating and I am always on a lookout for some new GAN ideas.
+
+Inspired by this [very modest reddit discussion](https://www.reddit.com/r/MachineLearning/comments/a8th4o/d_what_are_best_papers_regarding_gans_for_2018/), I have decided to make a quick overview of the most interesting publications from 2018 regarding GANs. The list is highly subjective - I have chosen research papers which were not only state-of-the-art, but also cool and highly enjoyable. In this first chapter I will discuss three publications. By the way, if you are interested in older GAN papers, [this article](https://medium.com/nurture-ai/keeping-up-with-the-gans-66e89343b46) may be helpful. One of the papers mentioned by the author even made it to my top list.
+
+1. __GAN Dissection: Visualizing and Understanding Generative Adversarial Networks__ - given the amount of hype around GANs, it is obvious that this technology, sooner or later, would be used commercially. However, because we know so little about their inner mechanism, I think that it remains difficult to create a reliable product. This work takes a huge leap towards the future, where we are able to truly control GANs. Definitely check out their great interactive demo, the results are stunning!
+2. __A Style-Based Generator Architecture for Generative Adversarial Networks__ - NVIDIA research team regularly comes up with trail-blazing concepts (great [image inpainting paper from 2018](https://www.youtube.com/watch?v=gg0F5JjKmhA), quite recent demo of using [neural networks for graphics rendering](https://www.youtube.com/watch?time_continue=2&v=ayPqjPekn7g)). This paper is no exception, plus the video which shows their results is simply mesmerising.
+3. __Evolutionary Generative Adversarial Networks__ - this is a really readable and simply clever publication. Evolutionary algorithms together with GAN - this is bound to be cool.
+
+
+## [GAN Dissection: Visualizing and Understanding Generative Adversarial Networks](https://arxiv.org/pdf/1811.10597.pdf)
+
+### Details
+The paper has been submitted on 26.11.2018. The authors have created a great [project website with interactive demo](https://gandissect.csail.mit.edu/).
+
+### Main idea:
+
+GANs have undoubtedly proven how powerful the deep neural networks are. There is something beautiful about the way a machine learns to generate stunning, high resolution images as if it understood the world like we do. But, just like the rest of those wonderful statistical models, their biggest flaw is the lack of interpretability.
+This research makes a very important step towards understanding GANs. It allows us to find units in the generator that a "responsible" for generation of certain objects, which belong to some class $$c$$. The authors claim, that we can inspect a layer of the generator and find a subset of it's units which cause the generation of $$c$$ objects in the generated image. The authors search for the set of "causal" units for each class by introducing two steps: dissection and intervention. Additionally, this is probably the first work, which provides systematic analysis for understanding of the GANs' internal mechanisms.
+
+### The method:
+
+A generator $$G$$ can be viewed as a mapping from a latent vector $$\textbf{z}$$ to an generated image $$\textbf{x} = G(\textbf{z})$$ . Our goal is to understand the $$\textbf{r}$$, an internal representation, which is an output from particular layer of the generator $$G$$.
+
+$$\textbf{x}=G(\textbf{z})=f(\textbf{r})$$
+
+We would like to inspect $$\textbf{r}$$ closely, with respect to objects of the class $$c$$. We know that $$\textbf{r}$$ contains an encoded information about the generation of those particular objects. Our goal is to understand how is this information encoded internally. The authors claim that there is a way to extract those units from $$\textbf{r}$$, which are being responsible for generation of class $$c$$ objects.
+
+$$\textbf{r}_{\mathbb{U},P} = (\textbf{r}_{U,P},\textbf{r}_{\bar{U},P})$$
+
+Here, $$\mathbb{U}=(U,\bar{U})$$ is a set of all units in the particular layer, $$U$$ are units of interest (causal units) and $$P$$ are pixel locations.
+The question is, how to perform this separation? The authors propose two steps which are a tool to understand the GAN black-box. Those are dissection and intervention.
+
+{:refdef: style="text-align: center;"}
+
+{: refdef}
+ Dissection measures agreement between a unit $$u$$ and a class $$c$$
+
+__Dissection__ - we want to identify those interesting classes, which have an explicit representation in $$\textbf{r}$$. This is done by basically comparing two images. We obtain the first image by computing $$\textbf{x}$$, and then running in through a semantic segmentation network. This would return pixel locations $$\textbf{s}_{c}(\textbf{x})$$ corresponding to the class of interest (e.g. trees). The second image is being generated by taking $$\textbf{r}_{u,P}$$, upsampling it so it matches the dimension of $$\textbf{s}_c(\textbf{x})$$ and then thresholding it to have a hard decision on which pixels are being "lit" by this particular unit. Finally we calculate spatial agreement between both outputs. The higher the value, the higher the causal effect of a unit $$u$$ on a class $$c$$. By performing this operation for every unit, we should eventually find out, which classes have an explicit representation in the structure of $$\textbf{r}$$.
+
+{:refdef: style="text-align: center;"}
+
+{: refdef}
+ Intervention measures the causal effect of a set of units U on a class $$c$$
+
+__Intervention__ - at this point we have identified the relevant classes. Now, we attempt to find the best separation for every class. This means that on one hand we ablate (suppress) unforced units, hoping that the class of interest would disappear from the generated image. On the other hand, we amplify their influence of causal units on the generated image. This way we can learn how much they contribute to the presence of the class of interest $$c$$. Finally, we segment out the class $$c$$ from both images and make a comparison. The less agreement between the semantic maps, the better. This means that on one image we have completely ‘tuned out’ the influence of trees, while the second image contains solely a jungle.
+
+### Results:
+
+
+{:refdef: style="text-align: center;"}
+{:height="80%" width="80%"}
+{: refdef}
+ a) images of churches generated by the Progressive GAN, b) given the pre-trained Progressive GAN we identify the units responsible for generation of class "trees", c) we can either suppress those units to "erase" trees from images..., d) amplify the density of trees in the image
+
+The results show that we are on a good track to understand the internal concepts of a network. Those insights can help us improve the network's behavior. Knowing which features of the image come from which part of the neural network is very valuable for interpretation, commercial use and further research.
+
+{:refdef: style="text-align: center;"}
+
+{: refdef}
+ a) for debugging purposes, we can identify those units which are introducing artifacts... , b) and c) and turn them off to "repair" the GAN
+
+One problem which could be tackled are visual artifacts in the generated images. Even a well-trained GAN can sometimes generate a terribly unrealistic image and the causes of these mistakes have been previously unknown. Now we may relate those mistakes with sets of neurons that cause the visual artifacts. By identifying and suppressing those units, one can improve the the quality of generated images.
+
+By setting some units to the fixed mean value e.g. for doors, we can make sure that the doors will be present somewhere in the image. Naturally, this cannot violate the learned statistics of the distribution (we cannot force doors to appear in the sky). Another limitation comes from the fact, that some objects are so inherently linked to some locations, that it is impossible to remove them from the image. As an example: one cannot simply remove chairs from a conference hall, only reduce their density or size.
+
+
+## [A Style-Based Generator Architecture for Generative Adversarial Networks](https://arxiv.org/pdf/1812.04948.pdf)
+
+### Details
+The paper has been submitted on 12.12.2018. The authors assure that the code is to be released soon. Additionally, for people who would like to read more about this method but do not want to read the paper itself, there has been a [nice summary](https://towardsdatascience.com/explained-a-style-based-generator-architecture-for-gans-generating-and-tuning-realistic-6cb2be0f431) published in a form of a blog post just two days ago.
+
+### Main idea:
+
+This work proposes an alternative view on GAN framework. More specifically, it draws inspiration from the style-transfer design to create a generator architecture, which can learn the difference between high-level attributes (such as age, identity when trained on human faces or background, camera viewpoint, style for bed images) and stochastic variation (freckles, hair details for human faces or colours, fabrics when trained on bed images) in the generated images. Not only it learns to separate those attributes automatically, but it also allows us to control the synthesis in a very intuitive manner.
+
+
+Supplementary video with the overview of the results.
+
+### The method:
+
+{:refdef: style="text-align: center;"}
+{:height="80%" width="80%"}
+{: refdef}
+
+Traditional GAN architecture (left) vs Style-based generator (right). In the new framework we have two network components: mapping network $$f$$ and synthesis network $$g$$. The former maps a latent code to an intermediate latent space $$\mathcal{W}$$, which encodes the information about the style. The latter takes the generated style and gaussian noise to create new images. Block "A" is a learned affine transform, while "B" applies learned per-channel scaling factors to the noise input.
+
+In the classical GAN approach, the generator takes some latent code as an input and outputs an image, which belongs to the distribution it has learned during the training phase. The authors depart from this design by creating a style-based generator, comprised of two elements:
+1. A fully connected network, which represents the non-linear mapping $$f:\mathcal{Z} \rightarrow \mathcal{W}$$
+2. A synthesis network $$g$$.
+
+__Fully connected network__ - By transforming a normalized latent vector $$\textbf{z} \in \mathcal{Z}$$, we obtain an intermediate latent vector $$\textbf{w} = f(\textbf{z})$$. The intermediate latent space $$\mathcal{W}$$ effectively controls the style of the generator. As a side note, the authors make sure to avoid sampling from areas of low density of $$\mathcal{W}$$. While this may cause loss of variation in $$\textbf{w}$$, it is said to ultimately result in better average image quality.
+Now, a latent vector $$\textbf{w}$$ sampled from intermediate latent space is being fed into the block "A" (learned affine transform) and translated into a style $$\textbf{y} =(\textbf{y}_{s},\textbf{y}_{b})$$. The style is finally injected into the synthesis network through [adaptive instance normalization](https://arxiv.org/abs/1703.06868) (AdaIN) at each convolution layer. The AdaIN operation is defined as:
+
+$$AdaIN(\textbf{x}_i,\textbf{y})=\textbf{y}_{s,i}\frac{\textbf{x}_i-\mu(\textbf{x}_i)}{\sigma(\textbf{x}_i)}+\textbf{y}_{b,i}$$
+
+__Synthesis network__ - AdaIN operation alters each feature map $$\textbf{x}_{i}$$ by normalizing it, and then scaling and shifting using the components from the style $$\textbf{y}$$. Finally, the feature maps of the generator are also being fed a direct means to generate stochastic details - explicit noise input - in the form of single-channel images containing uncorrelated Gaussian noise.
+
+To sum up, while the explicit noise input may be viewed as a "seed" for the generation process in the synthesis network, the latent code sampled from $$\mathcal{W}$$ attempts to inject a certain style to an image.
+
+### Results:
+The authors revisit NVIDIA's architecture from 2017 [Progressive GAN](https://arxiv.org/abs/1710.10196). While they hold on to the majority of the architecture and hyperparameters, the generator is being "upgraded" according to the new design. The most impressive feature of the paper is style mixing.
+
+{:refdef: style="text-align: center;"}
+{:height="100%" width="100%"}
+{: refdef}
+ Visualising the effects of style mixing. By having an image produced by one latent code (source), we can override a subset of the features of another image (destination). Here, we override layers corresponding to coarse spatial resolutions (low resolution feature maps). This way we influence high-level traits of the destination image.
+
+The novel generator architecture gives the ability to inject different styles to the same image at various layers of the synthesis network. During the training, we run two latent codes $$\textbf{z}_{1}$$ and $$\textbf{z}_2$$ through the mapping network and receive corresponding $$\textbf{w}_1$$ and $$\textbf{w}_2$$ vectors.
+The image generated purely by $$\textbf{z}_1$$ is known as the destination. It is a high-resolution generated image, practically impossible to distinguish from a real distribution. The image generated only by injecting $$\textbf{z}_2$$ is being called a source. Now, during the generation of the destination image using $$\textbf{z}_1$$, at some layers we may inject the $$\textbf{z}_2$$ code. This action overrides a subset of styles present in the destination with those of the source. The influence of the source on the destination is controlled by the location of layers which are being "nurtured" with the latent code of the source. The lower the resolution corresponding to the particular layer, the bigger the influence of the source on the destination. This way, we can decide to what extent we want to affect the destination image:
+- coarse spatial resolution (resolutions $$4^2 - 8^2$$) - high level aspects (such as hair style, glasses or age)
+- middle styles resolution (resolutions$$16^2 - 32^2$$) - smaller scale facial features (hair style details, eyes)
+- fine resolution resolutions (resolutions $$64^2 - 1024^2$$) - just change small details such as hair colour, tone of skin complexion or skin structure
+
+The authors apply their method further to images of cars, bedrooms and even cats, with stunning, albeit often surprising results. I am still puzzled why a network decides to affect the positioning of paws in cat images, but does not care about rotation of wheels in car images...
+
+{:refdef: style="text-align: center;"}
+
+{: refdef}
+ What I find really amazing - this framework can be further applied to different datasets, such as images of cars and bedrooms
+
+
+## [Evolutionary Generative Adversarial Networks](https://arxiv.org/abs/1803.00657)
+
+### Details
+The paper has been submitted on 1.03.2018.
+
+### Main idea:
+In the classical setting GANs are being trained by alternately updating a generator and discriminator using back-propagation. This two-player minmax game is being implemented by utilizing the cross-entropy mechanism in the objective function.
+The authors of E-GAN propose the alternative GAN framework which is based on evolutionary algorithms. They restate loss function in form of an evolutionary problem. The task of the generator is to undergo constant mutation under the influence of the discriminator. According to the principle of "survival of the fittest", one hopes that the last generation of generators would "evolve" in such a way, that it learns the correct distribution of training samples.
+
+### The method:
+
+{:refdef: style="text-align: center;"}
+{:height="100%" width="100%"}
+{: refdef}
+The original GAN framework (left) vs E-GAN framework (right). In E-GAN framework a population of generators $$G_{\theta}$$ evolves in a dynamic environment - the discriminator $$D$$. The algorithm involves three phases: variation, evaluation and selection. The best offsprings are kept for next iteration.
+
+An evolutionary algorithm attempts to evolve a population of generators in a given environment (here, the discriminator). Each individual from the population represents a possible solution in the parameter space of the generative network. The evolution process boils down to three steps:
+
+1. Variation: A generator individual $$G_{\theta}$$ produces its children $$G_{\theta_{0}}, G_{\theta_{1}}, G_{\theta_{2}}, ...$$ by modifying itself according to some mutation properties.
+2. Evaluation: Each child is being evaluated using a fitness function, which depends on the current state of the discriminator
+3. Selection: We assess each child and decide if it did good enough in terms of the fitness function. If yes, it is being kept, otherwise we discard it.
+
+Those steps involve two concepts which should be discussed in more detail: mutations and a fitness function.
+
+__Mutations__ - those are the changes introduced to the children in the variation step. There are inspired by original GAN training objectives. The authors have distinguished three, the most effective, types of mutations. Those are minmax mutation (which encourages minimization of Jensen-Shannon divergence), heuristic mutation (which adds inverted Kullback-Leibler divergence term) and least-squares mutation (inspired by [LSGAN](https://arxiv.org/abs/1611.04076)).
+
+__Fitness function__ - in evolutionary algorithm a fitness function tells us how close a given child is to achieving the set aim. Here, the fitness function consists of two elements: quality fitness score and diversity fitness score. The former makes sure, that generator comes up with outputs which can fool the discriminator, while the latter pays attention to the diversity of generated samples.
+So one hand, the offsprings are being taught not only to approximate the original distribution well, but also to remain diverse and avoid the mode collapse trap.
+
+The authors claim that their approach tackles multiple, well-known problems. E-GANs not only do better in terms of stability and suppressing mode collapse, it also alleviates the burden of careful choice of hyperparameters and architecture (critical for the convergence).
+Finally, the authors claim the E-GAN converges faster that the conventional GAN framework.
+
+### Results:
+The algorithm has been tested not only on synthetic data, but also against CIFAR-10 dataset and Inception score. The authors have modified the popular GAN methods such as [DCGAN](https://arxiv.org/abs/1511.06434) and tested them on real-life datasets. The results indicate, that E-GAN can be trained to generate diverse, high-quality images from the target data distribution. According to the authors, it is enough to preserve only one child in every selection step to successfully traverse the parameter space towards the optimal solution. I find this property of E-GAN really interesting. Moreover, by scrutinizing the space continuity, we can discover, that E-GAN has indeed learned a meaningful projection from latent noisy space to image space. By interpolating between latent vectors we can obtain generated images which smoothly change semantically meaningful face attributes.
+
+{:refdef: style="text-align: center;"}
+{:height="100%" width="100%"}
+{: refdef}
+Linear interpolation in latent space $$G((1-\alpha)\textbf{z}_1+\alpha\textbf{z}_2)$$. The generator has learned distribution of images from CelebA dataset. $$\alpha = 0.0$$ corresponds to generating an image from vector $$\textbf{z}_1$$, while $$\alpha = 1.0$$ means that the image came from vector $$\textbf{z}_2$$. By altering alpha, we can interpolate in latent space with excellent results.
+
+All the figures are taken from the publications, which are being discussed in my blog post
+
+Source of the cover image: https://www.saatchiart.com
+
+
+
diff --git a/_posts/2019-01-25-Best-of-GANs-2018 (Part 2 out of 2).md b/_posts/2019-01-25-Best-of-GANs-2018 (Part 2 out of 2).md
new file mode 100644
index 0000000000..94661a9708
--- /dev/null
+++ b/_posts/2019-01-25-Best-of-GANs-2018 (Part 2 out of 2).md
@@ -0,0 +1,196 @@
+---
+layout: post
+title: "The best of GAN papers in the year 2018 part 2"
+author: "Damian Bogunowicz"
+categories: blog
+tags: [computer vision, neural networks, generative adversarial networks]
+image: gan2.jpg
+---
+The cover image by courtesy of [Juli Odomo](https://www.odomojuli.com).
+
+As a follow-up to my previous post, where I discussed three major contributions to GANs (Generative Adversarial Networks)
+domain, I am happy to present another three interesting research papers from 2018. Once again, the order is purely random and the choice
+very subjective.
+
+1. __Large Scale GAN Training for High Fidelity Natural Image Synthesis__ - DeepMind's BigGAN uses the power of hundreds of cores of a Google TPU v3 Pod to create high-resolution images on a large scale.
+2. __The relativistic discriminator: a key element missing from standard GAN__ - the author proposes to improve the fundamentals of GANs by introducing an improved discriminator.
+3. __ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks__ - the [Super-Resolution GAN (SRGAN)](https://arxiv.org/pdf/1609.04802.pdf) from 2017 was one the best networks which map low-resolution images to their high-resolution equivalents. This work improves SRGAN through several interesting tricks. Some may say that this is just incremental improvement, but the implemented ideas are really clever!
+
+
+
+## [Large Scale GAN Training for High Fidelity Natural Image Synthesis](https://arxiv.org/pdf/1809.11096.pdf)
+
+### Details
+The paper has been submitted on 28.09.2018. You can easily [run BigGAN](https://colab.research.google.com/github/tensorflow/hub/blob/master/examples/colab/biggan_generation_with_tf_hub.ipynb) using Google Collab.
+
+### Main idea:
+
+{:refdef: style="text-align: center;"}
+
+{: refdef}
+ One generated image and its nearest neighbours from ImageNet dataset. Which image is artificially generated? The burger in the top left corner...
+
+Even though the progress in the domain of GANs is impressive, image generation using Deep Neural Networks remains difficult. Despite the great interest in this field, I believe that there is a lot of untapped potential when it comes to generating images. One of the ways to track the progress of GANs and measure their quality is [Inception Score](https://arxiv.org/abs/1606.03498) (IS). This metric considers both quality of generated images as well as their diversity. Using the example of 128x128 images from [ImageNet dataset](http://www.image-net.org/) as our baseline, the real images from the dataset achieve $$IS = 233$$. While the state-of-the-art was estimated at $$IS = 52.5$$, BigGAN has set the bar at $$IS = 166.3$$! How is this possible?
+The authors show how GANs can benefit from training at large scale. Leveraging the immense computational resources allows for dramatic boost of performance, while keeping the training process relatively stable. This allows for creation of high resolution images (512x512) of unparalleled quality. Among many clever solutions to instability problem, this paper also introduces the truncation trick, which I have already discussed in part 1 of my summary (__A Style-Based Generator Architecture for Generative Adversarial Networks__).
+
+### The method:
+
+In contrast to other papers I evaluated, the significance of this research does not come from any significant modification to the GAN framework. Here, the major contribution comes from using massive amounts of computational power available (courtesy of Google) to make the training more powerful. This involves using larger models (4-fold increase of network parameters with respect to prior art) and larger batches (increase by almost an order of magnitude). This turns out to be very beneficial:
+1. Using large batch sizes (2048 images in one batch) allows every batch to cover more modes. This way the discriminator and generator benefit from better gradients.
+2. Doubling the width (number of channels) in every layer increases the capacity of the model and thus contributes to much better performance. Interestingly, increasing the depth has negative influence on the performance.
+3. Additional use of class embeddings accelerates the training procedure. Using class embeddings means conditioning the output of the generator on dataset's class labels.
+4. Finally, the method also benefits from hierarchical latent spaces - injecting the noise vector $$\textbf{z}$$ into multiple layers rather then solely at the initial layer. This not only improves performance of the network, but also accelerates the training process.
+
+### Results:
+
+Large scale training allows for superior quality of generated images. However, it comes with its own challenges, such as instability. The authors show, that even though the stability can be enforced through regularization methods (especially on the discriminator), the quality of the network is bound to suffer. The clever workaround is to relax the constraints on the weights and allow for training to collapse at the later stages. Then, we may apply the early stopping technique to pick the set of weights just before the collapse. Those weights are usually sufficiently good to achieve impressive results.
+
+{:refdef: style="text-align: center;"}
+
+{: refdef}
+ Great interpolation ability in both class and latent space confirms that the model does not simply memorize data. It is capable of coming up with its own, incredible inventions!
+
+{:refdef: style="text-align: center;"}
+
+{: refdef}
+ While it may be tempting to cherry-pick the best results, the authors of the paper also comment on the failure cases. While easy classes such as a) allow for seamless image generation, difficult classes b) are tough for the generator to reproduce. There are many factors which influence this phenomenon e.g. how well the class is represented in the dataset or how sensitive our eyes are to particular objects. While small flaws in the landscape image are unlikely to draw our attention, we are very vigilant towards "weird" human faces or poses.
+
+## [The relativistic discriminator: a key element missing from standard GAN](https://arxiv.org/pdf/1807.00734.pdf)
+
+### Details
+The paper has been submitted on 02.06.2018. One of the reasons why this research is impressive is the fact, that it seems that the whole job was done by one person. The author thought about everything - writing a short blog post about [her invention](https://ajolicoeur.wordpress.com/relativisticgan/), publishing well documented [source code](https://github.com/AlexiaJM/RelativisticGAN) and starting an interesting [discussion on reddit](https://www.reddit.com/r/MachineLearning/comments/8vr9am/r_the_relativistic_discriminator_a_key_element/).
+
+### Main idea:
+
+In standard generative adversarial networks, the discriminator $$D$$ estimates the probability of the input data being real or not. The generator $$G$$ tries to increase the probability that generated data is real. During training, in every iteration, we input two equal-sized batches of data into the discriminator: one batch comes from a real distribution $$\mathbb{P}$$, the other from fake distribution $$\mathbb{Q}$$.
+This valuable piece of information, that half of the examined data comes from fake distribution is usually not conveyed in the algorithm. Additionally, in standard GAN framework, the generator attempts to make fake images look more real, but there is no notion that the generated images can be actually “more real” then real images. The author claims that those are the missing pieces, which should have been incorporated into standard GAN framework in the first place. Due to those limitations, it is suggested that training the generator should not only increase the probability that fake data is real but also decrease the probability that real data is real. This observation is also motivated by the IPM-based GANs, which actually benefit from the presence of relativistic discriminator.
+
+### The method:
+
+In order to shift from standard GAN into “relativistic” GAN, we need to modify the discriminator. A very simple example of a Relativistic GAN (RGAN) can be conceptualized in a following way:
+
+In __standard formulation__, the discriminator may be a function
+
+$$D(x) = \sigma(C(x))$$
+
+$$x$$ is an image (real or fake), $$C(x)$$ is a function which assigns a score to the input image (evaluates how realistic $$x$$ is) and $$\sigma$$ translates the score into a probability between zero to one. If discriminator receives an image which looks fake, it would assign a very low score and thus low probability, for example:
+$$D(x) = \sigma(-10)=0$$
+On the contrary, real-looking input gives us high score and high probability, for example:
+$$D(x) = \sigma(5)=1$$
+
+Now, in __relativistic GAN__, the discriminator estimates the probability that the real data $$x_r$$ is more realistic then a randomly sampled fake data $$x_f$$:
+
+$$D(\widetilde{x}) = \sigma(C(x_r)-C(x_f))$$
+
+Where $$\widetilde{x} = (x_r,x_f)$$. To make the relativistic discriminator act more globally and avoid randomness when sampling pairs, the author builds up on this concept to create a __Relativistic average Discriminator__ (RaD).
+
+$$\bar{D}(x)=\begin{cases}
+sigma(C(x)-\mathop{\mathbb{E}}_{x_{f}\sim\mathbb{Q}}C(x_{f})), & \text{if $x$ is real}\\
+sigma(C(x)-\mathop{\mathbb{E}}_{x_{r}\sim\mathbb{P}}C(x_{r})), & \text{if $x$ is fake}.
+ \end{cases}$$
+
+This means that whenever the discriminator $$\bar{D}(x)$$ receives a real image, it evaluates how is this image more realistic that the average fake image from the batch in this iteration. Analogously, $$\bar{D}(x)$$ receives a fake image, it is being compared to an average of all real images in a batch. This formulation of relativistic discriminator allows us to indirectly compare all possible combinations of real and fake data in the minibatch, without enforcing quadratic time complexity on the algorithm.
+
+
+### Results:
+
+{:refdef: style="text-align: center;"}
+
+{: refdef}
+The diagram shows an example of the discriminator’s output in standard GAN:
+
+$$P(x_r~ \text{is real}) = \sigma(C(x_r)))$$
+
+and RaD:
+
+$$P(x_r~ \text{is real}|C(x_f)) = \sigma(C(x_r) − C(x_f)))$$
+
+$$x_f$$ are dogs images while $$x_r$$ are pictures of bread.
+I think that this example gives a very good intuitive understanding of the relativistic discriminator.
+
+{:refdef: style="text-align: center;"}
+
+{: refdef}
+Artificially created cats (128x128 resolution), the output from RaLSGAN. Not only the standard LSGAN produces less realistic images, it is also much more unstable.
+
+I have the impression that this paper may start a new trend - using relativistic discriminator in different GAN problems. The experiments indicate, that the approach may help with many problems such as stability or inferior image quality. It may also accelerate the networks' training speed. I really love the fact, that the author has questioned a very fundamental element of the GAN architecture. It is exciting to see that there are already state-of-the-art publications which take advantage of relativistic discriminators (even though this paper came out in June). An example of such an architecture is...
+
+
+## [ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks](https://arxiv.org/pdf/1809.00219.pdf)
+
+### Details
+The paper has been submitted on 17.09.2018. The code is available publicly [on github](https://github.com/xinntao/ESRGAN). Fun fact: several people have used ESRGAN to improve textures in some old games e.g [Morrowind](https://www.youtube.com/watch?v=PupePmY9OA8&t=184s), [Doom 2](https://www.youtube.com/watch?v=u9S8lnGqKkg&t=64s) or [Return to Castle Wolfenstein](https://www.youtube.com/watch?v=uyRfptKJutU).
+
+### Main idea:
+
+{:refdef: style="text-align: center;"}
+
+{: refdef}
+Output from SRGAN versus output from ESRGAN, with ground truth as reference. The generated HR image is four times larger than the LR input. The ESRGAN outperforms its predecessor in sharpness and details.
+
+The SRGAN was 2017's state of the art invention in the domain of super-resolution (SR) algorithms. It's task was to take a low resolution (LR) image and output its high resolution (HR) representation. The first optimization target of the network was to __minimize the mean squared error (MSE)__ between recovered HR image and the ground truth. This is equivalent to maximizing peak signal-to-noise ratio (PSNR), which is a common measure used to evaluate SR algorithms. However, this favours overly smooth textures. That is why the second goal of the network was to __minimize perceptual loss__. This helps in capturing texture details and high frequency content.
+As the result, the network has learned to find a sweet spot between those two contradictory goals. By forcing the GAN to keep track of goals, the network produces high quality HR representation of the LR input.
+One year later, the SRGAN method (created by the scientists from Twitter), has been improved by Chinese and Singaporean researchers. The new network can create even more realistic textures with reduced number of artifacts. This has been achieved through several clever tricks.
+
+{:refdef: style="text-align: center;"}
+
+{: refdef}
+SRGAN is based on the ResNet architecture. Even though ESRGAN has similar design, it introduces some changes to Basic Blocks - shifts from Residual Blocks to Residual in Residual Dense Blocks (RRDB) - for better performance.
+
+### The method:
+
+The ESRGAN takes SRGAN and employs several clever tricks to improve the quality of the generated images. Those four improvements are:
+1. Introducing changes to the generator's architecture (switching from Residual Blocks to RRDB, removing batch normalization).
+2. Replacing an ordinary discriminator with the relativistic discriminator (as described in the previously discussed paper).
+3. Regarding perceptual loss, using feature maps before activation, rather then post-activation.
+4. Pre-training the network to first optimize for PSNR and then fine tune it with the GAN.
+
+{:refdef: style="text-align: center;"}
+
+{: refdef}
+First, we remove batch normalization from the network. Secondly, we introduce RRDB which combines multi-level residual network and dense connections. This gives the network higher capacity to capture information.
+
+__Introducing major changes to the network architecture__ - while the generator in the original SRGAN was using residual blocks, the ESRGAN additionally benefits from dense connections (as proposed by the authors of [DenseNet](https://arxiv.org/abs/1608.06993)). This not only allows for increased depth of the network, but also enforces more complex structure. This way the network can learn finer details. Additionally, ESRGAN does not use batch normalization. Learning how normalize the data distribution between layers is a general practice in many Deep Neural Networks. However, in case of SR algorithms (especially the ones which use GANs), it tends to introduce unpleasant artifacts and limits the generalization ability. Removing batch normalization improves the stability and reduces computational cost (less parameters to learn).
+
+
+__Replacing an ordinary discriminator with relativistic disciminator__ - it is really interesting that the idea of relativistic discriminator has been already employed by the community shortly after the paper has been published. Using the Relativistic average Discriminator allows the network not only to receive gradients from generated data, but also from the real data. This improves the quality of edges and textures.
+
+__Revisit perceptual loss__ - the perceptual loss attempts to compare perceptual similarity between the reconstructed image $$G(x_{LR})$$ and the ground truth image $$x_{HR}$$. By running both inputs through the pre-trained VGG network, we receive their representation in form of feature maps after j-th convolution and activation $$\phi(G(x_{LR}))$$ and $$\phi(x_{HR})$$. One of the tasks of the SRGAN was to minimize the difference between those representations. This is still the case in ESRGAN. However, we take the representation after j-th convolution but __before activation__.
+
+{:refdef: style="text-align: center;"}
+
+{: refdef}
+As we go deeper, the layers after activation tend to give us much less information. This results in weak supervision and inferior performance. Therefore, it is more beneficial to use pre-activation feature maps.
+
+{:refdef: style="text-align: center;"}
+
+{: refdef}
+Additionally, post-activation feature maps also cause inconsistent reconstructed brightness compared with the GT image.
+
+__Network interpolation__ - as I have mentioned before, there are two goals which the algorithm tries to achieve. This is not only perceptual similarity between generated image and ground truth, but also lowest possible PSNR. This why initially the network is being trained to minimize PSNR (using L1 loss). Then, the pre-trained network is being used to initialize the generator. This not only allows to avoid undesired local minima for the generator, but also provides the discriminator with quite good super-resolved images from the start.
+The authors state that the best results can be obtained through interpolation between the weights of the initial network (after PSNR optimization) and final network (after GAN training). This allows to control the PSNR versus perceptual similarity trade-off.
+
+### Results:
+
+The experiments are similar to the ones conducted on SRGAN. The goal is to scale the LR image by the factor of 4 and obtain a good quality SR image of size 128x128.
+
+{:refdef: style="text-align: center;"}
+
+{: refdef}
+At the moment, ESRGAN is the state of the art technique for super-resolution.
+
+{:refdef: style="text-align: center;"}
+
+{: refdef}
+Interpolating between two contradictory goals: minimizing PSNR or maximizing perceptual similarity
+
+The authors have tested their network at the PIRM-SR challenge, where the ESRGAN has won the first place with the best perceptual index.
+
+Those were my __six favourite research papers__, which have marry GANs and Computer Vision. If you would like to add or change something on this list, I would love to hear about your candidates! Have a great 2019 everybody!
+
+All the figures are taken from the publications, which are being discussed in my blog post
+
+
+
+
+
diff --git a/_posts/2019-03-10-GEAR.md b/_posts/2019-03-10-GEAR.md
new file mode 100644
index 0000000000..127da5a3ff
--- /dev/null
+++ b/_posts/2019-03-10-GEAR.md
@@ -0,0 +1,214 @@
+---
+layout: post
+title: "Project - Reinforcement Learning with Unity 3D: G.E.A.R"
+author: "Damian Bogunowicz"
+categories: blog
+tags: [computer vision, neural networks, robotics, reinforcement learning, unity]
+image: GEAR-cover.png
+---
+
+Over the course of the last several months I was working on a fantastic project organized by the [Chair for Computer Aided Medical Procedures & Augmented Reality](http://campar.in.tum.de/WebHome). As a result, together with a team of students, we have developed a prototype of an autonomous, intelligent agent for garbage collection. The idea has been born during a workshop organized by PhD students from the Technical University of Munich. This was start of a great journey, which required us to use our knowledge from the fields of Computer Vision, Deep Reinforcement Learning and Game Development to create a functional simulation of our robot, G.E.A.R - Garbage Evaporating Autonomous Robot.
+This blog post presents the details of the endeavour. Naturally, if you would like to tinker with the G.E.A.R or contribute further to our project, feel free to visit the repository: [Reinforcement Learning With Unity-G.E.A.R](https://github.com/dtransposed/Reinforcement-Learning-With-Unity-G.E.A.R).
+
+
+## Table of Contents
+
+1. [Project overview](#project-overview)
+ 1. [Motivation](#motivation)
+ 2. [Agent and Environment](#agent-and-environment)
+ 3. [Perception, Cognition, Action](#perception-cognition-action)
+ 4. [Punishments and Rewards](#punishments-and-rewards)
+2. [Algorithms](#algorithms)
+ 1. [Semantic Segmentation](#semantic-segmentation)
+ 2. [Brain of an Agent](#brain-of-an-agent)
+3. [Presentation of Solutions](#presentation-of-solutions)
+ 1. [PPO](#ppo)
+ 2. [PPO with Segmentation Network](#ppo-with-segmentation-network)
+ 3. [Behavioral Cloning](#behavioral-cloning)
+ 4. [Heuristic](#heuristic)
+4. [Summary and Possible Improvements](#summary-and-possible-improvements)
+
+## Project overview
+
+### Motivation:
+
+No matter where you come from - the first things which comes to mind when you hear about Munich, the capital of Bavaria, is Oktoberfest. The famous beer festival is deeply rooted in the Bavarian culture. The scale of the event is impressive: the amount of people which visit Munich in autumn every year, the litres of beer drank by the visitors and the money which exchanges hands during the Oktoberfest - those numbers can be hardly compared to any other event in the world. Clearly, this means that one could find a financial incentive to be a part of this huge celebration. Additionally, as an engineer and researcher, my task is to solve (meaningful) problems.
+In this case, I could instantly spot one issue...
+
+Oktoberfest is indeed exciting and fun for the participants. However, we tend to turn blind eye to things, which happen after the celebration is over. One of those things are the massive amounts of garbage generated each day of the Oktoberfest. At 10pm, when the visitors leave the Wiesn (the area where the Oktoberfest takes place), an army of sanitation workers rushes to clean up __the garbage generated by a platoon of drunk guests__. So far, this process is pretty much done by human workers. How about automating the task? Frankly speaking, this is not only a mundane and unfulfilling job. This is also a task which could be done much more efficient by robots. Especially by a hive of intelligent, autonomous robots, which can work 24/7. Such a collective of small robotic workers could accelerate the process of garbage collection by orders of magnitude, while simultaneously being very cost efficient.
+
+{:refdef: style="text-align: center;"}
+
+{:refdef}
+ A swarm of synchronized, autonomous robots is surely capable of outperforming a human workers.
+
+Our first step is to simulate the robot using Unity 3D game engine. We additionally use the Unity Machine Learning Agents Toolkit (ML-Agents) plug-in that enables game scenes to serve as environments for training intelligent agents. This allows the user to train algorithms using reinforcement learning, imitation learning, neuroevolution, or other machine learning methods through a simple-to-use Python API.
+
+### Agent and Environment:
+
+{:refdef: style="text-align: center;"}
+
+{:refdef}
+
+The setup for the agent is a Bavarian-themed room. The goal of a robot is to explore the environment and learn the proper reasoning (policy), which we indirectly enforce on G.E.A.R through a set of rewards and punishments.
+
+The goal of the robot is:
+- to approach and gather the collectibles (stale loaves of bread, red plastic cups and white sausages).
+- not to collide with static objects (chairs and tables), slamming against the wall or collecting wooden trays (they belong to the owner of a Bavarian tent and should not be collected by the robot for future disposal).
+
+{:refdef: style="text-align: center;"}
+{:height="70%" width="70%"}
+{:refdef}
+
+The robot itself is modelled as a cube, which can roam around the room and collect relevant objects. It's action vector contains three elements, which are responsible for:
+- __translational motion__ (move forward, backward, or remain stationary)
+- __heading angle__ (turn left, right or refuse to rotate)
+- __grabbing state__ (activate or not)
+
+While the first two actions are pretty straightforward, one could ask what "grabbing state" is. Since the creation of an actual mechanism for garbage collection would be not only very time-consuming but also troublesome (Unity 3D is not as accurate as CAD software when it comes to modelling the physics of rigid bodies), we have decided to use a certain heuristic to simulate the collection of items. Every time the robot decides to collect an object, two requirements must be fulfilled:
+1. The object must be close to the front part of the robot (confined within the volume with green edges)
+2. The robot must decide to activate "a grabber". When the grabbing state is activated, the color of the robot changes from white to red.
+
+{:refdef: style="text-align: center;"}
+{:height="70%" width="70%"}
+{:refdef}
+ The object, if it is to be collected, must be confined within the volume in front of the G.E.A.R (green edges).
+
+This heuristic not only allows us to model the behaviour of an agent without an actual mechanical implementation of a grabber, but also allows to observe the reasoning of the agent and debug the behaviour of G.E.A.R.
+
+### Perception Cognition Action
+
+{:refdef: style="text-align: center;"}
+
+{:refdef}
+ Graphical visualization of the perception, cognition and action cycle of G.E.A.R
+
+An intelligent system can be abstracted as an interplay between three systems: perception, cognition and action. In case of G.E.A.R, the __perception__ is handled by an Intel RealSense camera. In every timestep, we simulate the input from the sensor by providing the robot with two pieces of information: an RGB frame as well as depth map. Now __cognition__ comes into play. The RBG input is transformed into semantic segmentation maps which assign a class to every object in the image. This way the robot knows the class of each pixel in the RBG frame. Then the depth and semantic segmentation maps are fused together and analysed by the set of neural networks - the brain of the robot. Finally, the brain outputs a decision about robot's __action__.
+
+### Punishments and Rewards
+
+According to the reinforcement learning paradigm, the robot should be able to learn the proper policy through interaction with the environment and collection of feedback signals. For our agent, those signals are expressed as floats spanning from -1 to 0 (punishments) and from 0 to 1 (rewards).
+
+The proper assignment of punishments and rewards and defining their values is challenging. During the project we have learned two important lessons. Those may not be applicable to all RL project, but should be kept in mind if you struggle with the similar tasks as ours:
+
+__First, try to get "good enough" policy quickly__ - we have noticed, that it is advisable to first present the agent with high rewards for the main goal, while giving only small (or no) feedback signals regarding secondary goals. This way we can quickly achieve a decent, general policy. This can be refined by fine-tuning the punishments and rewards later. This way we avoid being stuck in local minimum early on.
+
+__Curriculum learning is great when the problem is complex__ - it is shown by [Bengio at al. 2009](http://ronan.collobert.com/pub/matos/2009_curriculum_icml.pdf) that when want to learn a complex task, we should start with easier subtasks and gradually increase the difficulty of the assignments. This can be easily implemented in Unity ML-Agents and allows us to solve our learning task by breaking the project down into two subgoals: __roaming the environment in search of garbage__ and __deciding when to activate the grabbing state__.
+
+In the end, we have finished the training with the following set of rewards and punishments enforced on the agent (+++ is a very high reward equivalent to 1 while --- is the biggest punishment of -1) :
+
+Action | Signal (Punishment or Reward) | Comment |
+--------------------- | :-------------------: | :-------------------- |
+Gathering the collectible |$$+++$$| The main goal is to collect the garbage. |
+Moving forward | $$+$$ | Typically assigned in locomotion tasks.|
+Punishment per step | $$-$$ | So that the agent has an incentive to finish the task quickly. |
+Activating the grabbing mechanism | $$-$$ | In the real world, activating the grabber mechanism when unnecessary would be ridiculously energy inefficient. |
+Colliding with an obstacle | $$--$$ | The initial punishment was low, so the robot learns not to strictly avoid the furniture but to manoeuvre between table legs etc. |
+Slamming against a wall | $$--$$ | In rare cases robot can touch the wall, e.g. to pick an object positioned beside it. |
+Collecting a wooden tray | $$---$$ | The robot needs to learn not to collect non-collectible items. |
+
+> The reddit user [Flag_Red](https://www.reddit.com/user/Flag_Red) has pointed out the fact that the punishment per step is in fact redundant. The discount factor in the Bellman's equation makes the agent prefer immidiate rewards to rewards which come in the future. This means that we do not need this particular signal. Thank you for the remark!
+
+Additionally, there are many useful [tips and tricks regarding the training procedure](https://github.com/Unity-Technologies/ml-agents/blob/master/docs/Learning-Environment-Best-Practices.md) suggested by the authors of ML-Agents Toolkit.
+
+## Algorithms
+
+### Semantic Segmentation
+
+{:refdef: style="text-align: center;"}
+
+{:refdef}
+
+The robot itself does not know which object should be collected and which should be avoided. This information is obtained from a network, which maps the RBG image to a semantic segmentation maps. For the purpose of the project, we have created a dataset of 3007 pairs of images - RBG frames (input) and matching semantic segmentation maps (ground truth obtained from Unity 3D custom shader). We have used [Semantic Segmentation Suite](https://github.com/GeorgeSeif/Semantic-Segmentation-Suite) to quickly train the [SegNet](https://arxiv.org/pdf/1511.00561.pdf) (Badrinarayan et al., 2015) model using our data. Even though SegNet is far from state of the art, given its simple structure (easy to debug and modify), relatively uncomplicated domain of the problem (artificial images, simple lightning conditions, repeatable environment) and additional requirements (as little project overhead as possible) it has turned out to be a good choice.
+
+

 +
+ Our SegNet: input, ground truth, prediction.
+
+### Brain of an Agent
+
+The central part of robot's cognition is the brain. This is the part responsible for the agent's decision: given the current state of the world and my policy, which action should I take? To answer this questions, we have decided to employ several approaches:
+
+__Proximal Policy Optimization__ - PPO is current state-of-the-art family of policy gradient methods for reinforcement learning developed by OpenAI. It alternates between sampling data through interaction with the environment and optimizing a “surrogate” objective function using stochastic gradient ascent.
+
+__Behavioral Cloning from Observation__ - this approach frames our problem as supervised learning task. We "play the game" for half an hour in order for agent to clone our behaviour. Given this ground truth, the agent learns the rough desired policy.
+
+Moreover, we have created our own __Heuristic Approach__, which will be explained in the next chapter.
+
+## Presentation of Solutions:
+
+### PPO
+
+
+ The learning process of the agent. We can see that after 24h hours of training G.E.A.R became excellent at it's job.
+
+Our first approach involves training an agent using PPO algorithm. Here, the semantic segmentation information does not come from an external neural network. It is being generated using a shader in Unity, which segments the objects using tags. This means that the agent quickly receives reliable, noise-free information about objects' classes during training. We additionally utilize two more modifications offered by Unity ML-Agents:
+
+- __Memory-enhanced agents using Recurrent Neural Networks__ - this allows the agent not only to act on the current RGBD input, but also "to remember" the last $$n$$ inputs and include this additional information into its reasoning while making decisions. We have observed that this has improved the ability of G.E.A.R to prioritize its actions e.g. the agent may sometimes ignore a single garbage item when it recognizes that there is an opportunity to collect two other items instead (higher reward), but eventually returns to collect the omitted garbage.
+
+- __Using curiosity__ - when we face a problem, where the extrinsic signals are very sparse, the agent does not have enough information to figure out the correct policy. We may endow the agent with a sense of curiosity, which gives the robot an internal reward every time it discovers something surprising and unconventional with regard to its current knowledge. This encourages an agent to explore the world and be more "adventurous". It is hard to say what was the influence of curiosity in our case, but we have noticed that there were several timepoints where the internal reward spiked during training and significantly improved the current policy of an agent.
+
+It took us couple of days of curriculum training to train agent using PPO. We have observed that setting the punishments initially to high, encourages the agent to simply run in circles. This can be avoided by initially allowing the agent to figure out the main goal. Once the robot understands what it is being encouraged to do, we can impose further restraints in form of harsher punishments to fine tune the behaviour of G.E.A.R.
+
+### PPO with Segmentation Network
+
+
+
+ Inference using PPO model with Segmentation Network. Not only is the algorithm much slower (we have several milliseconds delay using the best computer we good get our hands on), but the behaviour of the agent is not entirely correct (SegNet's output is not as accurate as the images produced by the custom shader in Unity).
+
+In real-life application, we could not use the custom shader in Unity 3D. That is why we should train our own model for semantic segmentation. When the model is ready, there are two possibilities to embed the SegNet into the Python API:
+- __Train the brain with SegNet in train time__ - this makes the training extremely time inefficient. Every input frame needs to be segmented by the SegNet which is too computationally expensive for our humble laptops. Additionally, the brain of the agent suffers from the SegNet's imperfect output. On the other hand, this approach makes the implementation of SegNet in Python API quite straightforward.
+- __Train the brain using custom shader and plug in the SegNet during test time__ - this is more time-efficient solution, because SegNet is being used only at inference time. It also allows to train the brain of the agent using noise-free segmented images from the custom shader. Sadly, this requires much more work with Python API, to integrate SegNet post-factum.
+
+Given our limited computational resources and desire to train the brain using perfect data, we have decided to choose the second option.
+
+### Behavioral Cloning
+
+
+
+In this approach agent learns directly from human player. This has several implications: we can train a decent agent in half an hour or so, but it will never be better then a human. This approach may suffice to create an agent which is just good and not excellent in some task (e.g video game AI, where an agent should be weak enough so we can enjoy playing a game). Obviously, G.E.A.R trained using this method is not good enough for our purpose.
+
+
+### Heuristic
+
+
+ Heuristic algorithm in action! On one hand, requires less training and is excellent at recognizing true positives. On the other hand, once a true positive is found, the agent collects it without considering that it may also unintentionally collect a non-collectible item...
+
+While planning the project, we have established that the robot's behaviour consists in essence of two task: approaching the collectible objects and deciding if the garbage should be collected or not. So far, our agent has managed to figure out both assignments on its own. But just for fun (or maybe to accelerate the training process), we can "hard-code" the second objective - deciding if the garbage should be collected or not. The decision about activating the grabbing mechanism is just an output of a simple function, which takes into consideration two factors:
+
+1. The class of the object in front of us (defined by a semantic segmentation map)
+2. The distance of the object from our robot (provided by a depth map)
+
+This function can be easily hard-coded in the following way:
+- From the current depth map, filter out only those pixels which belong to the "collectible" class (overlaying a binary mask over the depth map).
+- Check if the pixel with the highest value is greater than some set threshold.
+- If yes: the collectible object is close enough to G.E.A.R and therefore we might collect it!
+
+
+{:refdef: style="text-align: center;"}
+
+{: refdef}
+ The decision-making behind our heuristic.
+
+## Summary and Possible Improvements
+
+We have created a simulation of an autonomous robot in our custom-made environment using several different approaches.
+Still, in order to turn the prototype into an actual product, which can deliver business value, there are some improvements which should introduced:
+
+__Install the actual mechanism for garbage collection__ - as mentioned before, the mechanical design of the robot should be simulated in detail. This means installing a "shovel" which could seamlessly push the garbage into the "belly" of a robot. As a result, we should also design a clever and efficient way to dispose the set of items once the robot's container becomes full.
+
+__Deploy the algorithm on a machine which can handle real-time semantic segmentation__ - the inference time of the semantic segmentation model turned out to be too slow for real-time simulation. This comes mainly from the limited computing power of our laptops. We could easily improve it not only by using professional, industry-grade graphic cards, but possibly rewriting the code using C++ or (in more extreme cases) introducing weights quantization.
+
+__Transfer the knowledge from simulation to a real robot with RealSense camera__ - the final part of the endeavour would be deployment of the robot in the physical environment. This would mean fine-tuning algorithms by running the robot in the real world. To my best knowledge, the use of reinforcement learning in robotics is still in experimental stage. One of the recent undertakings, which translates the results of the RL robot simulation into physical agents is the [ANYmal](https://www.anybotics.com/) project. We could use similar approaches to move from Unity 3D engine to the actual world. It would be really exciting to explore how G.E.A.R would do in the complex, real-life domain!
+
+{:refdef: style="text-align: center;"}
+
+{: refdef}
+ G.E.A.R team presenting the project at the Centre for Translational Cancer Research (TUM Clinic).
+
+
+
+
+
+
+
diff --git a/_posts/2019-05-16-Alpha-Zero-1.md b/_posts/2019-05-16-Alpha-Zero-1.md
new file mode 100644
index 0000000000..41f5bf2372
--- /dev/null
+++ b/_posts/2019-05-16-Alpha-Zero-1.md
@@ -0,0 +1,178 @@
+---
+layout: post
+title: "Understanding AlphaGo Zero [1/3]:
+ Upper Confidence Bound, Monte Carlo Search Trees and Upper Confidence Bound for Search Trees"
+author: "Damian Bogunowicz"
+categories: blog
+tags: [reinforcement learning, multi-armed bandits, artificial intelligence, game theory]
+image: alpha-zero-one.jpg
+---
+
+Being interested in current trends in Reinforcement Learning I have spent my spare time getting familiar with the most important publications in this field. While doing the research I have stumbled upon the [AlphaGo Zero course](http://www.depthfirstlearning.com/2018/AlphaGoZero) by Depth First Learning group. I love how they structure their courses as self-contained lesson plans focusing on deep understanding of the theory and provide background behind every approach. So far they offer just three courses, but their quality is outstanding. It is also great that they provide related reading for further study. I have decided to follow their AlphaGo Zero course and publish my learnings in form of three blog posts. Every entry will be tightly correlated with the topics from the curriculum. Note that the articles will not follow the order suggested by the authors of the course.
+
+This first entry will discuss the concepts of __Upper Confidence Bound__ (UCB), __Monte Carlo Search Trees__ (MCST) and __Upper Confidence Bound for Search Trees__ (UCT). I will not only examine the theory behind concept but also implement them in Python. In the end my final goal is not only to understand the method but also be able to use it in practice.
+
+I assume that the reader has some prior knowledge pertaining the fundamentals of reinforcement learning.
+
+## Upper Confidence Bound
+
+One of the simplest policies for making decisions based on action values estimates is greedy action selection.
+
+
+$$
+A_t = \underset{a}{\mathrm{argmax}}(Q_t(a))
+$$
+
+
+This means, that in order to choose an action $$A_t$$ we compute an estimated value of all the possible actions and pick the one which has the highest estimate. This greedy behavior completely ignores the possibilities that some actions may be inferior in the short run but ultimately superior in the longer perspective. We can fix this shortcoming by deciding that sometimes (the "sometimes" is parametrized by some probability $$\epsilon$$) we simply ignore the greedy policy and pick a random action. This is the simplest way to enforce some kind of exploration in this exploitation-oriented algorithm. Such a policy is known as epsilon-greedy.
+
+Even though epsilon-greedy policy does help us to explore the non-greedy actions, it does not model the uncertainty related to each action. It would be much more clever to make decisions by also taking into account our belief, that some action value estimates are much more reliable i.e. they are closer to some actual, unknown action value $$q_{*}(a)$$ then others. Even though we do not know $$q_{*}(a)$$ (it is actually our goal to estimate it), we can use the notion of the difference between the desired $$q_{*}(a)$$ and currently available $$Q_t(a)$$. This relationship is described by the Hoeffding's Inequality.
+
+Imagine we have $$t$$ independent, identically distributed random variables, bounded between 0 and 1. We may expect that their average is somewhat close to the expected value. The Hoeffding's inequality precisely quantifies the relationship between $$\bar{X_t}$$ and $$\mathbb{E}[X]$$.
+
+
+$$
+Pr[|\bar{X_t}-\mathbb{E}[X]|>m] \leq e^{-2tm^2}
+$$
+
+
+The equation states that the probability that the sample mean will differ from its expected value by more then some threshold $$m$$ decreases exponentially with increasing sample size $$t$$ and increasing threshold $$m$$. In other words, if we want to increase the probability that our estimate improves, we should either collect more samples or agree to tolerate higher possible deviation.
+
+In our multi-armed bandit problem we want to make sure that our estimated action value is not far from the real action value. We can express the threshold $$m$$ as a function of an action and call it $$U_t(a)$$. This value is known as an upper confidence bound. Now, we can apply the Hoeffding's inequality and state:
+
+
+$$
+Pr[|Q_t(a)-q_*(a)|> U_t(a)] \leq e^{-2tU_t(a)^2}
+$$
+
+
+ Let's denote this probability as some very small number $$l$$ and transform this expression.
+
+
+$$
+l = e^{-2N_tU_t(a)^2}
+$$
+
+
+$$
+U_t(a) = \sqrt{-\log{l}/2N_t(a)}
+$$
+
+We can make $$l$$ dependent on the number of iterations (let's say $$l = t^{-4}$$) and rewrite the equation.
+
+
+$$
+U_t(a) = \sqrt{-\log{t^{-4}}/2N_t(a)} = C\sqrt{\log{t}/{N_t(a)}}
+$$
+
+
+Finally, we can write down the UCB policy:
+
+
+$$
+UCB(a) = \underset{a}{\mathrm{argmax}}(Q_t(a) + C\sqrt{\log{t}/{N_t(a)}})
+$$
+
+
+The choice of $$l$$ is in practice reflected by the parameter $$C$$ in front of the square root. It quantifies the degree of exploration. With the large $$C$$ we obtain greater numerator value of the square root and make the uncertainty expression more significant with respect to the overall score $$UCB(a)$$. However, ultimately $$U_t(a)$$ is bound to decay, since the numerator ($$N_t(a)$$ - number of times we have chosen action $$a$$) increases with the higher rate then the numerator.
+
+We may write down a pseudo-code for a simple, multi-armed bandit algorithm (UCB1) :
+
+```
+Initialize a Bandit with:
+
+p # arm pull number
+a # possible actions a
+c # degree of exploration
+
+Q(a) = 0 # action value estimates
+N(a) = 0 # number of times the actions are selected
+t = 0
+
+for pull in range(p):
+ t = t + 1
+ # choose an action according to UCB formulation
+ A = argmax(Q(a) + c*sqrt(ln(t)/N(a)))
+
+ R = Bandit(A) # receive a reward from the environment
+ N(A) = N(A) + 1 # update the action selection count
+ Q(A) = Q(A) + (R-Q(A)/N(A) # update action value estimate
+```
+
+Finally, I have implemented UCB1 algorithm in Python: you can find the code [here](
+
+ Our SegNet: input, ground truth, prediction.
+
+### Brain of an Agent
+
+The central part of robot's cognition is the brain. This is the part responsible for the agent's decision: given the current state of the world and my policy, which action should I take? To answer this questions, we have decided to employ several approaches:
+
+__Proximal Policy Optimization__ - PPO is current state-of-the-art family of policy gradient methods for reinforcement learning developed by OpenAI. It alternates between sampling data through interaction with the environment and optimizing a “surrogate” objective function using stochastic gradient ascent.
+
+__Behavioral Cloning from Observation__ - this approach frames our problem as supervised learning task. We "play the game" for half an hour in order for agent to clone our behaviour. Given this ground truth, the agent learns the rough desired policy.
+
+Moreover, we have created our own __Heuristic Approach__, which will be explained in the next chapter.
+
+## Presentation of Solutions:
+
+### PPO
+
+
+ The learning process of the agent. We can see that after 24h hours of training G.E.A.R became excellent at it's job.
+
+Our first approach involves training an agent using PPO algorithm. Here, the semantic segmentation information does not come from an external neural network. It is being generated using a shader in Unity, which segments the objects using tags. This means that the agent quickly receives reliable, noise-free information about objects' classes during training. We additionally utilize two more modifications offered by Unity ML-Agents:
+
+- __Memory-enhanced agents using Recurrent Neural Networks__ - this allows the agent not only to act on the current RGBD input, but also "to remember" the last $$n$$ inputs and include this additional information into its reasoning while making decisions. We have observed that this has improved the ability of G.E.A.R to prioritize its actions e.g. the agent may sometimes ignore a single garbage item when it recognizes that there is an opportunity to collect two other items instead (higher reward), but eventually returns to collect the omitted garbage.
+
+- __Using curiosity__ - when we face a problem, where the extrinsic signals are very sparse, the agent does not have enough information to figure out the correct policy. We may endow the agent with a sense of curiosity, which gives the robot an internal reward every time it discovers something surprising and unconventional with regard to its current knowledge. This encourages an agent to explore the world and be more "adventurous". It is hard to say what was the influence of curiosity in our case, but we have noticed that there were several timepoints where the internal reward spiked during training and significantly improved the current policy of an agent.
+
+It took us couple of days of curriculum training to train agent using PPO. We have observed that setting the punishments initially to high, encourages the agent to simply run in circles. This can be avoided by initially allowing the agent to figure out the main goal. Once the robot understands what it is being encouraged to do, we can impose further restraints in form of harsher punishments to fine tune the behaviour of G.E.A.R.
+
+### PPO with Segmentation Network
+
+
+
+ Inference using PPO model with Segmentation Network. Not only is the algorithm much slower (we have several milliseconds delay using the best computer we good get our hands on), but the behaviour of the agent is not entirely correct (SegNet's output is not as accurate as the images produced by the custom shader in Unity).
+
+In real-life application, we could not use the custom shader in Unity 3D. That is why we should train our own model for semantic segmentation. When the model is ready, there are two possibilities to embed the SegNet into the Python API:
+- __Train the brain with SegNet in train time__ - this makes the training extremely time inefficient. Every input frame needs to be segmented by the SegNet which is too computationally expensive for our humble laptops. Additionally, the brain of the agent suffers from the SegNet's imperfect output. On the other hand, this approach makes the implementation of SegNet in Python API quite straightforward.
+- __Train the brain using custom shader and plug in the SegNet during test time__ - this is more time-efficient solution, because SegNet is being used only at inference time. It also allows to train the brain of the agent using noise-free segmented images from the custom shader. Sadly, this requires much more work with Python API, to integrate SegNet post-factum.
+
+Given our limited computational resources and desire to train the brain using perfect data, we have decided to choose the second option.
+
+### Behavioral Cloning
+
+
+
+In this approach agent learns directly from human player. This has several implications: we can train a decent agent in half an hour or so, but it will never be better then a human. This approach may suffice to create an agent which is just good and not excellent in some task (e.g video game AI, where an agent should be weak enough so we can enjoy playing a game). Obviously, G.E.A.R trained using this method is not good enough for our purpose.
+
+
+### Heuristic
+
+
+ Heuristic algorithm in action! On one hand, requires less training and is excellent at recognizing true positives. On the other hand, once a true positive is found, the agent collects it without considering that it may also unintentionally collect a non-collectible item...
+
+While planning the project, we have established that the robot's behaviour consists in essence of two task: approaching the collectible objects and deciding if the garbage should be collected or not. So far, our agent has managed to figure out both assignments on its own. But just for fun (or maybe to accelerate the training process), we can "hard-code" the second objective - deciding if the garbage should be collected or not. The decision about activating the grabbing mechanism is just an output of a simple function, which takes into consideration two factors:
+
+1. The class of the object in front of us (defined by a semantic segmentation map)
+2. The distance of the object from our robot (provided by a depth map)
+
+This function can be easily hard-coded in the following way:
+- From the current depth map, filter out only those pixels which belong to the "collectible" class (overlaying a binary mask over the depth map).
+- Check if the pixel with the highest value is greater than some set threshold.
+- If yes: the collectible object is close enough to G.E.A.R and therefore we might collect it!
+
+
+{:refdef: style="text-align: center;"}
+
+{: refdef}
+ The decision-making behind our heuristic.
+
+## Summary and Possible Improvements
+
+We have created a simulation of an autonomous robot in our custom-made environment using several different approaches.
+Still, in order to turn the prototype into an actual product, which can deliver business value, there are some improvements which should introduced:
+
+__Install the actual mechanism for garbage collection__ - as mentioned before, the mechanical design of the robot should be simulated in detail. This means installing a "shovel" which could seamlessly push the garbage into the "belly" of a robot. As a result, we should also design a clever and efficient way to dispose the set of items once the robot's container becomes full.
+
+__Deploy the algorithm on a machine which can handle real-time semantic segmentation__ - the inference time of the semantic segmentation model turned out to be too slow for real-time simulation. This comes mainly from the limited computing power of our laptops. We could easily improve it not only by using professional, industry-grade graphic cards, but possibly rewriting the code using C++ or (in more extreme cases) introducing weights quantization.
+
+__Transfer the knowledge from simulation to a real robot with RealSense camera__ - the final part of the endeavour would be deployment of the robot in the physical environment. This would mean fine-tuning algorithms by running the robot in the real world. To my best knowledge, the use of reinforcement learning in robotics is still in experimental stage. One of the recent undertakings, which translates the results of the RL robot simulation into physical agents is the [ANYmal](https://www.anybotics.com/) project. We could use similar approaches to move from Unity 3D engine to the actual world. It would be really exciting to explore how G.E.A.R would do in the complex, real-life domain!
+
+{:refdef: style="text-align: center;"}
+
+{: refdef}
+ G.E.A.R team presenting the project at the Centre for Translational Cancer Research (TUM Clinic).
+
+
+
+
+
+
+
diff --git a/_posts/2019-05-16-Alpha-Zero-1.md b/_posts/2019-05-16-Alpha-Zero-1.md
new file mode 100644
index 0000000000..41f5bf2372
--- /dev/null
+++ b/_posts/2019-05-16-Alpha-Zero-1.md
@@ -0,0 +1,178 @@
+---
+layout: post
+title: "Understanding AlphaGo Zero [1/3]:
+ Upper Confidence Bound, Monte Carlo Search Trees and Upper Confidence Bound for Search Trees"
+author: "Damian Bogunowicz"
+categories: blog
+tags: [reinforcement learning, multi-armed bandits, artificial intelligence, game theory]
+image: alpha-zero-one.jpg
+---
+
+Being interested in current trends in Reinforcement Learning I have spent my spare time getting familiar with the most important publications in this field. While doing the research I have stumbled upon the [AlphaGo Zero course](http://www.depthfirstlearning.com/2018/AlphaGoZero) by Depth First Learning group. I love how they structure their courses as self-contained lesson plans focusing on deep understanding of the theory and provide background behind every approach. So far they offer just three courses, but their quality is outstanding. It is also great that they provide related reading for further study. I have decided to follow their AlphaGo Zero course and publish my learnings in form of three blog posts. Every entry will be tightly correlated with the topics from the curriculum. Note that the articles will not follow the order suggested by the authors of the course.
+
+This first entry will discuss the concepts of __Upper Confidence Bound__ (UCB), __Monte Carlo Search Trees__ (MCST) and __Upper Confidence Bound for Search Trees__ (UCT). I will not only examine the theory behind concept but also implement them in Python. In the end my final goal is not only to understand the method but also be able to use it in practice.
+
+I assume that the reader has some prior knowledge pertaining the fundamentals of reinforcement learning.
+
+## Upper Confidence Bound
+
+One of the simplest policies for making decisions based on action values estimates is greedy action selection.
+
+
+$$
+A_t = \underset{a}{\mathrm{argmax}}(Q_t(a))
+$$
+
+
+This means, that in order to choose an action $$A_t$$ we compute an estimated value of all the possible actions and pick the one which has the highest estimate. This greedy behavior completely ignores the possibilities that some actions may be inferior in the short run but ultimately superior in the longer perspective. We can fix this shortcoming by deciding that sometimes (the "sometimes" is parametrized by some probability $$\epsilon$$) we simply ignore the greedy policy and pick a random action. This is the simplest way to enforce some kind of exploration in this exploitation-oriented algorithm. Such a policy is known as epsilon-greedy.
+
+Even though epsilon-greedy policy does help us to explore the non-greedy actions, it does not model the uncertainty related to each action. It would be much more clever to make decisions by also taking into account our belief, that some action value estimates are much more reliable i.e. they are closer to some actual, unknown action value $$q_{*}(a)$$ then others. Even though we do not know $$q_{*}(a)$$ (it is actually our goal to estimate it), we can use the notion of the difference between the desired $$q_{*}(a)$$ and currently available $$Q_t(a)$$. This relationship is described by the Hoeffding's Inequality.
+
+Imagine we have $$t$$ independent, identically distributed random variables, bounded between 0 and 1. We may expect that their average is somewhat close to the expected value. The Hoeffding's inequality precisely quantifies the relationship between $$\bar{X_t}$$ and $$\mathbb{E}[X]$$.
+
+
+$$
+Pr[|\bar{X_t}-\mathbb{E}[X]|>m] \leq e^{-2tm^2}
+$$
+
+
+The equation states that the probability that the sample mean will differ from its expected value by more then some threshold $$m$$ decreases exponentially with increasing sample size $$t$$ and increasing threshold $$m$$. In other words, if we want to increase the probability that our estimate improves, we should either collect more samples or agree to tolerate higher possible deviation.
+
+In our multi-armed bandit problem we want to make sure that our estimated action value is not far from the real action value. We can express the threshold $$m$$ as a function of an action and call it $$U_t(a)$$. This value is known as an upper confidence bound. Now, we can apply the Hoeffding's inequality and state:
+
+
+$$
+Pr[|Q_t(a)-q_*(a)|> U_t(a)] \leq e^{-2tU_t(a)^2}
+$$
+
+
+ Let's denote this probability as some very small number $$l$$ and transform this expression.
+
+
+$$
+l = e^{-2N_tU_t(a)^2}
+$$
+
+
+$$
+U_t(a) = \sqrt{-\log{l}/2N_t(a)}
+$$
+
+We can make $$l$$ dependent on the number of iterations (let's say $$l = t^{-4}$$) and rewrite the equation.
+
+
+$$
+U_t(a) = \sqrt{-\log{t^{-4}}/2N_t(a)} = C\sqrt{\log{t}/{N_t(a)}}
+$$
+
+
+Finally, we can write down the UCB policy:
+
+
+$$
+UCB(a) = \underset{a}{\mathrm{argmax}}(Q_t(a) + C\sqrt{\log{t}/{N_t(a)}})
+$$
+
+
+The choice of $$l$$ is in practice reflected by the parameter $$C$$ in front of the square root. It quantifies the degree of exploration. With the large $$C$$ we obtain greater numerator value of the square root and make the uncertainty expression more significant with respect to the overall score $$UCB(a)$$. However, ultimately $$U_t(a)$$ is bound to decay, since the numerator ($$N_t(a)$$ - number of times we have chosen action $$a$$) increases with the higher rate then the numerator.
+
+We may write down a pseudo-code for a simple, multi-armed bandit algorithm (UCB1) :
+
+```
+Initialize a Bandit with:
+
+p # arm pull number
+a # possible actions a
+c # degree of exploration
+
+Q(a) = 0 # action value estimates
+N(a) = 0 # number of times the actions are selected
+t = 0
+
+for pull in range(p):
+ t = t + 1
+ # choose an action according to UCB formulation
+ A = argmax(Q(a) + c*sqrt(ln(t)/N(a)))
+
+ R = Bandit(A) # receive a reward from the environment
+ N(A) = N(A) + 1 # update the action selection count
+ Q(A) = Q(A) + (R-Q(A)/N(A) # update action value estimate
+```
+
+Finally, I have implemented UCB1 algorithm in Python: you can find the code [here](). I have tested it for a bandit with ten arms and 100 runs. Note, that that my implementation makes algorithm do some random exploration, it is not pure vanilla UCB1.
+
+The following diagrams illustrate how the algorithm incrementally estimates the probability of receiving a reward from each of the arms for one single run.
+
+ +
+
+
+ +
+ With every iteration, the UCB1 improves the estimate of the true reward probability for each available action. The orange parts of the bar chart (uncertainity) decrease continuously over iterations, while the blue parts (value estimates) get close to the true distribution.
+
+Next experiment involves running the algorithm 100 times and computing the percentage of optimal actions taken for each iteration of UCB1.
+
+
+
+ With every iteration, the UCB1 improves the estimate of the true reward probability for each available action. The orange parts of the bar chart (uncertainity) decrease continuously over iterations, while the blue parts (value estimates) get close to the true distribution.
+
+Next experiment involves running the algorithm 100 times and computing the percentage of optimal actions taken for each iteration of UCB1.
+
+ +
+ Over time, the algorithm succesfully learns to select optimal actions.
+
+
+
+## MCST & UCT
+
+Monte Carlo Search Tree (MCST) is a heuristic search algorithm for choosing optimal choices in decision processes (this includes games). Hence, theoretically it can be applied to any domain that can be described as a (state, action) tuple.
+
+In principle, the MCST algorithm consists of four steps:
+
+1. __Selection__: the algorithm starts at the root node R (initial state of the game) and traverses the decision tree (so it revisits the previously "seen" states ) according to the current policy until it reaches a leaf node L. If node L:
+
+ a) is a terminal node (final state of the game) - jump to to step 4.
+
+ b) is not terminal, then it is bound to have some previously unexplored children - continue with step 2.
+
+2. __Expansion__: We expand one of the child nodes of L - let's call this child node C.
+
+3. __Rollout__: Starting from node C, we let the algorithm simply continue playing on it's own according to some policy (e.g random policy) until we reach a terminal node.
+
+4. __Update__: Once we reach a terminal node, the game score is returned. We propagate it (add it to the current node value) through all the nodes visited in this iteration (starting with C, through all the nodes involved in selection step, up to the root node R). We do not only update the node value, but also the number of times each of the nodes has been visited.
+
+Wait a minute... Since each node keeps the information about its value and number of times it has been visited, we may use UCB to choose the optimal action for every node. The UCT (Upper Confidence Bound for Search Trees) combines the concept of MCST and UCB. This means introducing a small change to the rudimentary tree search: in selection phase, for every parent node the algorithm evaluates its child nodes using UCB formulation:
+
+
+$$
+UCT (j) =\bar{X}_j + C\sqrt{\log(n_p)/(n_j)}
+$$
+
+Where $$\bar{X}_j$$ is an average value of the node (total score divided by the number of times the node has been visited), $$C_p$$ is some positive constant (responsible for exploration-exploitation trade-off), $$n_p$$ is the number of times the parent node has been visited and $$n_j$$ is the number of times the node $$j$$ has been visited.
+
+The algorithm has useful properties. It not only requires very little prior knowledge about the game (apart from the legal moves and game score for terminal states) but effectively focuses the search towards the most valuable branches. We may also tune it in order to find a good trade-off between the algorithm speed and number of iterations. This is quite important since MCST gets pretty slow for large combinatorial spaces.
+
+If you would like to implement UCT from the scratch I can highly recommend the code presented in MCST research hub (link below). The authors have provided code snippets in Python and Java together with a template to create your own small games that can be "cracked" using UCT.
+
+I have modified the code and created an A.I opponent for 4x4 tic tac toe. Every time the adversary is prompted to make a move, it runs 1000 UCT iterations in order to find the best action. I must admit that the opponent is quite difficult to beat. During the game play I am being successfully blocked by the A.I. UCT allows it to quickly come up with simple, effective strategies.
+
+
+
+ Over time, the algorithm succesfully learns to select optimal actions.
+
+
+
+## MCST & UCT
+
+Monte Carlo Search Tree (MCST) is a heuristic search algorithm for choosing optimal choices in decision processes (this includes games). Hence, theoretically it can be applied to any domain that can be described as a (state, action) tuple.
+
+In principle, the MCST algorithm consists of four steps:
+
+1. __Selection__: the algorithm starts at the root node R (initial state of the game) and traverses the decision tree (so it revisits the previously "seen" states ) according to the current policy until it reaches a leaf node L. If node L:
+
+ a) is a terminal node (final state of the game) - jump to to step 4.
+
+ b) is not terminal, then it is bound to have some previously unexplored children - continue with step 2.
+
+2. __Expansion__: We expand one of the child nodes of L - let's call this child node C.
+
+3. __Rollout__: Starting from node C, we let the algorithm simply continue playing on it's own according to some policy (e.g random policy) until we reach a terminal node.
+
+4. __Update__: Once we reach a terminal node, the game score is returned. We propagate it (add it to the current node value) through all the nodes visited in this iteration (starting with C, through all the nodes involved in selection step, up to the root node R). We do not only update the node value, but also the number of times each of the nodes has been visited.
+
+Wait a minute... Since each node keeps the information about its value and number of times it has been visited, we may use UCB to choose the optimal action for every node. The UCT (Upper Confidence Bound for Search Trees) combines the concept of MCST and UCB. This means introducing a small change to the rudimentary tree search: in selection phase, for every parent node the algorithm evaluates its child nodes using UCB formulation:
+
+
+$$
+UCT (j) =\bar{X}_j + C\sqrt{\log(n_p)/(n_j)}
+$$
+
+Where $$\bar{X}_j$$ is an average value of the node (total score divided by the number of times the node has been visited), $$C_p$$ is some positive constant (responsible for exploration-exploitation trade-off), $$n_p$$ is the number of times the parent node has been visited and $$n_j$$ is the number of times the node $$j$$ has been visited.
+
+The algorithm has useful properties. It not only requires very little prior knowledge about the game (apart from the legal moves and game score for terminal states) but effectively focuses the search towards the most valuable branches. We may also tune it in order to find a good trade-off between the algorithm speed and number of iterations. This is quite important since MCST gets pretty slow for large combinatorial spaces.
+
+If you would like to implement UCT from the scratch I can highly recommend the code presented in MCST research hub (link below). The authors have provided code snippets in Python and Java together with a template to create your own small games that can be "cracked" using UCT.
+
+I have modified the code and created an A.I opponent for 4x4 tic tac toe. Every time the adversary is prompted to make a move, it runs 1000 UCT iterations in order to find the best action. I must admit that the opponent is quite difficult to beat. During the game play I am being successfully blocked by the A.I. UCT allows it to quickly come up with simple, effective strategies.
+
+ +
+ My sample 4x4 tic tac toe game against the UCT-based opponent.
+
+The source code can be found in the [github repo](
+
+ My sample 4x4 tic tac toe game against the UCT-based opponent.
+
+The source code can be found in the [github repo]().
+
+## Sources:
+
+### UCB
+
+[Sutton & Barto book: Sections 2.1 - 2.7](https://web.stanford.edu/class/psych209/Readings/SuttonBartoIPRLBook2ndEd.pdf) - excellent introduction to multi-armed bandit approaches.
+
+[Blog post by Lilian Weng](https://lilianweng.github.io/lil-log/2018/01/23/the-multi-armed-bandit-problem-and-its-solutions.html#ucb1) - short and concise introduction to basic algorithms used in multi-armed bandit.
+
+[Blog post by Jeremy Kun](https://jeremykun.com/2013/10/28/optimism-in-the-face-of-uncertainty-the-ucb1-algorithm/) - a bit more detailed (but super interesting) analysis of UCB.
+
+
+
+### MCST
+
+[MCTS research hub](http://mcts.ai/about/index.html) - excellent starting point for getting familiar with the algorithm.
+
+[UCT video tutorial by John Levine](https://www.youtube.com/watch?v=UXW2yZndl7U) - short and clear explanation of MCST, together with a worked example.
+
+
+
diff --git a/_posts/2019-08-12-Action-Recognition-Attention.md b/_posts/2019-08-12-Action-Recognition-Attention.md
new file mode 100644
index 0000000000..b3b47c3208
--- /dev/null
+++ b/_posts/2019-08-12-Action-Recognition-Attention.md
@@ -0,0 +1,215 @@
+---
+layout: post
+title: "Tutorial - Visual Attention for Action Recognition"
+author: "Damian Bogunowicz"
+categories: blog
+tags: [computer vision, tutorial, neural networks, classification]
+image: attention.jpeg
+
+---
+
+Action recognition is the task of inferring various actions from video clips. This feels like a natural extension of image classification task to multiple frames. The final decision on the class membership is being made by fusing the information from all the processed frames. Reasoning about a video remains a challenging task because of high computational cost (it takes more resources to processes three-dimensional data structures than 2D tensors), difficulty of capturing spatio-temporal context across frames (especially problematic when the position of a camera changes rapidly) or the difficulty of obtaining a useful, specialized dataset (it is much easier and cheaper to collect vast amounts of independent images then image sequences).
+
+
+
+
 +
+ Attention module allows the network to explain its choice of class by pointing at important parts of the video (by generating heatmaps).
+
+Independently of the action recognition problem, the machine learning community observed a surge of scientific work which uses soft attention model - introduced initially for machine translation by Bahdanau et. al 2014[^1] . It has gotten more attention then its sibling, hard attention, because of its deterministic behavior and simplicity. The intuition behind the attention mechanism can be easily explained using human perception. Our visual processing system tends to focus selectively on parts of the receptive field while ignoring other irrelevant information. This helps us to filter out noise and effectively reason about the surrounding world. Similarly, in several problems involving language, speech or vision, some parts of the input can be more relevant compared to others. For instance, in translation and summarization tasks, only certain words in the input sequence may be relevant for predicting the next word.
+
+The purpose of this blog post is to present how the visual attention can be used for action recognition. I will give a short overview of the history, discuss the neural network architectures used in the tutorial together with the implementation details and finally present the results produced by two methods: Attention LSTM __(ALSTM)__ and Convolutional Attention LSTM __(ConvALSTM)__. The implementation described in this tutorial can be found in my [github repo](https://github.com/dtransposed/Paper-Implementation/tree/master/action_recognition_using_visual_attention).
+
+## Table of Contents
+
+* [Short Historical Background](#short-historical-background)
+* [Attention LSTM for Action Recognition](#attention-lstm-for-action-recognition)
+* [Summary of the Method](#summary-of-the-method)
+ * [Soft attention block](#soft-attention-block)
+ * [Final classification of weighted feature cube](#final-classification-of-weighted-feature-cube)
+ * [LSTM hidden state and cell state initialization](#lstm-hidden-state-and-cell-state-initialization)
+* [Making Attention LSTM Fully Convolutional](#making-attention-lstm-fully-convolutional)
+* [Implementation Details, Results and Evaluation](#implementation-details-results-and-evaluation)
+* [HMDB-51 Dataset Processing](#hmdb-51-dataset-processing)
+* [Implementation details](#implementation-details)
+* [Results](#results)
+ * [Successful predictions](#successful-predictions)
+ * [ALSTM](#alstm)
+ * [ConvALSTM](#convalstm)
+ * [Failure cases](#failure-cases)
+ * [ALSTM](#alstm-1)
+ * [ConvALSTM](#convalstm-1)
+* [References](#references)
+
+## Short Historical Background
+
+The surge of deep learning research in the domain of __action recognition__ came around year 2014. That's when the problem has been successfully tackled from two angles. Karpathy et al. 2014 [^2] used convolutional neural networks (CNNs) to extract information from consecutive video frames and then fused those representations to reason about the class of the whole sequence. Soon Simmoyan and Zisserman 2014 [^3] came up with different solution - a network which analyzes two input streams independently: one stream reasons about the spatial context (video frames) while the second uses temporal information (extracted optical flow). Finally both pieces of information are combined so the network can compute class score. Another work introduced by Du Tran et al. 2014[^4] uses 3D convolutional kernels on spatiotemporal cube. Lastly, one of the most popular approaches was proposed by Donahue et al. 2014 [^5] . Here, the encoder-decoder architecture takes each single frame of the sequence, encodes it using a CNN and feeds its representation to an Long-Short Term Memory (LSTM) block. This way we "compress" the image using feature extractor and then learn the temporal dependencies between frames using recurrent neural network.
+
+
+ Attention module allows the network to explain its choice of class by pointing at important parts of the video (by generating heatmaps).
+
+Independently of the action recognition problem, the machine learning community observed a surge of scientific work which uses soft attention model - introduced initially for machine translation by Bahdanau et. al 2014[^1] . It has gotten more attention then its sibling, hard attention, because of its deterministic behavior and simplicity. The intuition behind the attention mechanism can be easily explained using human perception. Our visual processing system tends to focus selectively on parts of the receptive field while ignoring other irrelevant information. This helps us to filter out noise and effectively reason about the surrounding world. Similarly, in several problems involving language, speech or vision, some parts of the input can be more relevant compared to others. For instance, in translation and summarization tasks, only certain words in the input sequence may be relevant for predicting the next word.
+
+The purpose of this blog post is to present how the visual attention can be used for action recognition. I will give a short overview of the history, discuss the neural network architectures used in the tutorial together with the implementation details and finally present the results produced by two methods: Attention LSTM __(ALSTM)__ and Convolutional Attention LSTM __(ConvALSTM)__. The implementation described in this tutorial can be found in my [github repo](https://github.com/dtransposed/Paper-Implementation/tree/master/action_recognition_using_visual_attention).
+
+## Table of Contents
+
+* [Short Historical Background](#short-historical-background)
+* [Attention LSTM for Action Recognition](#attention-lstm-for-action-recognition)
+* [Summary of the Method](#summary-of-the-method)
+ * [Soft attention block](#soft-attention-block)
+ * [Final classification of weighted feature cube](#final-classification-of-weighted-feature-cube)
+ * [LSTM hidden state and cell state initialization](#lstm-hidden-state-and-cell-state-initialization)
+* [Making Attention LSTM Fully Convolutional](#making-attention-lstm-fully-convolutional)
+* [Implementation Details, Results and Evaluation](#implementation-details-results-and-evaluation)
+* [HMDB-51 Dataset Processing](#hmdb-51-dataset-processing)
+* [Implementation details](#implementation-details)
+* [Results](#results)
+ * [Successful predictions](#successful-predictions)
+ * [ALSTM](#alstm)
+ * [ConvALSTM](#convalstm)
+ * [Failure cases](#failure-cases)
+ * [ALSTM](#alstm-1)
+ * [ConvALSTM](#convalstm-1)
+* [References](#references)
+
+## Short Historical Background
+
+The surge of deep learning research in the domain of __action recognition__ came around year 2014. That's when the problem has been successfully tackled from two angles. Karpathy et al. 2014 [^2] used convolutional neural networks (CNNs) to extract information from consecutive video frames and then fused those representations to reason about the class of the whole sequence. Soon Simmoyan and Zisserman 2014 [^3] came up with different solution - a network which analyzes two input streams independently: one stream reasons about the spatial context (video frames) while the second uses temporal information (extracted optical flow). Finally both pieces of information are combined so the network can compute class score. Another work introduced by Du Tran et al. 2014[^4] uses 3D convolutional kernels on spatiotemporal cube. Lastly, one of the most popular approaches was proposed by Donahue et al. 2014 [^5] . Here, the encoder-decoder architecture takes each single frame of the sequence, encodes it using a CNN and feeds its representation to an Long-Short Term Memory (LSTM) block. This way we "compress" the image using feature extractor and then learn the temporal dependencies between frames using recurrent neural network.
+
+ +
+
+
+ +
+
+
+ +
+
+ Several examples of videos from HMDB-51 dataset. Each video belongs to one of the 51 classes: "fencing" (top), "ride_bike" (middle), "walk" (down).
+
+With the increasing popularity of __attention mechanisms__ applied to the tasks such as image captioning or machine translation, incorporating visual attention in the action recognition tasks became an interesting research idea. The work by Sharma et al. 2016[^6] may serve as an example. This is the first method which will be covered in this article. This idea has been improved by Z.Li et al. 2018 [^7] where three further concepts were introduced. Firstly, the spatial layout of the input is being preserved throughout the whole network. This was not the case in the previous approach, where image was flattened at some point and treated as a vector. Secondly, the authors additionally feed optical flow information to the network. This makes the architecture more sensitive to the motion between the frames. Finally, the attention is also being used for action localization. This work will also be partially covered in this tutorial. For the sake of completeness it is important to mention that visual attention was also combined with 3D CNNs by Yao et al. 2015 [^8] . It is pretty fascinating how this concept has been successfully applied some many different domains and methods!
+
+## Attention LSTM for Action Recognition
+
+### Summary of the Method
+
+In the work by Sharma et al., the problem of video classification has been tackled in the following manner. Let's denote a video $$v$$ as a set of images, such that $$v = \{x_1, x_2, ..., x_T\}$$. Every sequence consists of $30$ frames. The appearance of individual video frame $$x_t$$ is encoded as a feature cube (a feature map tensor) $${\mathbf{X}_{t,i}} \in \mathbb{R}^{D} $$ derived from the last convolutional layer of a GoogLeNet. In our implementation we will use much simpler feature extractor - VGG network - thus the feature cubes have shape $$7\times7\times512$$. So in our particular implementation:
+
+$$t \in \{1,2,...,30\} $$
+
+$$i \in \{1,2,...,7^2\}$$
+
+$$D=512$$
+
+Then, the model combines the feature cube $${\mathbf{X}}_{t,i}$$ with the respective attention map $$c_{t}\in \mathbb{R}^{F^2}$$ (how we get those maps - I will explain soon) and propagates its vectorized form through an LSTM. The recurrent block then outputs a "context vector" $$h_t$$. This vector is being used not only to predict the action class of the current frame but is also being passed as a "history of the past frames" to generate next attention map $$c_{t+1}$$ for the frame $$x_{t+1}$$.
+
+ + The detailed presentation of the network's architecture (open in new tab to enlarge).
+
+Let's take a closer look the the network. It can be dissected into three components:
+
+#### Soft attention block
+
+This element of the network is responsible for the computation of the attention map $$c_t$$. That is done by compressing a feature cube into a vector form (averaging over the dimensions $$F,F$$ for every channel of a feature cube) and finally creating a mapping from the "context vector" $$h_{t-1}$$ and current compressed frame vector to a score vector $$s_t$$:
+
+$$
+s_t = mlp_{3}(tanh(mlp_{1}(\frac{1}{F^2}\sum_{i=1}^{F^2}{\bf{X}}_{t,i})+mlp_{2}(h_{t-1})))
+$$
+
+In order to produce the final attention map, we need to additionally apply softmax to the generated vector $$s_t$$ and reshape the representation so it matches a 2D grid. This way we obtain a $$F\times{F}$$ tensor, a probability distribution over all the feature map pixels. The higher the value of the pixel in the attention map, the more important this image patch is for the classifier's decision
+
+#### Final classification of weighted feature cube
+
+First, we multiply element-wise each feature map in $$\mathbf{X}_{t,i}$$ with the obtained attention map $$c_t$$. The resulting input has the same shape as $$\mathbf{X}_{t,i}$$. Now for every channel we sum up all the pixels of a feature map and end up with a single vector in $$ \mathbb{R}^{D}$$. In order to feed this representation to the LSTM we need to insert a time dimension. Finally the output from the LSTM, $$h_{t}$$ is being used in two ways. On one hand it is processed by fully connected layer to reason about the class of $$x_{t}$$. On the other hand it is being passed on to serve as a "context vector" for $$x_{t+1}$$.
+
+#### LSTM hidden state and cell state initialization
+
+Drawing inspiration from Xu et al. 2015 , this approach uses the compressed information about the whole video $$v$$ to initialize $$h_{0}$$ and $$c_{0}$$ for faster convergence.
+
+$$
+h_0 = mlp_h(\frac{1}{T}\sum_{t=1}^{T}(\frac{1}{F^2}\sum_{i=1}^{F^2}{\mathbf{X}_{t,i}}))
+$$
+
+$$
+c_0 = mlp_c(\frac{1}{T}\sum_{t=1}^{T}(\frac{1}{F^2}\sum_{i=1}^{F^2}{\mathbf{X}_{t,i}}))
+$$
+
+We pass all the frames in $$v$$ through an encoder network which produces $$T$$ feature cubes. In order to compress this representation we take an average first over the number of feature cubes and then over all pixel values in each feature map. Resulting vector is being finally into two multi-layered-perceptrons: $$mlp_h$$ (which produces $$h_{0}$$, the "zeroth" context vector for $$x_{1}$$) and $$mlp_c$$ (which outputs $$c_{0}$$, the initial cell state of the LSTM layer).
+
+## Making Attention LSTM Fully Convolutional
+
+As mentioned before, the work Z. Li et al. introduces three new ideas regarding visual attention in action recognition. For the purpose of this tutorial I will focus only on the first concept, which is adapting the soft-attention model in such a way, that the spatial structure is preserved over time. This means introducing several changes to the current architecture:
+
+1. __Removing the cell state and hidden state initialization block__. While the authors of ALSTM did follow the initialization strategy for faster convergence, it seems that the network does fine without this component. This means that we only need to initialize the hidden state as a tensor of zeros every time the first frame of the given video enters the pipeline.
+2. __Keeping the network (almost) entirely convolutional__. Treating images as an 2D grid rather then a vector helps to preserve a spatial correlation (in this regard the convolutions are much better then inner products), leverages local receptive field and allows weight sharing. Therefore we substitute all fully connected layers for convolutional kernels (except for the last classification layer) and use convolutional LSTM instead of the standard one. Thus the hidden state is not a vector anymore, but a 3-D tensor.
+
+
+ The detailed presentation of the network's architecture (open in new tab to enlarge).
+
+Let's take a closer look the the network. It can be dissected into three components:
+
+#### Soft attention block
+
+This element of the network is responsible for the computation of the attention map $$c_t$$. That is done by compressing a feature cube into a vector form (averaging over the dimensions $$F,F$$ for every channel of a feature cube) and finally creating a mapping from the "context vector" $$h_{t-1}$$ and current compressed frame vector to a score vector $$s_t$$:
+
+$$
+s_t = mlp_{3}(tanh(mlp_{1}(\frac{1}{F^2}\sum_{i=1}^{F^2}{\bf{X}}_{t,i})+mlp_{2}(h_{t-1})))
+$$
+
+In order to produce the final attention map, we need to additionally apply softmax to the generated vector $$s_t$$ and reshape the representation so it matches a 2D grid. This way we obtain a $$F\times{F}$$ tensor, a probability distribution over all the feature map pixels. The higher the value of the pixel in the attention map, the more important this image patch is for the classifier's decision
+
+#### Final classification of weighted feature cube
+
+First, we multiply element-wise each feature map in $$\mathbf{X}_{t,i}$$ with the obtained attention map $$c_t$$. The resulting input has the same shape as $$\mathbf{X}_{t,i}$$. Now for every channel we sum up all the pixels of a feature map and end up with a single vector in $$ \mathbb{R}^{D}$$. In order to feed this representation to the LSTM we need to insert a time dimension. Finally the output from the LSTM, $$h_{t}$$ is being used in two ways. On one hand it is processed by fully connected layer to reason about the class of $$x_{t}$$. On the other hand it is being passed on to serve as a "context vector" for $$x_{t+1}$$.
+
+#### LSTM hidden state and cell state initialization
+
+Drawing inspiration from Xu et al. 2015 , this approach uses the compressed information about the whole video $$v$$ to initialize $$h_{0}$$ and $$c_{0}$$ for faster convergence.
+
+$$
+h_0 = mlp_h(\frac{1}{T}\sum_{t=1}^{T}(\frac{1}{F^2}\sum_{i=1}^{F^2}{\mathbf{X}_{t,i}}))
+$$
+
+$$
+c_0 = mlp_c(\frac{1}{T}\sum_{t=1}^{T}(\frac{1}{F^2}\sum_{i=1}^{F^2}{\mathbf{X}_{t,i}}))
+$$
+
+We pass all the frames in $$v$$ through an encoder network which produces $$T$$ feature cubes. In order to compress this representation we take an average first over the number of feature cubes and then over all pixel values in each feature map. Resulting vector is being finally into two multi-layered-perceptrons: $$mlp_h$$ (which produces $$h_{0}$$, the "zeroth" context vector for $$x_{1}$$) and $$mlp_c$$ (which outputs $$c_{0}$$, the initial cell state of the LSTM layer).
+
+## Making Attention LSTM Fully Convolutional
+
+As mentioned before, the work Z. Li et al. introduces three new ideas regarding visual attention in action recognition. For the purpose of this tutorial I will focus only on the first concept, which is adapting the soft-attention model in such a way, that the spatial structure is preserved over time. This means introducing several changes to the current architecture:
+
+1. __Removing the cell state and hidden state initialization block__. While the authors of ALSTM did follow the initialization strategy for faster convergence, it seems that the network does fine without this component. This means that we only need to initialize the hidden state as a tensor of zeros every time the first frame of the given video enters the pipeline.
+2. __Keeping the network (almost) entirely convolutional__. Treating images as an 2D grid rather then a vector helps to preserve a spatial correlation (in this regard the convolutions are much better then inner products), leverages local receptive field and allows weight sharing. Therefore we substitute all fully connected layers for convolutional kernels (except for the last classification layer) and use convolutional LSTM instead of the standard one. Thus the hidden state is not a vector anymore, but a 3-D tensor.
+
+ + The detailed presentation of the improved network's architecture (open in new tab to enlarge).
+
+## Implementation Details, Results and Evaluation
+
+### HMDB-51 Dataset Processing
+
+This dataset is composed of 6766 videoclips from various sources and has 51 action classes.
+
+For the purpose of my implementation, for every video in the dataset I extract every second frame, thus reducing the sampling rate from the original 30fps to 15fps. Then I split each video into multiple groups of 30 frames. I follow the first train/test split proposed by the authors of the dataset, so in the end I use 3570 videos for training, 1130 for validation and 400 for testing.
+
+### Implementation details
+
+It takes just few epochs for both ALSTM and ConvALSTM to converge.
+For regularization I use dropout in all fully connected layers, early stopping and weight decay. The results are satisfying, but there are still many improvements possible e.g. performing a thorough hyper-parameter tuning (time consuming process which I have decided to skip). I think that the model would especially benefit from the optimal numbers of units in dense layers (ALSTM) or kernels in convolutional layers (ConvALSTM), as well as number of LSTM/ConvALSTM cells. Finally, the output to the ConvALSTM is a tensor of size $$F \times F \times U$$. Before it is consumed by fully connected layer it needs to be flattened. The resulting size of the vector is quite large. It would be a good idea to feed it to some convolutional layers first before using the fully connected network.
+
+The ALSTM contains an additional component in its loss, the attention regularization (Xu et al. 2015). This forces the model to look at each region of the frame at some point in time, so that:
+
+$$
+\sum_{t=1}^{T}c_{t,i}\approx 1 \space where \space c_t = \frac{e^{s_{t,i}}}{\sum_{j=1}^{K^2} e^{s_{t,j}}}
+$$
+
+The regularization $$\lambda$$ term decides whether the model explores different gaze locations or not. I have found out that $$\lambda=0.5$$ is adequate for my ALSTM.
+
+To visualize an attention map $$c_i$$, I take its representation, a $$7 \times 7 $$ matrix, and upsample to $$800 \times 800 $$ grid. I smooth it using Gaussian filter and keep only those values higher then the $$80^{th}$$ percentile of the image pixels. This removes noise from the heatmap and allows to clearly inspect which parts of the frame were important for the network.
+
+| Symbol | Description | ALSTM | ConvALSTM |
+| ----------- | ------------------------------------------------------------ | --------- | --------- |
+| B | batch size | 16 | 16 |
+| F | dimension of the feature map extracted from VGG's pool5 layer | 7 | 7 |
+| D | number of feature maps extracted from VGG's pool5 layer | 512 | 512 |
+| U | number of LSTM units (ALSTM) or number of channels in the convolutional kernel of convolutional LSTM (ConvALSTM) | 512 | 256 |
+| C | number of classes | 51 | 51 |
+| $$dt$$ | dropout value at all fully connected layers | 0.5 | 0.5 |
+| $$\lambda$$ | attention regularization term | 0.5 | $$-$$ |
+| $$\omega$$ | weight decay parameter | 0 | $$-$$ |
+| $$-$$ | accuracy of the model (test set) | $$56.0$$% | $$52.5$$% |
+
+ Description of models' parameters
+
+### Results
+It is interesting to see how well the network attends to meaningful patches of a video frame. Even though ALSTM achieves higher accuracy then ConvALSTM, the latter does much better job when it comes to attention heatmap generation.
+To obtain a prediction for an entire video clip, I compute the mode of predictions from all 30 frames in the video.
+
+#### Successful predictions
+
+##### ALSTM
+
+
+ The detailed presentation of the improved network's architecture (open in new tab to enlarge).
+
+## Implementation Details, Results and Evaluation
+
+### HMDB-51 Dataset Processing
+
+This dataset is composed of 6766 videoclips from various sources and has 51 action classes.
+
+For the purpose of my implementation, for every video in the dataset I extract every second frame, thus reducing the sampling rate from the original 30fps to 15fps. Then I split each video into multiple groups of 30 frames. I follow the first train/test split proposed by the authors of the dataset, so in the end I use 3570 videos for training, 1130 for validation and 400 for testing.
+
+### Implementation details
+
+It takes just few epochs for both ALSTM and ConvALSTM to converge.
+For regularization I use dropout in all fully connected layers, early stopping and weight decay. The results are satisfying, but there are still many improvements possible e.g. performing a thorough hyper-parameter tuning (time consuming process which I have decided to skip). I think that the model would especially benefit from the optimal numbers of units in dense layers (ALSTM) or kernels in convolutional layers (ConvALSTM), as well as number of LSTM/ConvALSTM cells. Finally, the output to the ConvALSTM is a tensor of size $$F \times F \times U$$. Before it is consumed by fully connected layer it needs to be flattened. The resulting size of the vector is quite large. It would be a good idea to feed it to some convolutional layers first before using the fully connected network.
+
+The ALSTM contains an additional component in its loss, the attention regularization (Xu et al. 2015). This forces the model to look at each region of the frame at some point in time, so that:
+
+$$
+\sum_{t=1}^{T}c_{t,i}\approx 1 \space where \space c_t = \frac{e^{s_{t,i}}}{\sum_{j=1}^{K^2} e^{s_{t,j}}}
+$$
+
+The regularization $$\lambda$$ term decides whether the model explores different gaze locations or not. I have found out that $$\lambda=0.5$$ is adequate for my ALSTM.
+
+To visualize an attention map $$c_i$$, I take its representation, a $$7 \times 7 $$ matrix, and upsample to $$800 \times 800 $$ grid. I smooth it using Gaussian filter and keep only those values higher then the $$80^{th}$$ percentile of the image pixels. This removes noise from the heatmap and allows to clearly inspect which parts of the frame were important for the network.
+
+| Symbol | Description | ALSTM | ConvALSTM |
+| ----------- | ------------------------------------------------------------ | --------- | --------- |
+| B | batch size | 16 | 16 |
+| F | dimension of the feature map extracted from VGG's pool5 layer | 7 | 7 |
+| D | number of feature maps extracted from VGG's pool5 layer | 512 | 512 |
+| U | number of LSTM units (ALSTM) or number of channels in the convolutional kernel of convolutional LSTM (ConvALSTM) | 512 | 256 |
+| C | number of classes | 51 | 51 |
+| $$dt$$ | dropout value at all fully connected layers | 0.5 | 0.5 |
+| $$\lambda$$ | attention regularization term | 0.5 | $$-$$ |
+| $$\omega$$ | weight decay parameter | 0 | $$-$$ |
+| $$-$$ | accuracy of the model (test set) | $$56.0$$% | $$52.5$$% |
+
+ Description of models' parameters
+
+### Results
+It is interesting to see how well the network attends to meaningful patches of a video frame. Even though ALSTM achieves higher accuracy then ConvALSTM, the latter does much better job when it comes to attention heatmap generation.
+To obtain a prediction for an entire video clip, I compute the mode of predictions from all 30 frames in the video.
+
+#### Successful predictions
+
+##### ALSTM
+
+
 +
+
+
+
 +
+ Several videos along with their ground truth label and the predicted label (with the confidence degree).
+1) Correct prediction of "kiss class" with network attending to faces of kissing people. 2) Correct prediction of "pushup" with network attending to the body of the athlete. 3) Correct prediction of "ride_bike" class, with network attending to the bike. Note that when the bike is not seen anymore, the network is confused. The confidence drops, it produces wrong predictions and is not sure where to "look at". 4) Correct prediction of "brush_hair" with network attending to the hand with a brush.
+
+##### ConvALSTM
+
+
+
+ Several videos along with their ground truth label and the predicted label (with the confidence degree).
+1) Correct prediction of "kiss class" with network attending to faces of kissing people. 2) Correct prediction of "pushup" with network attending to the body of the athlete. 3) Correct prediction of "ride_bike" class, with network attending to the bike. Note that when the bike is not seen anymore, the network is confused. The confidence drops, it produces wrong predictions and is not sure where to "look at". 4) Correct prediction of "brush_hair" with network attending to the hand with a brush.
+
+##### ConvALSTM
+
+
 +
+
+
+
 +
+ 1) The network accurately predicts the label "climb" and the location of the climber. 2) Even though the predicted label is not correct, the network clearly has learned the concept of a sword and can dynamically attend to the silhouette of a man. 3) Model follows the horserider with such precision, that the attention heatmaps could be used for tracking! 4) Correct classification of "smoking" class. Note that network tracks the cigarette and smoke.
+
+#### Failure cases
+
+##### ALSTM
+
+
+
+ 1) The network accurately predicts the label "climb" and the location of the climber. 2) Even though the predicted label is not correct, the network clearly has learned the concept of a sword and can dynamically attend to the silhouette of a man. 3) Model follows the horserider with such precision, that the attention heatmaps could be used for tracking! 4) Correct classification of "smoking" class. Note that network tracks the cigarette and smoke.
+
+#### Failure cases
+
+##### ALSTM
+
+
 +
+ While the girl is sitting, the network prioritizes this action over the ground truth. She also briefly puts a barett in her mouth - the network classifies those frame as "eating". The jumping goalkeeper is thought to be doing flic flac or somersault. Additionally, the network associates large, grassy field with a game of golf.
+
+##### ConvALSTM
+
+
+
+ While the girl is sitting, the network prioritizes this action over the ground truth. She also briefly puts a barett in her mouth - the network classifies those frame as "eating". The jumping goalkeeper is thought to be doing flic flac or somersault. Additionally, the network associates large, grassy field with a game of golf.
+
+##### ConvALSTM
+
+
 +
+ 1) The network decides to partially classify "situp" video as "brush_hair". This may be due to unusual camera pose. 2) The basketball hoop is misleading the classifier, it partially predicts wrong (albeit very similar to the ground truth) class. Note how the network attends to the hand visible in first several frames.
+
+
+
+## References
+
+[^1]:
+
+ 1) The network decides to partially classify "situp" video as "brush_hair". This may be due to unusual camera pose. 2) The basketball hoop is misleading the classifier, it partially predicts wrong (albeit very similar to the ground truth) class. Note how the network attends to the hand visible in first several frames.
+
+
+
+## References
+
+[^1]:
+[^2]:
+[^4]:
+[^5]:
+[^6]:
+[^8]:
+
+ In the article I have used information from [review of action recognition](http://blog.qure.ai/notes/deep-learning-for-videos-action-recognition-review)
+
+Source of the cover image: www.deccanchronicle.com
+
+
+
+
+
+
+
+
+
diff --git a/_posts/2020-01-03-Bayesian-Linear-Regression.md b/_posts/2020-01-03-Bayesian-Linear-Regression.md
new file mode 100644
index 0000000000..2947f1de19
--- /dev/null
+++ b/_posts/2020-01-03-Bayesian-Linear-Regression.md
@@ -0,0 +1,411 @@
+---
+layout: post
+crosspost_to_medium: true
+title: "Tutorial - Sequential Bayesian Learning - Linear Regression"
+author: "Damian Bogunowicz"
+categories: blog
+tags: [machine learning, tutorial, regression, Bayesian]
+image: sequential_bayes.jpg
+
+---
+
+While I was tutoring some of my friends on the fundamentals of machine learning, I came across a particular topic in [Christopher M. Bishop's "Pattern Recognition and Machine Learning"](https://www.amazon.com/Pattern-Recognition-Learning-Information-Statistics/dp/0387310738). In Chapter 3, the author gives a great, hands-on example of Bayesian Linear Regression. I have noticed that many students (including yours truly back in the days) struggle with in-depth understanding of this particular example of sequential Bayesian learning. I think it is one of the most eye-opening moments in the ML course to fully grasp what happens in that framework. I have learned that coding this particular example really helps with understanding the concept. This is why I have decided to present my approach on that particular challenge.
+
+This example requires from the reader some basic machine learning knowledge, such as understanding of Bayes' theorem (here I can recommend a [very recent, excellent video by 3brown1blue](https://www.youtube.com/watch?v=HZGCoVF3YvM)), fundamentals of probability distribution or linear models. Once I have finished this blog post I have consulted my solution with a [similar notebook](https://github.com/zjost/bayesian-linear-regression/blob/master/src/bayes-regression.ipynb). While I personally think that my code is more elegant, one can refer to this work for more detailed theory.
+
+# Sequential Bayesian Linear Regression Tutorial
+
+## The Goal of the Tutorial
+
+In our task, there is some function. We know, that this function is linear. Additionally, the function is also noisy. We may assume additive, Gaussian noise. Our goal is create a parametrized model
+
+$$
+t = y(\mathbf{x}, \mathbf{w}) + \epsilon
+$$
+
+$$
+y(\mathbf{x}, \mathbf{w}) = w_0 + w_1x
+$$
+
+and find its parameter distribution $$\mathbf{w}$$. This can be done by sequentially collecting samples $$\mathcal{D}$$ from the target function and using this data in the Bayesian framework to approach the true value of parameters.
+
+However, finding the parameter distribution is merely an intermediate goal. Once we have established the distribution of coefficients through Bayesian treatment, we are able to predict $$t$$ for every new input $$\mathbf{x}$$
+
+$$
+p(t|\mathbf{x}, \mathcal{D}) = \int p(t|\mathbf{x},\mathbf{w})p(\mathbf{w}|\mathcal{D})d\mathbf{w}
+$$
+
+where $$\mathcal{D}$$ denotes the data observed by the algorithm.
+
+The key of Bayesian treatment is the ability to assign this probability to each value of $$t$$ for a given $$\mathbf{x}$$. Obviously, this is much more powerful than the solution based on maximizing the likelihood function. This is due to the fact that we obtain that precious probability distribution over parameters and not only point estimates. Additionally, the Bayesian approach does not suffer from over-fitting problem, nor it requires model complexity tuning (common problems with point estimates).
+
+Coming back to the model. We can write it down as a Gaussian distribution, with the mean $$y(\mathbf{x}, \mathbf{w})$$ and variance governed by a precision parameter $$\beta$$. This last parameter quantifies the noise of the model.
+
+$$
+p(t|\mathbf{x}, \mathbf{w}) = \mathcal{N}(t| y(\mathbf{x}, \mathbf{w}), \beta^{-1})
+$$
+
+
+## Prior, Likelihood and Posterior
+
+To treat linear regression in a Bayesian framework, we need to define three key elements of the Bayes' theorem: prior, likelihood and the posterior.
+
+### Likelihood
+
+Consider a data set of inputs $$\mathbf{X} = \{\mathbf{x}_1,\mathbf{x}_2,...,\mathbf{x}_N\}$$, with corresponding target values $$\mathbf{T} = \{t_1,t_2,...,t_N\}$$. Making the assumption that these data points are i.i.d (independent, identically distributed), we obtain the following expression for the likelihood function (which answers the question: how well function of parameters $$\mathbf{w}$$ explain data $$\mathcal{D} = (\mathbf{X}, \mathbf{T})$$):
+
+$$
+p(\mathcal{D}|\mathbf{w})=\prod^{N}_{n=1}\mathcal{N}(t_n|\mathbf{w}^T\phi(\mathbf{x}_n), \beta^{-1})
+$$
+
+
+### Prior
+
+Our intermediate goal is to find parameter distribution $$\mathbf{w}$$, which is going to be as close as possible to the target coefficients $$a_0$$ and $$a_1$$. Initially, we know very little about the distribution. However, we may assume a conjugate prior to the likelihood function. Thus, in general the prior, will be also a Gaussian distribution.
+
+$$
+p(\mathbf{w})=\mathcal{N}(\mathbf{w}|\mathbf{m}_{0},\mathbf{S}_0)
+$$
+
+Initially, we pick zero-mean isotropic Gaussian governed by a precision parameter $$\alpha$$:
+
+$$
+p(\mathbf{w})=\mathcal{N}(\mathbf{w}|\mathbf{0}, \alpha^{-1}\mathbf{I})
+$$
+
+### Posterior
+
+Finally we may compute the posterior, which is proportional to the product of the likelihood function and the prior.
+
+$$
+p(\mathbf{w}|\mathcal{D})=\mathcal{N}(\mathbf{w}| \mathbf{m}_{N},\mathbf{S}_N) \propto p(\mathbf{T}|\mathbf{w}) p(\mathbf{w})
+$$
+
+It [may be shown](https://www.youtube.com/watch?v=nrd4AnDLR3U&list=PLD0F06AA0D2E8FFBA&index=61) , that the mean and precision for the prior are
+
+$$
+\mathbf{m}_N = \mathbf{S}_N(\mathbf{S}_0^{-1}\mathbf{m}_0 + \beta\mathbf{\Phi}^T\mathbf{T})
+$$
+
+$$
+\mathbf{S}^{-1}_N = \mathbf{S}_{0}^{-1} + \beta\mathbf{\Phi}^T\mathbf{\Phi}
+$$
+
+where $$\mathbf{\Phi}$$ is a design matrix computed from the input data $$\mathbf{X}$$.
+
+## Worked example
+
+### Experimental Setup
+
+The constructor shows the experimental setup. We define precision parameters $$\alpha=2$$ and $$\beta=25$$, as well as the coefficients of the "unknown", target, linear function:
+
+$$
+y(\mathbf{x}) = a_0+a_1x = -0.3 + 0.5x
+$$
+
+
+Finally, the prior distribution is being computed. For all the probability-related things I recommend tensorflow probability library.
+
+```python
+ def __init__(self):
+ """
+ In the constructor we define our prior - zero-mean isotropic Gaussian governed by single
+ precision parameter alpha = 2; N(w|0, alpha**(-1)*I)
+ """
+ self.a_0 = -0.3 # First parameter of the linear function.
+ self.a_1 = 0.5 # Second parameter of the linear function.
+ self.alpha = 2 # Precision of the prior.
+ self.beta = 25 # Precision of the noise.
+ self.iteration = 0 # Hold information about the current iteration.
+
+ self.prior_mean = [0, 0]
+ self.prior_cov = 1/self.alpha * np.eye(2)
+ self.prior_distribution = tfd.MultivariateNormalFullCovariance(loc=self.prior_mean, covariance_matrix=self.prior_cov)
+```
+
+### Linear Function
+
+Linear function method is used to generate synthetic data from the "unknown", target function.
+
+```python
+ def linear_function(self, X, noisy=True):
+ """
+ Target, linear function y(x,a_0,a_1) = a_0 + a_1 * x.
+ By default, generated samples are also affected by Gaussian noise modeled by parameter beta.
+
+ :param X: tf.Tensor of shape (N,), dtype=float32. Those are inputs to the linear function.
+ :param noisy: boolean. Decides whether we should compute noisy or noise-free output.
+ :return: tf.Tensor of shape=(N,), dtype=float32. Those are outputs from the linear function.
+ """
+ if noisy:
+ noise_distribution = tfd.Normal(loc=0, scale=1 / np.sqrt(self.beta))
+ return self.a_0 + self.a_1 * X + tf.cast(noise_distribution.sample(len(X)), tf.float32)
+ else:
+ return self.a_0 + self.a_1 * X
+```
+
+### Calculating a Design Matrix
+
+A design matrix is a matrix containing data about multiple characteristics of several individuals or objects. It is $$N\times M$$ matrix, where rows are equal to the number of samples and columns to the number of features. In our particular example, the design matrix will have two columns and a variable number of rows. The first column corresponds to the $$w_0$$ parameters and is a vector of ones. The second column corresponds to the $$w_1$$ and contains vector $$[\phi_1(\mathbf{x}_1), \phi_1(\mathbf{x}_2), ..., \phi_1(\mathbf{x}_N)]^T$$. Since we do not use any basis function, this simply boils down to $$[\mathbf{x}_1, \mathbf{x}_2, ..., \mathbf{x}_N]^T$$.
+
+```python
+ def get_design_matrix(self, X):
+ """
+ Computes the design matrix of size (NxM) for feature vector X.
+ Here particularly, the function simply adds the phi_0 dummy basis (equal to 1 for all elements).
+ :param X: tf.Tensor of shape (N,), dtype=float32. Those are inputs to the linear function.
+ :return: NxM design matrix.
+ """
+ N = len(X)
+ M = len(self.prior_mean)
+ design_mtx = np.ones((N, M))
+ design_mtx[:, 1] = X
+ return design_mtx
+```
+
+### Learning Step
+
+This method performs the update step for the sequential learning. Once the posterior is computed, it becomes the prior for the next iteration (hence, **sequential** Bayesian learning!)
+
+```python
+ def update_prior(self, X, T):
+ """
+ Single learning iteration, where we use Bayes' Theorem to calculate the new posterior over model's parameters.
+ Finally, the computed posterior becomes the new prior.
+ :param X: tf.Tensor of shape (N,), dtype=float32. Feature vector.
+ :param T: tf.Tensor of shape=(N,), dtype=float32. Regression target.
+ """
+ design_mtx = self.get_design_matrix(X)
+
+ self.posterior_cov = np.linalg.inv(np.linalg.inv(self.prior_cov) + self.beta * design_mtx.T.dot(design_mtx))
+ self.posterior_mean = self.posterior_cov.dot(np.linalg.inv(self.prior_cov).dot(self.prior_mean)+ self.beta *design_mtx.T.dot(T))
+ self.posterior_distribution = tfd.MultivariateNormalFullCovariance(loc=self.posterior_mean, covariance_matrix=self.prior_cov)
+ self.prior_mean = self.posterior_mean
+ self.prior_cov = self.posterior_cov
+ self.prior_distribution = self.posterior_distribution
+
+ self.iteration += 1
+```
+
+### Plotting the Prior/Posterior
+
+This method plots a prior/posterior distribution in every iteration. Additionally, we mark the point $$(a_0, a_1)$$ to see how quickly the posterior converges to our solution.
+
+```python
+ def plot_prior(self):
+ """
+ Plot prior (posterior) distribution in parameter space. Also include the point, which indicates target parameters.
+ """
+ x = np.linspace(-1, 1, 100)
+ y = np.linspace(-1, 1, 100)
+ w_0, w_1 = np.meshgrid(x, y)
+
+ z = self.prior_distribution.prob(np.dstack((w_0, w_1)))
+
+ plt.contourf(x, y, z, cmap='plasma')
+ plt.plot(self.a_0, self.a_1, marker = 'x', c = 'orange')
+ plt.title("Prior/Posterior Plot (iteration {})".format(self.iteration))
+ plt.xlabel("$w_0$")
+ plt.ylabel("$w_1$")
+ ax = plt.axes()
+ ax.set_xlim(-1, 1)
+ ax.set_ylim(-1, 1)
+ plt.savefig('Prior_Posterior-{}.png'.format(self.iteration))
+ plt.clf()
+```
+
+### Plotting the Likelihood
+
+By analogy, we can also visualize the likelihood distribution. This answers the question: for the given batch of data, which parameters would best explain this data? I have already presented the likelihood equation. We can use it to compute log likelihood:
+
+$$
+\ln p(\mathcal{D}|\mathbf{w})= \frac{N}{2}\ln\beta - \frac{N}{2}\ln(2\pi) - \frac{\beta}{2}\sum^N_{n=1}\{t_n-\mathbf{w}^T\phi(\mathbf{x}_n)\}^2
+$$
+
+
+Since only the last term depends on the parameters $$\mathbf{w}$$, we might write:
+
+$$
+p(\mathcal{D}|\mathbf{w})\propto \exp(-\sum^N_{n=1}\{t_n-\mathbf{w}^T\phi(\mathbf{x}_n)\}^2)
+$$
+
+And use this equation to finally compute the likelihood distribution.
+
+```python
+ def plot_likelihood(self, X, T):
+ """
+ Plot likelihood distribution in parameter space. Also include the point, which indicates target parameters.
+ :param X: tf.Tensor of shape (N,), dtype=float32. Feature vector.
+ :param T: tf.Tensor of shape=(N,), dtype=float32. Regression target.
+ """
+
+ x = np.linspace(-1, 1, 100)
+ y = np.linspace(-1, 1, 100)
+ w_0, w_1 = np.meshgrid(x, y)
+
+ least_squares_sum = 0
+ for point, target in zip(X, T):
+ least_squares_sum += (target - (w_0 + w_1 * point))**2
+ z = np.exp(-self.beta*least_squares_sum)
+
+ plt.contourf(x, y, z, cmap='plasma')
+ plt.plot(self.a_0, self.a_1, marker='x', c='orange')
+ plt.title("Likelihood Plot (iteration {})".format(self.iteration))
+ plt.xlabel("$w_0$")
+ plt.ylabel("$w_1$")
+ ax = plt.axes()
+ ax.set_xlim(-1, 1)
+ ax.set_ylim(-1, 1)
+ plt.savefig('Likelihood-{}.png'.format(self.iteration))
+ plt.clf()
+```
+
+### Predictive Distribution
+
+Finally, the goal of the Bayesian framework, estimating the uncertainty of the prediction! Recall the formula for predictive distribution:
+
+$$
+p(t|\mathbf{x}, \mathcal{D}) = \int p(t|\mathbf{x},\mathbf{w})p(\mathbf{w}|\mathcal{D})d\mathbf{w}
+$$
+
+
+This result is an integral of two terms: the model
+
+$$
+p(t|\mathbf{x},\mathbf{w})
+$$
+
+which uses a particular set of parameter values, and a posterior, the probability for these parameter values
+
+$$p
+(\mathbf{w}|\mathcal{D})
+$$
+
+This means, that the predictive distribution considers every possible parameter value. It evaluates the model that has those parameter values and then weights that result by the probability of having those parameter values in the first place.
+
+Both model and the posterior are Gaussians. We can easily obtain the predictive distribution by, once again, convoluting two Gaussians:
+
+$$
+p(t|\mathbf{x}, \mathcal{D})=\mathcal{N}(t|\mu, \sigma^2))
+$$
+
+$$
+\mu = \mathbf{m}_N^T\phi(\mathbf{x})
+$$
+
+$$
+ \sigma^2 = \beta^{-1} + \phi(\mathbf{x})^T\mathbf{S}_N\phi(\mathbf{x})
+$$
+
+We can use this information to compute mean of the corresponding Gaussian predictive distribution, as well as the standard deviation.
+
+```python
+ def prediction_mean_std(self, X):
+ """
+ For every sample compute mean of the corresponding Gaussian predictive distribution,
+ as well as the standard deviation.
+ :param X: tf.Tensor of shape (N,), dtype=float32. Feature vector.
+ :return: list of tuples, where every tuple contains floats (mean, std)
+ """
+ no_samples = len(X)
+ design_mtx = self.get_design_matrix(X)
+ prediction = []
+ for index in range(no_samples):
+ x = design_mtx[index, :]
+ predictive_std = np.sqrt(1/self.beta + x.T.dot(self.prior_cov.dot(x)))
+ predictive_mean = np.array(self.prior_mean).dot(x)
+ prediction.append((predictive_mean, predictive_std))
+ return prediction
+```
+### Data Space Plotting Method
+
+Finally, we construct a method which plots the batch of upcoming data (blue points), confidence region of predictive distribution spanning one standard deviation either side of the mean (shaded, orange area), prediction mean (orange line) and target function (red line).
+
+```python
+ def plot_data_space(self, X, T, stdevs = 1):
+ """
+ Plot sampled datapoints, confidence bounds, mean prediction and target function on one graph.
+ :param X: tf.Tensor of shape (N,), dtype=float32. Feature vector.
+ :param T: tf.Tensor of shape=(N,), dtype=float32. Regression target.
+ :param stdevs: int, how large should our confidence bound be in terms of standard deviation
+ """
+
+ x = np.linspace(-1, 1, 100)
+ predictions = self.prediction_mean_std(x)
+ prediction_means = [x[0] for x in predictions]
+ y_upper = [x[0] + stdevs * x[1] for x in predictions]
+ y_lower = [x[0] - stdevs * x[1] for x in predictions]
+
+ plt.title('Data Space (iteration {})'.format(self.iteration))
+ plt.xlabel('$x$')
+ plt.ylabel('$y$')
+ ax = plt.axes()
+ ax.set_xlim(-1, 1)
+ ax.set_ylim(-1, 1)
+ # plot generated data points
+ for point, target in zip(X, T):
+ plt.scatter(x=point.numpy(), y=target.numpy(), marker ='o', c='blue', alpha=0.7)
+ # plot confidence bounds
+ plt.fill_between(x, y_upper, y_lower, where=y_upper >= y_lower, facecolor='orange', alpha=0.3)
+ # plot prediction mean
+ plt.plot(x, prediction_means, '-r', label='Prediction mean', c='orange', linewidth=2.0, alpha=0.8)
+ # plot real function
+ plt.plot(x, self.linear_function(x, noisy = False), '-r', label='Target function', c='red', linewidth=2.0, alpha=0.8)
+ plt.legend(loc='upper left')
+ plt.savefig('Data_Space-{}.png'.format(self.iteration))
+ plt.clf()
+```
+### Main Code
+
+Now, the procedure is straightforward. We start knowing nothing - the initial prior. We sample fixed number of samples $$X$$ from uniform distribution, use those samples to obtain $$T$$. Next, we use $$(X,T)$$ to visualize likelihood function and the current quality of the model in the data space. Additionally we plot the prior distribution in parameter space. Finally, we use the batch of data $$(\mathbf{X}, \mathbf{Y})$$ to perform the sequential Bayesian update.
+
+```python
+def run_sequential_bayes():
+ samples_in_batch = 1 # batch size
+ no_iterations = 20 # no of learning sequences
+ samples_precision = 1000 # decimal precision of a sample
+
+ sequential_bayes = SequentialBayes()
+ samples_generator = tfd.Uniform(low=-samples_precision, high=samples_precision)
+
+ for i in range(no_iterations):
+ X = samples_generator.sample(samples_in_batch) / samples_precision
+ T = sequential_bayes.linear_function(X)
+
+ sequential_bayes.plot_likelihood(X, T)
+ sequential_bayes.plot_prior()
+ sequential_bayes.plot_data_space(X, T)
+ sequential_bayes.update_prior(X, T)
+```
+
+
+
+## Experiments
+
+I perform two experiments. Firstly, in every iteration I supply only one pair of input and target (samples_in_batch = 1). We can see that the posterior starts converging close to the goal coefficients around iteration 12. This is also reflected in the data space. That is when the predictive distribution mean is almost equal to the target function. Note, how confidence bounds tighten as we observe more samples. Interestingly, the likelihood function always resembles a "ray". Why is that so? Since we compute it only for one single sample $$(x_0, t_0)$$, any pair $$w_0$$, $$w_1$$, which satisfies the equation $$t_0 = w_0 + w_1x_0$$ is a good fit. This means, that the line, which describes those good fits can be rewritten as:
+
+$$
+w_0 = t_0 - w_1x_0
+$$
+
+And this is straight-line equation, responsible for the "ray" shape.
+
+ +
+ +
+ +
+Now, let's use larger batches of 50 input-target pairs (samples_in_batch = 50). The posterior converges to a good approximation much faster and the satisfying solution in data space emerges after 4 iterations. Note, that the likelihood is not "ray-shaped" anymore. This time the likelihood needs to take into the account not one but fifty points It is not surprise that the distribution of "good fit" parameters is much more narrow.
+
+
+
+Now, let's use larger batches of 50 input-target pairs (samples_in_batch = 50). The posterior converges to a good approximation much faster and the satisfying solution in data space emerges after 4 iterations. Note, that the likelihood is not "ray-shaped" anymore. This time the likelihood needs to take into the account not one but fifty points It is not surprise that the distribution of "good fit" parameters is much more narrow.
+
+ +
+ +
+ +
+
+## Full Code
+
+The full code can be found [here](https://github.com/dtransposed/dtransposed-blog-codes/blob/master/Sequential%20bayesian%20linear%20regression.py).
+
+
+
+
+
diff --git a/_posts/2020-04-13-Option-Pricing.md b/_posts/2020-04-13-Option-Pricing.md
new file mode 100644
index 0000000000..8526b570c5
--- /dev/null
+++ b/_posts/2020-04-13-Option-Pricing.md
@@ -0,0 +1,151 @@
+---
+layout: post
+crosspost_to_medium: true
+title: "Option Pricing - Introduction, Example and Implementation"
+author: "Damian Bogunowicz"
+categories: blog
+tags: [finance, options, algotrading]
+image: options.jpeg
+
+---
+
+## Option Pricing: Introduction, History and Implementation
+
+This blog post is more focused on the financial, rather than software, engineering. It touches upon one of the most common financial derivatives - options. In the write-up I will briefly introduce two basic options (calls and puts), show one of their fundamental applications in financial engineering, and finally discuss my implementation of two option pricing models - Black-Scholes formula and Binomial Option Pricing Model. For the analysis, I use two assets, Tesla and Coca-Cola stocks.
+
+## Introduction
+
+So you are a stock trader, who believes that the price of some stock, let's say Tesla, will rise over next four weeks. Why would you suppose that? Maybe you are expecting that due to the new, impressive OS update, their vehicles may become far superior to competition's product. This should bump the number of Teslas sold and drive TSLA's stock price up, ultimately making you pocket a handsome profit.
+
+But you are a smart investor, aware of the possible trouble ahead. You know that Tesla is in the volatile automotive business. On one hand you are interested in the company. On the other hand, you are aware of the industry risk, since it may be directly influence the performance of your stock.
+
+Options can be used as as an "insurance" to your position. This strategy is also known as hedging. Hedging is employed to minimise any losses resulting from an investment position. One of the simplest hedging methods is to use a put option. A put option is a contract that allows you to sell a stock at a pre-determined price (a.k.a a strike price), on or before a given date. By employing "protective put" (or "married put"), an investor can basically defend himself against theoretical stock plunge. There is no free lunch though, "buying" the insurance means, that we sacrificing some of the possible excess gains.
+
+
+## Practical Example
+
+As of today, one share of TSLA is $545. At the same time, you purchase a put to insure the purchased stock. The strike price of the option should be at least greater than the amount you paid for the actual stock. For example, you buy put with a strike price of $550, with additional premium of $60 per share, which expires in four weeks.
+
+We can plot the risk characteristics of such a strategy.
+
+
+
+## Full Code
+
+The full code can be found [here](https://github.com/dtransposed/dtransposed-blog-codes/blob/master/Sequential%20bayesian%20linear%20regression.py).
+
+
+
+
+
diff --git a/_posts/2020-04-13-Option-Pricing.md b/_posts/2020-04-13-Option-Pricing.md
new file mode 100644
index 0000000000..8526b570c5
--- /dev/null
+++ b/_posts/2020-04-13-Option-Pricing.md
@@ -0,0 +1,151 @@
+---
+layout: post
+crosspost_to_medium: true
+title: "Option Pricing - Introduction, Example and Implementation"
+author: "Damian Bogunowicz"
+categories: blog
+tags: [finance, options, algotrading]
+image: options.jpeg
+
+---
+
+## Option Pricing: Introduction, History and Implementation
+
+This blog post is more focused on the financial, rather than software, engineering. It touches upon one of the most common financial derivatives - options. In the write-up I will briefly introduce two basic options (calls and puts), show one of their fundamental applications in financial engineering, and finally discuss my implementation of two option pricing models - Black-Scholes formula and Binomial Option Pricing Model. For the analysis, I use two assets, Tesla and Coca-Cola stocks.
+
+## Introduction
+
+So you are a stock trader, who believes that the price of some stock, let's say Tesla, will rise over next four weeks. Why would you suppose that? Maybe you are expecting that due to the new, impressive OS update, their vehicles may become far superior to competition's product. This should bump the number of Teslas sold and drive TSLA's stock price up, ultimately making you pocket a handsome profit.
+
+But you are a smart investor, aware of the possible trouble ahead. You know that Tesla is in the volatile automotive business. On one hand you are interested in the company. On the other hand, you are aware of the industry risk, since it may be directly influence the performance of your stock.
+
+Options can be used as as an "insurance" to your position. This strategy is also known as hedging. Hedging is employed to minimise any losses resulting from an investment position. One of the simplest hedging methods is to use a put option. A put option is a contract that allows you to sell a stock at a pre-determined price (a.k.a a strike price), on or before a given date. By employing "protective put" (or "married put"), an investor can basically defend himself against theoretical stock plunge. There is no free lunch though, "buying" the insurance means, that we sacrificing some of the possible excess gains.
+
+
+## Practical Example
+
+As of today, one share of TSLA is $545. At the same time, you purchase a put to insure the purchased stock. The strike price of the option should be at least greater than the amount you paid for the actual stock. For example, you buy put with a strike price of $550, with additional premium of $60 per share, which expires in four weeks.
+
+We can plot the risk characteristics of such a strategy.
+ +
+We can see that for a stock, the theoretical profit (and loss) are not bounded. Worst case scenario, you can simply loose all your money. Best case scenario, you may enjoy unlimited wealth increase. For a put, its is agreed upon that once the stock price falls below the strike price, you enjoy a linear profit (i.e you bet on stock price plummeting). If the stock price rises above the strike price, you may choose not to excercise the option and loose nothing. Of course, this kind of free, wonderful insurance is too good to be true in reality. That is why investors pay substantial premiums for the insurance - in this particular case, the premium amounts to mind-boggling 11%. As a result, the curve is shifted downwards by the premium price.
+
+Now, by combining long position and put, we simply add two curves and observe the effect of the marriage between the long position and the put:
+
+- If the stock price is higher then the initial stock price (when you bought the equity) + premium, you start enjoying linear profit from your investment, congratulations!
+- If the stock price is lower then the initial stock price + premium, you will experience losses proportional to the fall in stock price.
+- However, the moment the stock price falls below the strike price, the lower bound on our losses kicks in. From this moment on, you will not loose any more money. This is the put protecting you from any possible troubles.
+
+Note, that married put has similar effect as the call option. It basically hedges your long position. In fact, an investor can mix long positions, short positions and various options to create different strategies to hedge against different risks. The ingenuity of financial engineers gave rise to constructs with such names as butterfly spread, iron condor or straddle, but those are advanced products not covered in this write-up.
+
+## The (un)Solved Mystery of Option Pricing
+
+Option pricing turns out to be much more interesting then figuring out the value of bonds or stocks. Calculating the current value of the option, has baffled the financial world for a long time. The history of solving the problem stretches throughout the whole twentieth century and, quite frankly, could make a great Netflix series plot.
+
+It starts with a doctoral thesis by a French PhD student, Louis Bachelier. The pioneer of mathematical finance was writing his dissertation on options on Paris stock exchange. One of his biggest achievements is the development of the random walk hypothesis - financial theory stating that the stock market prices evolve according to a random process modeled by the Brownian motion. His discoveries had very interesting ramifications.
+
+First of all, it was a rare example of the situation, where an economist comes up with an idea, which only later is adopted by a physicist. And not just any physicist, but Albert Einstein himself. His work, which also used the concept of Brownian motion, has been awarded with the Nobel Prize.
+
+There was another beautiful coupling between physics and economy hidden in Bachelier's work. The student has shown that the same family of PDEs which dictate how the heat distribution evolves over time in a solid medium, can tell us how the value of an option changes with respect to the value of the underlying asset and time. It is stunning that a purely physical theory developed by Fourier, does describe the financial markets so accurately!
+
+Just to demonstrate - the heat equation for the 1D body (e.g. metal rod):
+
+$$
+\frac{\partial u}{\partial t}
+ = \alpha \left( \frac{\partial^2 u}{\partial x^2}\right)
+$$
+
+...versus the final Black-Scholes equation:
+
+$$
+\frac{\partial V}{\partial t}= -\frac{1}{2}\sigma^2 S^2 (\frac{\partial^2 V}{\partial S^2}) - rS\frac{\partial V}{\partial S} + rV
+$$
+
+Finally, it took almost 100 years for the brightest minds (among them PhDs from Yale and MIT) of the mathematics to actually solve the option pricing model. The duo Black and Scholes, but also an economist Robert Merton, came up independently with the solution, for which they have been awarded by a joint Noble prize. While the gentlemen received accolades for their research endeavours, Edward Thorp has managed to use Bachelier's framework several decades earlier. He has done it while managing an extremely successful hedge fund at Princeton Newport Partners. Finally, not only Thorp, but probably many financial engineers has benefited from arbitrage opportunities unlocked by the option pricing formula.
+
+## My Implementation of Option Pricing Mechanisms
+
+### Black-Scholes Formula
+
+It is a truly fascinating process to go through the derivation of the Black-Scholes formula. Starting from the definition of the Brownian motion, one uses Taylor's expansion to acquire the Black-Scholes differential equation and finally, by employing fundamentals of PDEs (including initial and boundary condiitons, particular structure of equation), one shall reach the final result:
+
+$$
+V(S, t)= N( d_1) S - N(d_2)K e^{-rt}
+$$
+
+where:
+
+$$
+d_1= \frac{1}{\sigma \sqrt{ t}} \left[\ln{\left(\frac{S}{K}\right)} + t\left(r + \frac{\sigma^2}{2} \right) \right]
+$$
+
+$$
+d_2= \frac{1}{\sigma \sqrt{ t}} \left[\ln{\left(\frac{S}{K}\right)} + t\left(r - \frac{\sigma^2}{2} \right) \right]
+$$
+
+From the model we are able to calculate the price of an option based on a number of different factors. To use Black-Scholes formula, we need first to figure out the value of the parameters of the equation:
+
+- $$K$$, the strike price. If we decide to buy an option, this what we obviously should now. This is our bet on the future price of the asset.
+- $$T$$, time to maturity is also known. This is when the option expires.
+- $$\sigma$$, the volatility. There are two ways to compute this value. We may retrieve the **implied volatility** from the current available options on the market for the same asset. Alternatively, and this is the approach in my implementation, we may use **historical volatility**- the standard deviation of log returns (difference of closing prices of the stock over consecutive days) over past data. The volatility is annualized to be consistent with the rest of the data.
+- $$r$$, annualized risk-free rate. In my implementation, this is the mean of the current interest rates on US treasury bill rates for different times of maturity.
+
+Finally, $$N(.)$$ is cumulative distribution function.
+
+
+
+We can see that for a stock, the theoretical profit (and loss) are not bounded. Worst case scenario, you can simply loose all your money. Best case scenario, you may enjoy unlimited wealth increase. For a put, its is agreed upon that once the stock price falls below the strike price, you enjoy a linear profit (i.e you bet on stock price plummeting). If the stock price rises above the strike price, you may choose not to excercise the option and loose nothing. Of course, this kind of free, wonderful insurance is too good to be true in reality. That is why investors pay substantial premiums for the insurance - in this particular case, the premium amounts to mind-boggling 11%. As a result, the curve is shifted downwards by the premium price.
+
+Now, by combining long position and put, we simply add two curves and observe the effect of the marriage between the long position and the put:
+
+- If the stock price is higher then the initial stock price (when you bought the equity) + premium, you start enjoying linear profit from your investment, congratulations!
+- If the stock price is lower then the initial stock price + premium, you will experience losses proportional to the fall in stock price.
+- However, the moment the stock price falls below the strike price, the lower bound on our losses kicks in. From this moment on, you will not loose any more money. This is the put protecting you from any possible troubles.
+
+Note, that married put has similar effect as the call option. It basically hedges your long position. In fact, an investor can mix long positions, short positions and various options to create different strategies to hedge against different risks. The ingenuity of financial engineers gave rise to constructs with such names as butterfly spread, iron condor or straddle, but those are advanced products not covered in this write-up.
+
+## The (un)Solved Mystery of Option Pricing
+
+Option pricing turns out to be much more interesting then figuring out the value of bonds or stocks. Calculating the current value of the option, has baffled the financial world for a long time. The history of solving the problem stretches throughout the whole twentieth century and, quite frankly, could make a great Netflix series plot.
+
+It starts with a doctoral thesis by a French PhD student, Louis Bachelier. The pioneer of mathematical finance was writing his dissertation on options on Paris stock exchange. One of his biggest achievements is the development of the random walk hypothesis - financial theory stating that the stock market prices evolve according to a random process modeled by the Brownian motion. His discoveries had very interesting ramifications.
+
+First of all, it was a rare example of the situation, where an economist comes up with an idea, which only later is adopted by a physicist. And not just any physicist, but Albert Einstein himself. His work, which also used the concept of Brownian motion, has been awarded with the Nobel Prize.
+
+There was another beautiful coupling between physics and economy hidden in Bachelier's work. The student has shown that the same family of PDEs which dictate how the heat distribution evolves over time in a solid medium, can tell us how the value of an option changes with respect to the value of the underlying asset and time. It is stunning that a purely physical theory developed by Fourier, does describe the financial markets so accurately!
+
+Just to demonstrate - the heat equation for the 1D body (e.g. metal rod):
+
+$$
+\frac{\partial u}{\partial t}
+ = \alpha \left( \frac{\partial^2 u}{\partial x^2}\right)
+$$
+
+...versus the final Black-Scholes equation:
+
+$$
+\frac{\partial V}{\partial t}= -\frac{1}{2}\sigma^2 S^2 (\frac{\partial^2 V}{\partial S^2}) - rS\frac{\partial V}{\partial S} + rV
+$$
+
+Finally, it took almost 100 years for the brightest minds (among them PhDs from Yale and MIT) of the mathematics to actually solve the option pricing model. The duo Black and Scholes, but also an economist Robert Merton, came up independently with the solution, for which they have been awarded by a joint Noble prize. While the gentlemen received accolades for their research endeavours, Edward Thorp has managed to use Bachelier's framework several decades earlier. He has done it while managing an extremely successful hedge fund at Princeton Newport Partners. Finally, not only Thorp, but probably many financial engineers has benefited from arbitrage opportunities unlocked by the option pricing formula.
+
+## My Implementation of Option Pricing Mechanisms
+
+### Black-Scholes Formula
+
+It is a truly fascinating process to go through the derivation of the Black-Scholes formula. Starting from the definition of the Brownian motion, one uses Taylor's expansion to acquire the Black-Scholes differential equation and finally, by employing fundamentals of PDEs (including initial and boundary condiitons, particular structure of equation), one shall reach the final result:
+
+$$
+V(S, t)= N( d_1) S - N(d_2)K e^{-rt}
+$$
+
+where:
+
+$$
+d_1= \frac{1}{\sigma \sqrt{ t}} \left[\ln{\left(\frac{S}{K}\right)} + t\left(r + \frac{\sigma^2}{2} \right) \right]
+$$
+
+$$
+d_2= \frac{1}{\sigma \sqrt{ t}} \left[\ln{\left(\frac{S}{K}\right)} + t\left(r - \frac{\sigma^2}{2} \right) \right]
+$$
+
+From the model we are able to calculate the price of an option based on a number of different factors. To use Black-Scholes formula, we need first to figure out the value of the parameters of the equation:
+
+- $$K$$, the strike price. If we decide to buy an option, this what we obviously should now. This is our bet on the future price of the asset.
+- $$T$$, time to maturity is also known. This is when the option expires.
+- $$\sigma$$, the volatility. There are two ways to compute this value. We may retrieve the **implied volatility** from the current available options on the market for the same asset. Alternatively, and this is the approach in my implementation, we may use **historical volatility**- the standard deviation of log returns (difference of closing prices of the stock over consecutive days) over past data. The volatility is annualized to be consistent with the rest of the data.
+- $$r$$, annualized risk-free rate. In my implementation, this is the mean of the current interest rates on US treasury bill rates for different times of maturity.
+
+Finally, $$N(.)$$ is cumulative distribution function.
+
+ +
+Let's scrutinize two stocks with very different characteristics - volatile, young Tesla and steady, blue chip - Coca-Cola. As shown on the diagram above, there is little dispersion in the price of Coca-Cola. Tesla, on the contrary, is one of the hottest and most volatile stocks of the recent years. Please note that my results may be very particular. Due to the current situation on the markets, most of the stocks are characterised by unusually high volatility. At the same time, we are naturally experiencing very low interest rates. The options chosen are calls. The price of the premium is neglected, as well as the fact that KO pays regular dividends.
+
+```python
+INFO:root:
+ Today on 2020-04-09 00:00:00,
+ TSLA stock price is 573.0.
+ We agree on strike price 687.6.
+ Interest rate is: 0.242%, 180 days historical volatility is 0.83
+ The call matures in 60 days.
+INFO:root:
+ Today on 2020-04-09 00:00:00,
+ KO stock price is 49.0.
+ We agree on strike price 58.8.
+ Interest rate is: 0.242%, 180 days historical volatility is 0.34
+ The call matures in 60 days.
+
+```
+
+
+
+Let's scrutinize two stocks with very different characteristics - volatile, young Tesla and steady, blue chip - Coca-Cola. As shown on the diagram above, there is little dispersion in the price of Coca-Cola. Tesla, on the contrary, is one of the hottest and most volatile stocks of the recent years. Please note that my results may be very particular. Due to the current situation on the markets, most of the stocks are characterised by unusually high volatility. At the same time, we are naturally experiencing very low interest rates. The options chosen are calls. The price of the premium is neglected, as well as the fact that KO pays regular dividends.
+
+```python
+INFO:root:
+ Today on 2020-04-09 00:00:00,
+ TSLA stock price is 573.0.
+ We agree on strike price 687.6.
+ Interest rate is: 0.242%, 180 days historical volatility is 0.83
+ The call matures in 60 days.
+INFO:root:
+ Today on 2020-04-09 00:00:00,
+ KO stock price is 49.0.
+ We agree on strike price 58.8.
+ Interest rate is: 0.242%, 180 days historical volatility is 0.34
+ The call matures in 60 days.
+
+```
+
+ +
+
+
+ +
+Both plots tell us, how the function $$V(S,t)$$ behaves for a given pair of variables. One can observe that, for fixed $$t$$, the price of the option increases as the stock price increases. This makes sense, since it is increasingly more likely to expire with a positive value. Also, for fixed $$S$$ and decreasing $$t$$ (meaning we are approaching maturity), the call becomes worth less and less, since its value at expiration is become more and more certain. This means that the more volatility an option has, the more expensive it is. Why? Uncertainties are costly. Since costs raise prices, and volatility is an uncertainty, volatility raises prices.
+
+### Binomial Option Pricing Model
+
+For some applications, option pricing can be performed using the Binomial Option Pricing Model (BOPM). Both BOPM and Black-Scholes approach are built on the same assumptions. As a result, the binomial model provides a discrete time approximation for the continuous process underlying the Black–Scholes model. The binomial model assumes that movements in the price follow a binomial distribution. The derivation of BOPM is much more straightforward then the mathematics behind Black-Scholes. The final formula here is:
+
+$$
+V(S,t)=r^{-t}\sum_{k=0}^{t}\binom{t}{k}p^k(1-p)^{t-k}\max{(0, u^k d^{t-k}S-K)}
+$$
+
+where:
+
+$$
+p = \frac{r-d}{u-d}
+$$
+
+And $$u$$ and $$d$$ are specific factors of the asset price moving move up or down. Those can be deduced from the implied or historical volatility.
+
+
+
+Both plots tell us, how the function $$V(S,t)$$ behaves for a given pair of variables. One can observe that, for fixed $$t$$, the price of the option increases as the stock price increases. This makes sense, since it is increasingly more likely to expire with a positive value. Also, for fixed $$S$$ and decreasing $$t$$ (meaning we are approaching maturity), the call becomes worth less and less, since its value at expiration is become more and more certain. This means that the more volatility an option has, the more expensive it is. Why? Uncertainties are costly. Since costs raise prices, and volatility is an uncertainty, volatility raises prices.
+
+### Binomial Option Pricing Model
+
+For some applications, option pricing can be performed using the Binomial Option Pricing Model (BOPM). Both BOPM and Black-Scholes approach are built on the same assumptions. As a result, the binomial model provides a discrete time approximation for the continuous process underlying the Black–Scholes model. The binomial model assumes that movements in the price follow a binomial distribution. The derivation of BOPM is much more straightforward then the mathematics behind Black-Scholes. The final formula here is:
+
+$$
+V(S,t)=r^{-t}\sum_{k=0}^{t}\binom{t}{k}p^k(1-p)^{t-k}\max{(0, u^k d^{t-k}S-K)}
+$$
+
+where:
+
+$$
+p = \frac{r-d}{u-d}
+$$
+
+And $$u$$ and $$d$$ are specific factors of the asset price moving move up or down. Those can be deduced from the implied or historical volatility.
+
+ +
+
+
+ +
+As shown below, BOPM provides a good, discrete approximation to the Black-Scholes model.
+
+
+
+As shown below, BOPM provides a good, discrete approximation to the Black-Scholes model.
+
+
 +
+## Additional Reading
+1. The Man Who Solved the Market: How Jim Simons Launched the Quant Revolution, Gregory Zuckerman
+2. A Non-Random Walk Down Wall Street, Andrew Lo
+3. Options, Futures, and Other Derivatives, John C. Hull
+
+
diff --git a/_posts/2020-06-28-What-Matters-In-RL.md b/_posts/2020-06-28-What-Matters-In-RL.md
new file mode 100644
index 0000000000..6b02ae039a
--- /dev/null
+++ b/_posts/2020-06-28-What-Matters-In-RL.md
@@ -0,0 +1,160 @@
+---
+layout: post
+crosspost_to_medium: true
+title: "Research Paper Summary - What Matters In On-Policy Reinforcement Learning? A Large-Scale Empirical Study"
+author: "Damian Bogunowicz"
+categories: blog
+tags: [reinforcement learning, machine learning, summary, research]
+image: whatmatters.png
+
+---
+
+
+Recent paper from Google Brain team, [What Matters In On-Policy Reinforcement Learning? A Large-Scale Empirical Study](https://arxiv.org/abs/2006.05990), tackles one of the notoriously neglected problems in deep Reinforcement Learning (deep RL). I believe this is a pain point both for RL researchers and engineers:
+
+> Out of dozens of RL algorithm hyperparameters, which choices are actually important for the performance of the agent?
+>
+> In other words, the goal is to understand how the different choices affect the final performance of an agent and to derive recommendations for these choices.
+
+In this blog post I will go through the key takeaways from the paper. My goal is to present the learnings and briefly comment on them. **I believe that many of those findings may be hugely beneficial for any machine learning engineer who dips his toes in the field of RL.**
+
+Kudos for the Google Brain Team for compiling sort of a "check list" in their research paper. In every section they present the most important hyperparameters and suggest how one should go about initialising and tuning them. Even though this study is focused on the on-policy RL, the majority of learnings can be reused for off-policy algorithms.
+
+The reader can choose to quickly scam through the write-up to extract those "rules of thumb" but I recommend to read the source publication thoroughly. The study is really well documented with all the details explained.
+
+# Introduction
+
+I believe that the publication may resonate with many engineers out there. Once it has been decided that our particular problem can be solved using deep RL, the first step is usually to set up the RL scaffolding. Here, one could either reimplement an algorithm from the paper, along with the necessary infrastructure or just use one of the available RL frameworks: be it [Catalyst](https://github.com/catalyst-team/catalyst), [TF-Agents](https://github.com/tensorflow/agents) , [Acme](https://deepmind.com/research/publications/Acme) or [Ray](https://github.com/ray-project/ray). The second step is to design your environment. It will change over time and enrich our agent with the experience. Finally, the third step: run python script, monitor the training and tap yourself on the back. Tensorboard displays increasing average reward over time and our agent, slowly but surely, appears to acquire some form of intelligence...
+
+
+
+...well, in reality, **you would face TONS of problems on the way.** Those could be:
+
+1. The sheer amount of hyperparameters available for tuning. This includes both "ML-specific" choices (batch size, networks' architecture, learning rate), but also "RL-specific" (time discount $$\gamma$$, hyperparameters of advantage estimator). If your agent does not converge with default hyperparameters - bad luck. You will probably need to not only find out which hyperparameter is the key to your agent's performance, but also figure out its optimal value.
+2. It is quite likely that there are strong interactions existing between certain hyperparameters (e.g batch size and learning rate are very much intertwined). This makes the tuning complexity significantly harder.
+3. Same algorithms may be implemented differently in different research papers or RL frameworks. Your initial prototype of the PPO agent may be training fine. But later you would like to distribute your system using Ray framework, and their implementation of PPO could be slightly different. As the result, your previous hyperparameter configuration does not work for the current implementation.
+
+Point 3. Brings me to the the paper [Implementation Matters in Deep Policy Gradients: A Case Study on PPO and TRPO](https://arxiv.org/abs/2005.12729). This publication highlights the following problem: if your algorithm turns out to be superior to, let's say, current state-of-the-art, is it better because the algorithm is more clever, or you just used more favourable sets of hyperparameters (or simply just better code quality)?
+
+**All those aforementioned issues could be (partially) avoided if we had a sound understanding of the importance of various hyperparameters**. If we could draw some general conclusions about the significance of a particular configurations perhaps we could be more aware of its consequences on our RL system. Additionally, we could be less prone to mistaking more favourable hyperparameter configuration for superior algorithm design.
+
+# Experiments
+
+For benchmarking the researchers employ five, diverse OpenAI Gym environments: Hopper-v1, Walker2d-v1, HalfCheetah-v1, Ant-v1 and Humanoid-v1.
+
+They run about 250 000 experiments to investigate design choices from eight thematic groups:
+
+- *Policy Losses*
+- *Networks Architecture*
+- *Normalisation and Clipping*
+- *Advantage Estimation*
+- *Training Setup*
+- *Timestep Handling*
+- *Optimizers*
+- *Regularization*
+
+## Policy Losses
+
+**Design decisions:** choice of different policy losses (e.g. PPO, policy gradient, V-MPO etc.) on the performance of the benchmark environments.
+
+**Recommendation:**
+
+1. In the on-policy setting, PPO policy loss is a recommendable default choice for majority of environments.
+
+2. The PPO clipping threshold should be set by default to $$0.25$$ and then tuned.
+
+## Networks Architecture
+
+**Design decisions:** structure/size of actor/critic, activation functions, initialisation of network weights, standard deviations of actions, transformations of sampled actions.
+
+**Takeaways:**
+
+1. Initialize the last policy layer with $$100\times$$ smaller weights.
+
+2. Use softplus to transform network input into action standard deviation and add a (negative) offset to its input to decrease the initial standard deviations of actions. Tune this offset if possible.
+
+3. Use tanh both as the activation function (if the networks are not too deep) and to transform the samples from the normal distribution to the bounded action space.
+
+4. Use a wide value MLP (no layers shared with the policy) but tune the policy width (it might need to be narrower then the value MLP).
+
+**Comments:**
+
+1. Prior to reading this study, I had the impression that sharing some layers between actor and critic is beneficial for the agent. I reasoned that parameter sharing could accelerate training (gradient flowing from both the actor and the critic). However, I have learned that the norm of gradients flowing back from the actor and the critic could be at completely different scale. As a result, actor's gradients may destabilise critic's parameters and vice-versa. This is probably the reason for keeping policy and value network separate.
+2. Surprisingly, it is better to use tanh activations rather than ReLU between actor's/critic's MLP layers. But only networks with limited capacity shall benefit from it. Anecdotically, tanh activation tends to be more reliable when you have smaller networks. It learns faster and is less sensitive to big differences in input features than ReLU.
+3. The authors repetitively stress the importance of weights initialisation in actor's final layer. Those weights should be very small, so that the initial action distribution is centred around zero with a small standard deviation. The authors claim that this boosts performance of an agent, but do not give an intuition why. Perhaps this way we avoid biasing the agent towards some certain, suboptimal trajectory ahead of time (from which the agent may not fully recover).
+
+## Normalisation and Clipping
+
+**Design decisions:** observation normalisation, value function normalisation, per-minibatch advantage normalisation, gradient and observation clipping.
+
+**Takeaways:**
+
+1. Always use observation normalisation and check if value function normalisation improves performance.
+
+2. Gradient clipping might slightly help but is of secondary importance.
+
+**Comments:** Not surprisingly, observation normalisation is crucial. This is true for most of the (un-) supervised machine learning algorithms. However, I am personally (anecdotally) quite sure that gradient clipping tends to help a lot in certain situations. But naturally, this could be more or less true depending on the particular environment.
+
+## Advantage Estimation
+
+**Design decisions:** choice of different advantage estimators (e.g. GAE, N-step) and their hyperparameters on the performance of the benchmark environments.
+
+**Recommendation:**
+
+1. In the on-policy setting, GAE with $$\lambda=0.9$$ is a recommendable default choice for majority of environments.
+
+## Training Setup
+
+**Design decisions:** number of parallel environments, number of transitions gathered in each iteration, number of passes over the data, mini batch size, how the data is split into mini batches
+
+**Takeaways:**
+
+1. Go over experience multiple times (allows to quickly find an approximately optimal policy).
+
+2. Shuffle individual transitions before assigning them to mini batches and recompute advantages once per data pass (PPO-specific advice).
+
+3. For faster wall-clock time training use many parallel environments and increase the batch size (both might hurt the sample complexity).
+
+4. Tune the number of transitions in each iteration if possible.
+
+**Comments:** This paragraph has brought my attention to the fact that naively increasing number of parallel environments does not automatically lead to faster training. Over last few months I have noticed some TF-Agents users actually complaining that it can actually be harmful ([here](https://github.com/tensorflow/agents/issues/336)). This is definitely something I would like to investigate further.
+
+## Timesteps Handling
+
+**Design decisions:** discount factor $$\gamma$$, frame skip, episode termination handling.
+
+**Takeaways:**
+
+1. Discount factor $$\gamma$$ turns out to be pretty crucial for the performance and should be individually tuned for every environment (with the default value of 0.99).
+
+2. Frame skipping (the number of frames an action is repeated before a new action is selected) can also help in some cases.
+
+3. For large step limits, there is no need to handle environment step limits.
+
+**Comments:** One of the problems with the conventional RL benchmarks is the fact, that we test agents in environments where episodes have fixed number of steps. However, this information is hardly ever contained in the agent's state and thus violates the Markovian assumption of MPDs. Why assuming infinite time horizon but training for finite time horizon could be a problem? Think about a tie in the basketball game. Players may employ very different strategies if the draw happens in the middle of the game or just before the final whistle. But agents usually do not take this crucial information into consideration. We can treat those problematic, abandoned last steps either as terminal steps, or assume that we do not know what would happen if the episode was not terminated.
+
+The experiments show that it is not important how we handle abandoned episodes, as long as the number of time steps is large. So I guess it is fair to assume, that for more complex environments and/or smaller number of time steps in an episode, this statement may not hold true anymore.
+
+## Optimizers
+
+**Design decisions:** choice of different gradient-based optimizers (e.g. Adam, RMSprop) and their hyperparameters on the performance of the benchmark environments.
+
+**Takeaway:**
+
+1. As a default, use Adam optimizer with momentum $$\beta_{1}=0.9$$ . Start with the default learning rate $$0.0003$$, but be sure to adjust it to your problem.
+
+2. Linear decaying may slightly improve the performance.
+
+**Comments:** This is pretty much consistent with what we already know about the most popular optimizers. Adam is pretty much always a safe default. And regarding the default learning rate, well, Andrej Karpathy pretty much said it [four years ago](https://twitter.com/karpathy/status/801621764144971776?s=20).
+
+## Regularization
+
+**Design decisions:** choice of different policy regularisers (e.g. entropy, KL divergence between action distribution and a unit Gaussian) and their hyperparameters on the performance of the benchmark environments.
+
+**Takeaway:**
+
+Well, here the results of the experiments were not very spectacular. Any form of regularization (be it entropy, Kullback-Leibler divergence between the unit Gaussian and the policy action distribution, reverse KL divergence between the target and behavioural policy) does not help much. But we have to keep in mind, that all the agents were trained with the PPO loss, which already enforces the trust region. This means that it already incorporates a certain form of regularization.
+
+# Conclusions
+
+**I am really happy that there are people who are looking into "practical" aspects of deep RL such as reproducibility or good engineering practices**. It's great that researchers are looking for some general rules which may hold true for majority of problems and could be used to accelerate deep RL prototyping. **I would like to conclude this write-up with one, crucial critique of the publication**: the authors have been conducting this study for a very limited set of benchmark environments. All of them assume state and observation space to be 1D vectors and they all can be "solved" using MLP-based networks. I wonder if some of those learnings are also valid for more complex tasks, be it multi-agent settings or agents which deal with large state spaces (e.g work with multimodal camera input)?
diff --git a/_posts/2020-10-12-AI-Economist.md b/_posts/2020-10-12-AI-Economist.md
new file mode 100644
index 0000000000..aec637486d
--- /dev/null
+++ b/_posts/2020-10-12-AI-Economist.md
@@ -0,0 +1,204 @@
+---
+layout: post
+title: "Research Paper Summary - The AI Economist: Improving Equality and Productivity with AI-Driven Tax Policies"
+author: "Damian Bogunowicz"
+categories: blog
+tags: [AI, economics, deep reinforcement learning]
+image: ai-economist.jpg
+
+---
+ All the figures in this post come from the research publication: The AI Economist: Improving Equality and Productivity with AI-Driven Tax Policies (Zheng et al. 2020)
+
+It is really refreshing to see that machine learning, especially reinforcement learning, can be successfully used in social sciences. The recent research from the Salesforce team, the [AI Economist](https://arxiv.org/abs/2004.13332), is a study on how to improve economic design through the AI-driven simulation. The goal of the study is to **optimise productivity and social equality of the economy**. The AI framework has been designed to simulate millions of years of economies to help economists, governments and others design tax policies that strive for fair social outcomes in the real world.
+
+I am personally really excited about the fact, that we can use simulation and reinforcement learning to replicate the mechanics of economic behaviour and generate data, which is otherwise very expensive and difficult to collect. It takes decades or even centuries to generate information about economic activity of some economies. So how about, instead of waiting that long, replicating the behaviour of the population using fast, parallel simulated worlds?
+
+There are two types of actors in the economic simulation: **AI Citizens** (members of the community focused on maximising their wealth) and the **AI Government** (the overseer which attempts to maximise the social welfare of the community).
+
+## The AI Citizens
+
+### Gather-and-Build Game
+
+
+## Additional Reading
+1. The Man Who Solved the Market: How Jim Simons Launched the Quant Revolution, Gregory Zuckerman
+2. A Non-Random Walk Down Wall Street, Andrew Lo
+3. Options, Futures, and Other Derivatives, John C. Hull
+
+
diff --git a/_posts/2020-06-28-What-Matters-In-RL.md b/_posts/2020-06-28-What-Matters-In-RL.md
new file mode 100644
index 0000000000..6b02ae039a
--- /dev/null
+++ b/_posts/2020-06-28-What-Matters-In-RL.md
@@ -0,0 +1,160 @@
+---
+layout: post
+crosspost_to_medium: true
+title: "Research Paper Summary - What Matters In On-Policy Reinforcement Learning? A Large-Scale Empirical Study"
+author: "Damian Bogunowicz"
+categories: blog
+tags: [reinforcement learning, machine learning, summary, research]
+image: whatmatters.png
+
+---
+
+
+Recent paper from Google Brain team, [What Matters In On-Policy Reinforcement Learning? A Large-Scale Empirical Study](https://arxiv.org/abs/2006.05990), tackles one of the notoriously neglected problems in deep Reinforcement Learning (deep RL). I believe this is a pain point both for RL researchers and engineers:
+
+> Out of dozens of RL algorithm hyperparameters, which choices are actually important for the performance of the agent?
+>
+> In other words, the goal is to understand how the different choices affect the final performance of an agent and to derive recommendations for these choices.
+
+In this blog post I will go through the key takeaways from the paper. My goal is to present the learnings and briefly comment on them. **I believe that many of those findings may be hugely beneficial for any machine learning engineer who dips his toes in the field of RL.**
+
+Kudos for the Google Brain Team for compiling sort of a "check list" in their research paper. In every section they present the most important hyperparameters and suggest how one should go about initialising and tuning them. Even though this study is focused on the on-policy RL, the majority of learnings can be reused for off-policy algorithms.
+
+The reader can choose to quickly scam through the write-up to extract those "rules of thumb" but I recommend to read the source publication thoroughly. The study is really well documented with all the details explained.
+
+# Introduction
+
+I believe that the publication may resonate with many engineers out there. Once it has been decided that our particular problem can be solved using deep RL, the first step is usually to set up the RL scaffolding. Here, one could either reimplement an algorithm from the paper, along with the necessary infrastructure or just use one of the available RL frameworks: be it [Catalyst](https://github.com/catalyst-team/catalyst), [TF-Agents](https://github.com/tensorflow/agents) , [Acme](https://deepmind.com/research/publications/Acme) or [Ray](https://github.com/ray-project/ray). The second step is to design your environment. It will change over time and enrich our agent with the experience. Finally, the third step: run python script, monitor the training and tap yourself on the back. Tensorboard displays increasing average reward over time and our agent, slowly but surely, appears to acquire some form of intelligence...
+
+
+
+...well, in reality, **you would face TONS of problems on the way.** Those could be:
+
+1. The sheer amount of hyperparameters available for tuning. This includes both "ML-specific" choices (batch size, networks' architecture, learning rate), but also "RL-specific" (time discount $$\gamma$$, hyperparameters of advantage estimator). If your agent does not converge with default hyperparameters - bad luck. You will probably need to not only find out which hyperparameter is the key to your agent's performance, but also figure out its optimal value.
+2. It is quite likely that there are strong interactions existing between certain hyperparameters (e.g batch size and learning rate are very much intertwined). This makes the tuning complexity significantly harder.
+3. Same algorithms may be implemented differently in different research papers or RL frameworks. Your initial prototype of the PPO agent may be training fine. But later you would like to distribute your system using Ray framework, and their implementation of PPO could be slightly different. As the result, your previous hyperparameter configuration does not work for the current implementation.
+
+Point 3. Brings me to the the paper [Implementation Matters in Deep Policy Gradients: A Case Study on PPO and TRPO](https://arxiv.org/abs/2005.12729). This publication highlights the following problem: if your algorithm turns out to be superior to, let's say, current state-of-the-art, is it better because the algorithm is more clever, or you just used more favourable sets of hyperparameters (or simply just better code quality)?
+
+**All those aforementioned issues could be (partially) avoided if we had a sound understanding of the importance of various hyperparameters**. If we could draw some general conclusions about the significance of a particular configurations perhaps we could be more aware of its consequences on our RL system. Additionally, we could be less prone to mistaking more favourable hyperparameter configuration for superior algorithm design.
+
+# Experiments
+
+For benchmarking the researchers employ five, diverse OpenAI Gym environments: Hopper-v1, Walker2d-v1, HalfCheetah-v1, Ant-v1 and Humanoid-v1.
+
+They run about 250 000 experiments to investigate design choices from eight thematic groups:
+
+- *Policy Losses*
+- *Networks Architecture*
+- *Normalisation and Clipping*
+- *Advantage Estimation*
+- *Training Setup*
+- *Timestep Handling*
+- *Optimizers*
+- *Regularization*
+
+## Policy Losses
+
+**Design decisions:** choice of different policy losses (e.g. PPO, policy gradient, V-MPO etc.) on the performance of the benchmark environments.
+
+**Recommendation:**
+
+1. In the on-policy setting, PPO policy loss is a recommendable default choice for majority of environments.
+
+2. The PPO clipping threshold should be set by default to $$0.25$$ and then tuned.
+
+## Networks Architecture
+
+**Design decisions:** structure/size of actor/critic, activation functions, initialisation of network weights, standard deviations of actions, transformations of sampled actions.
+
+**Takeaways:**
+
+1. Initialize the last policy layer with $$100\times$$ smaller weights.
+
+2. Use softplus to transform network input into action standard deviation and add a (negative) offset to its input to decrease the initial standard deviations of actions. Tune this offset if possible.
+
+3. Use tanh both as the activation function (if the networks are not too deep) and to transform the samples from the normal distribution to the bounded action space.
+
+4. Use a wide value MLP (no layers shared with the policy) but tune the policy width (it might need to be narrower then the value MLP).
+
+**Comments:**
+
+1. Prior to reading this study, I had the impression that sharing some layers between actor and critic is beneficial for the agent. I reasoned that parameter sharing could accelerate training (gradient flowing from both the actor and the critic). However, I have learned that the norm of gradients flowing back from the actor and the critic could be at completely different scale. As a result, actor's gradients may destabilise critic's parameters and vice-versa. This is probably the reason for keeping policy and value network separate.
+2. Surprisingly, it is better to use tanh activations rather than ReLU between actor's/critic's MLP layers. But only networks with limited capacity shall benefit from it. Anecdotically, tanh activation tends to be more reliable when you have smaller networks. It learns faster and is less sensitive to big differences in input features than ReLU.
+3. The authors repetitively stress the importance of weights initialisation in actor's final layer. Those weights should be very small, so that the initial action distribution is centred around zero with a small standard deviation. The authors claim that this boosts performance of an agent, but do not give an intuition why. Perhaps this way we avoid biasing the agent towards some certain, suboptimal trajectory ahead of time (from which the agent may not fully recover).
+
+## Normalisation and Clipping
+
+**Design decisions:** observation normalisation, value function normalisation, per-minibatch advantage normalisation, gradient and observation clipping.
+
+**Takeaways:**
+
+1. Always use observation normalisation and check if value function normalisation improves performance.
+
+2. Gradient clipping might slightly help but is of secondary importance.
+
+**Comments:** Not surprisingly, observation normalisation is crucial. This is true for most of the (un-) supervised machine learning algorithms. However, I am personally (anecdotally) quite sure that gradient clipping tends to help a lot in certain situations. But naturally, this could be more or less true depending on the particular environment.
+
+## Advantage Estimation
+
+**Design decisions:** choice of different advantage estimators (e.g. GAE, N-step) and their hyperparameters on the performance of the benchmark environments.
+
+**Recommendation:**
+
+1. In the on-policy setting, GAE with $$\lambda=0.9$$ is a recommendable default choice for majority of environments.
+
+## Training Setup
+
+**Design decisions:** number of parallel environments, number of transitions gathered in each iteration, number of passes over the data, mini batch size, how the data is split into mini batches
+
+**Takeaways:**
+
+1. Go over experience multiple times (allows to quickly find an approximately optimal policy).
+
+2. Shuffle individual transitions before assigning them to mini batches and recompute advantages once per data pass (PPO-specific advice).
+
+3. For faster wall-clock time training use many parallel environments and increase the batch size (both might hurt the sample complexity).
+
+4. Tune the number of transitions in each iteration if possible.
+
+**Comments:** This paragraph has brought my attention to the fact that naively increasing number of parallel environments does not automatically lead to faster training. Over last few months I have noticed some TF-Agents users actually complaining that it can actually be harmful ([here](https://github.com/tensorflow/agents/issues/336)). This is definitely something I would like to investigate further.
+
+## Timesteps Handling
+
+**Design decisions:** discount factor $$\gamma$$, frame skip, episode termination handling.
+
+**Takeaways:**
+
+1. Discount factor $$\gamma$$ turns out to be pretty crucial for the performance and should be individually tuned for every environment (with the default value of 0.99).
+
+2. Frame skipping (the number of frames an action is repeated before a new action is selected) can also help in some cases.
+
+3. For large step limits, there is no need to handle environment step limits.
+
+**Comments:** One of the problems with the conventional RL benchmarks is the fact, that we test agents in environments where episodes have fixed number of steps. However, this information is hardly ever contained in the agent's state and thus violates the Markovian assumption of MPDs. Why assuming infinite time horizon but training for finite time horizon could be a problem? Think about a tie in the basketball game. Players may employ very different strategies if the draw happens in the middle of the game or just before the final whistle. But agents usually do not take this crucial information into consideration. We can treat those problematic, abandoned last steps either as terminal steps, or assume that we do not know what would happen if the episode was not terminated.
+
+The experiments show that it is not important how we handle abandoned episodes, as long as the number of time steps is large. So I guess it is fair to assume, that for more complex environments and/or smaller number of time steps in an episode, this statement may not hold true anymore.
+
+## Optimizers
+
+**Design decisions:** choice of different gradient-based optimizers (e.g. Adam, RMSprop) and their hyperparameters on the performance of the benchmark environments.
+
+**Takeaway:**
+
+1. As a default, use Adam optimizer with momentum $$\beta_{1}=0.9$$ . Start with the default learning rate $$0.0003$$, but be sure to adjust it to your problem.
+
+2. Linear decaying may slightly improve the performance.
+
+**Comments:** This is pretty much consistent with what we already know about the most popular optimizers. Adam is pretty much always a safe default. And regarding the default learning rate, well, Andrej Karpathy pretty much said it [four years ago](https://twitter.com/karpathy/status/801621764144971776?s=20).
+
+## Regularization
+
+**Design decisions:** choice of different policy regularisers (e.g. entropy, KL divergence between action distribution and a unit Gaussian) and their hyperparameters on the performance of the benchmark environments.
+
+**Takeaway:**
+
+Well, here the results of the experiments were not very spectacular. Any form of regularization (be it entropy, Kullback-Leibler divergence between the unit Gaussian and the policy action distribution, reverse KL divergence between the target and behavioural policy) does not help much. But we have to keep in mind, that all the agents were trained with the PPO loss, which already enforces the trust region. This means that it already incorporates a certain form of regularization.
+
+# Conclusions
+
+**I am really happy that there are people who are looking into "practical" aspects of deep RL such as reproducibility or good engineering practices**. It's great that researchers are looking for some general rules which may hold true for majority of problems and could be used to accelerate deep RL prototyping. **I would like to conclude this write-up with one, crucial critique of the publication**: the authors have been conducting this study for a very limited set of benchmark environments. All of them assume state and observation space to be 1D vectors and they all can be "solved" using MLP-based networks. I wonder if some of those learnings are also valid for more complex tasks, be it multi-agent settings or agents which deal with large state spaces (e.g work with multimodal camera input)?
diff --git a/_posts/2020-10-12-AI-Economist.md b/_posts/2020-10-12-AI-Economist.md
new file mode 100644
index 0000000000..aec637486d
--- /dev/null
+++ b/_posts/2020-10-12-AI-Economist.md
@@ -0,0 +1,204 @@
+---
+layout: post
+title: "Research Paper Summary - The AI Economist: Improving Equality and Productivity with AI-Driven Tax Policies"
+author: "Damian Bogunowicz"
+categories: blog
+tags: [AI, economics, deep reinforcement learning]
+image: ai-economist.jpg
+
+---
+ All the figures in this post come from the research publication: The AI Economist: Improving Equality and Productivity with AI-Driven Tax Policies (Zheng et al. 2020)
+
+It is really refreshing to see that machine learning, especially reinforcement learning, can be successfully used in social sciences. The recent research from the Salesforce team, the [AI Economist](https://arxiv.org/abs/2004.13332), is a study on how to improve economic design through the AI-driven simulation. The goal of the study is to **optimise productivity and social equality of the economy**. The AI framework has been designed to simulate millions of years of economies to help economists, governments and others design tax policies that strive for fair social outcomes in the real world.
+
+I am personally really excited about the fact, that we can use simulation and reinforcement learning to replicate the mechanics of economic behaviour and generate data, which is otherwise very expensive and difficult to collect. It takes decades or even centuries to generate information about economic activity of some economies. So how about, instead of waiting that long, replicating the behaviour of the population using fast, parallel simulated worlds?
+
+There are two types of actors in the economic simulation: **AI Citizens** (members of the community focused on maximising their wealth) and the **AI Government** (the overseer which attempts to maximise the social welfare of the community).
+
+## The AI Citizens
+
+### Gather-and-Build Game
+
+  +
+
+The rules of the modelled world, the **Gather-and-Build Game**, are quite simple. One could even argue that the simplicity of the simulation is the one of the biggest flaws of the study. Obviously, the hand-designed environments are bound to miss many of the subtleties of economics.
+
+The community consists of four citizens. Each of the citizens can choose between four actions:
+
+- Move - up, down, left, right in the 2d grid-world environment.
+- Harvest resources - there are two assets in the game, wood and stone.
+- Trade - there is an in-game trade market implemented, where agents can publish bids and ask prices to buy or sell the resources.
+- Build houses - to build a house, an agent needs to spend one unit of wood and one unit of stone.
+
+Additionally, every action requires some labor to be performed by the agent. This is quite an important feature of agent's psychology: doing any kind of work is **inherently undesirable by the rational agent**.
+
+### Heterogeneities
+
+Heterogeneities of the citizens are the main driver of **inequality and specialisation** in the simulation. Agents differ in:
+
+- Spawn location - if an agent spawns close to the "forest", it is more likely that it will specialise in collecting and trading wood.
+- Builder skill - high builder skill means that building houses is more profitable for an agent.
+- Harvester skill - high harvester skill means that an agent has high probability of gaining bonus resources when collecting wood or stone.
+
+### Citizen's Goal
+
+Citizens are fundamentally simplistic creatures. Their goal is to become wealthy. However, not at all costs. They also strive to avoid performing any labor at all. How? In economics and AI, the desires or preferences of rational agents are being modelled by the **utility** **function**. If we consume some kind of item, we derive satisfaction (utility) from it. Our citizen $$i$$ at time $$t$$ derives pleasure from its coins $$x_{i,t}^{c}$$ and dissatisfaction from performing labor $$l_{i,t}$$:
+
+$$
+u_i(x_{i,t},l_{i,t})=crra(x^{c}_{i,t})-l_{i,t}
+$$
+
+
+Let's take a look at the $$crra$$ function. It is agreed that the utility of homo economicus (rational, economic human) is not linear - it is governed by **the law of diminishing returns**. The law states that the marginal utility of a good declines as its available supply increases. This can be illustrated by the example.
+
+Imagine it's a hot, summer day and you lucky to be participate in all-you-can eat ice-cream buffet. You have an unlimited supply of the treat, so you start consuming ice-cream, one after another. Let's assume that the utility for eating the ice-cream is initially equal to one:
+
+- Your first ice-cream will be cold, refreshing and very delicious (marginal utility of 1).
+- Your third ice-cream will still be sweet and tasty, but not as amazing as the first one (marginal utility is smaller, let's say 0.5).
+- You will probably refuse to eat the tenth ice-cream - otherwise you will get quite queasy (negative utility - you don't even want to any more ice-cream!)
+
+This law is implemented in our agents behaviour through the function $$crra$$. In the context of our simulation, we can substitute ice-cream with houses. We can see that the utility grows initially with the amount of houses built by the agent, but at some point it starts to decline.
+
+  +
+
+The goal of the citizens is to maximum the sum of their total discounted future utility:
+
+$$
+\forall i:
+ \max_{\pi_i}
+ \mathbb{E}_{
+ a_i \sim \pi_i,
+ \mathbf{a}_{-i} \sim \mathbf{\pi}_{-i},
+ s' \sim \mathscr{T}
+ }[{
+ \sum_{t = 1}^H \gamma^t
+ \underbrace{({
+ u_i(x_{i,t}, l_{i,t} )
+ - u_i(x_{i,t-1}, l_{i,t-1} )
+ }}_{=\hspace{2pt} r_{i,t}}
+ + u_i( x_{i,0}, l_{i,0} )]
+ }
+$$
+
+### Example of an Episode
+
+
+  +
+
+
+The figure above show the economic simulation in which four agents collect and trade resources, build houses and earn income. **Red** and **orange** agents were endowed with very low house-building skill, so they specialise in collecting and trading wood/stones for coins. The **teal** agent seems to be the jack of all trades, building moderate amounts of houses and collecting some resources. **Dark blue** agent (high house-building skill) actively buys most of the resources from the market and floods the world with its houses.
+
+The size of the circle shows total productivity, while colours of the pie chart show the percentage of economy's wealth each agent owns. The trade-off between equality and productivity is measured by multiplying equality and productivity.
+
+## The AI Government
+
+The AI Government is the entity which oversees the community and tries to come up with a tax policy which is the most beneficial for the overall economy.
+
+### Collecting Taxes
+
+Every episode is divided into ten periods. At the end of each period, the government observes citizen's income (total number of coins) - $$z^{p}_{i}$$ of an agent $$i$$ after the period $$p$$ - and takes away some of its capital governed by the tax function $$T$$ . Finally, once all taxes are collected, the government sums them up and redistributes the amount equally among the community.
+
+So the post-tax income of agent $$i$$ in the period $$p$$ is given by:
+
+$$
+\widetilde{z}^p_i = z^p_i - T(z^p_i) + \frac{1}{N} \sum_{j=1}^N T(z^p_j).
+$$
+
+The amount of tax $$T(z)$$ imposed on agent's income $$z$$ in a tax period $$p$$ is computed by taking the sum of the amount of income within each bracket $$[m_b, m_{b+1}]$$ times that bracket's marginal rate $$\tau_b$$:
+
+$$
+T(z)=\sum_{b=0}^{B-1} \tau_b \cdot ({
+ ({m_{b+1} - m_b })\mathbf{1}[z > m_{b+1} ]
+ + ({z - m_b }) \mathbf{1}[m_b < z \leq m_{b+1} ]
+ }
+$$
+
+where $$\mathbf{1}[ z > m_{b+1}]$$ is an indicator function for whether $$z$$ saturates bracket $$b$$ and $$\mathbf{1}[ m_b < z \leq m_{b+1} ]$$ is an indicator function for whether $$z$$ falls within bracket $$b$$.
+
+### AI Government's Goal
+
+
+
+
+The AI government's goal is to maximise the social warfare of the community, defined by the **social welfare function** $$swf$$. The social welfare function can be defined in many ways, but in this paper the authors decide to tackle the fundamental trade-off between **income equality** and **productivity**.
+
+- If income equality is high, this means that the most productive members of the community are financially supporting the least productive agents (which is characteristic for e.g. centrally planned economies). Obviously, those most productive members are disincentivized - they do not want to perform labor from which they do not gain any coins - so the productivity falls.
+
+- If productivity is high (essentially unregulated, free market), the most productive members thrive, but agents who are less fortunate (e.g. are "born" with low skills) barely make a living.
+
+
+  +
+
+World map of the GINI coefficients by country. Based on World Bank data ranging from 1992 to 2018. Source: wikipedia
+
+The economic quantity which gauges of economic inequality is the Gini index. Therefore, to express the inequality we can use the compliment of the Gini index computed for the toy community.
+
+$$
+eq(\mathbf{x}^c)=1 - gini(\mathbf{x}^c)\frac{N}{N-1}
+$$
+
+To measure the economic productivity, we can take the sum of all the coins in the economy:
+
+$$
+prod(\mathbf{x}^c)=\sum_{i=1}^{N}x_i^c
+$$
+
+The social welfare function is simply the product of income equality and productivity:
+
+$$
+swf_t(\mathbf{x}_t^c) = eq_t(\mathbf{x}_t^c)\cdot prod_t(\mathbf{x}_t^c)
+$$
+
+The AI Government's (denoted as $$p$$) objective is to maximise the social welfare:
+
+$$
+\max_{\pi_p}
+ \mathbb{E}_{
+ tau \sim \pi_p,
+ \mathbf{a}_{i} \sim \mathbf{\pi}_{i},
+ s' \sim \mathscr{T}
+ }[{
+ \sum_{t = 1}^H \gamma^t
+ \underbrace{({
+ swf_t -swtf_{t+1})
+ }}_{=\hspace{2pt} r_{p,t}}
+ + swf_0]
+ }
+$$
+
+## Two-Phase Training
+
+The authors report that the joint optimisation of the AI citizens and AI Government **is not straightforward and may suffer from training instability in early episodes** (which is not surprising giving that the joint objective resembles a min-max game). To solve this problem, the two-phase training approach is being used:
+
+- **Phase 1**: agents are being trained in the tax-free world (essentially free-market scenario).
+- **Phase 2**: the training is continued, but community is gently introduced to the AI Government and the concept of income redistribution. To avoid unstable learning dynamics created by the sudden introduction of taxes, the marginal tax rates are linearly annealed from 10% to 100%.
+
+## The AI Taxation Policy
+
+
+
+The figure illustrates **the comparison of overall economic outcomes**. The AI Economist achieves significantly better equality-productivity trade-offs compared to the baseline models: **free-market economy, US-Fed tax policy and Saez formula (model of optimal income tax rate developed by [Emmanuel Saez (2001)](https://eml.berkeley.edu/~saez/derive.pdf)**. Note, that the AI Economist, while initially being very socialistic (prefers equality to productivity), finally converges to the optimal equilibrium point, where those two objectives are **relatively balanced**.
+
+
+
+The figure shows **the marginal taxes rates** for each of the baselines (except for the free-market where taxes do not exist). On average, **the AI Economist sets a higher top tax rate than both of the US Federal and Saez tax schedules**. It seems that it favours two groups of citizens: agents which earn little (but no too little) and the "middle-class". Those two groups benefit from sharply reduced tax rates. Maybe the AI gives us a hint, that we should keep the taxes low for the middle class? Or that we shall tax the poorest to incentivise them to work?
+
+Truth be told, I am quite sceptical about saying that the AI Government has "came up" with some certain taxation policy - the model is far too simple. After all, the simulated economy consists of only four citizens and it seems that every episode results in the same occupation distribution. Those are two low-income agents (stone and wood harvesters), one "jack of all trades" and one high-income house builder: not really a very robust result.
+
+### Applying AI Taxation to Real Humans
+
+The researchers conclude the paper with an interesting study. They employ **human participants** on Amazon Mechanical Turk platform to investigate whether AI Economist tax policy can **transfer to economic activity of real people without extensive fine-tuning**. Human participants play the Gather-and-Build Game with the goal of maximising their wealth, while being the subject to baseline and AI Economist taxation policies.
+
+
+
+The figure above presents the results of tax policy transfer for game with 58 human participants in 51 episodes. Each episode involves four participants. The AI Economist achieves competitive equality-productivity trade-offs with the baselines, and statistically significantly outperforms the free market.
+
+What really sparks my interest is the fact, that the behaviour of human participants and trained AI agents differ significantly. For example, it has been observed that humans tend to block other players and otherwise display adversarial behaviour.
+
+## Conclusion
+This work from Salesforce team shows that **AI-based, economic simulators for learning economic policies have the potential to be useful in the real world**. I am really excited to see more research, which tries to apply AI to social sciences and solve some of the vast puzzles, which we encounter in economy both in the micro and macro scale. For more information, check out the paper, as well as the [Salesforce's blog post on the AI Economist](https://blog.einstein.ai/the-ai-economist/). They also published a great video intro to the publication on [YouTube](https://www.youtube.com/watch?v=4iQUcGyQhdA&feature=emb_title). Finally, the project's [code has been released to the public](https://github.com/salesforce/ai-economist)!
+
+
+
+
+
diff --git a/_posts/2020-10-21-Robotic-Assembly.md b/_posts/2020-10-21-Robotic-Assembly.md
new file mode 100644
index 0000000000..bda3ffe8ad
--- /dev/null
+++ b/_posts/2020-10-21-Robotic-Assembly.md
@@ -0,0 +1,288 @@
+---
+layout: post
+title: "Robotic Assembly Using Deep Reinforcement Learning"
+author: "Damian Bogunowicz"
+categories: blog
+tags: [robotics, sim2real, deep reinforcement learning]
+image: tutorial_gif.gif
+
+---
+## Introduction
+
+**Disclaimer**: This article is a cross post from [Pytorch Medium Blog Post](https://link.medium.com/gwm2y0JdPab ).
+
+One of the most exciting advancements, that has pushed the frontier of the Artificial Intelligence (AI) in recent years, is Deep Reinforcement Learning (DRL). DRL belongs to the family of machine learning algorithms. It assumes that intelligent machines can learn from their actions similar to the way humans learn from experience. Over the recent years we could witness some impressive [real-world applications of DRL](https://neptune.ai/blog/reinforcement-learning-applications). The algorithms allowed for major progress especially in the field of robotics. If you are interested in learning more about DRL, we encourage you to get familiar with the exceptional [**Introduction to RL**](https://spinningup.openai.com/en/latest) by OpenAI. We believe this is the best place to start your adventure with DRL.
+
+The **goal of this tutorial is to show how you can apply DRL to solve your own robotic challenge**. For the sake of this tutorial we have chosen one of the classic assembly tasks: peg-in-hole insertion. By the time you finish the tutorial, you will understand how to create a complete, end-to-end pipeline for training the robot in the simulation using DRL.
+
+The accompanying code together with all the details of the implementation can be found in our [GitHub repository](https://github.com/arrival-ltd/catalyst-rl-tutorial).
+
+## Setup
+1. Download the **robot simulation platform**, CoppeliaSim, from [the official website](https://www.coppeliarobotics.com/downloads). This tutorial is compatible with the version 4.1.0.
+
+2. Setup **toolkit for robot learning research**, PyRep, from their [github repository](https://github.com/stepjam/PyRep). PyRep library is built on top of CoppeliaSim to facilitate prototyping in python.
+
+3. Create **an environment for the RL agent**: It could be either a simulation or a real environment. We limit ourselves to simulation for faster prototyping and training. The agent interacts with the environment to collect experience. This allows it to learn a policy which maximizes the expected (discounted) sum of future rewards and hence solves the designed task. Most RL practitioners are familiar with the [OpenAI Gym environments](https://gym.openai.com/envs/#classic_control), a toolkit with toy environments used for developing and benchmarking reinforcement learning algorithms. However, our use case, robotic assembly task, is very specific. The goal is to train a robot to perform peg-in-hole insertion. This is why we created our simulation environment in [CoppeliaSim](https://www.coppeliarobotics.com). The simulator comes with various robot manipulators and grippers. For our tutorial, we picked UR5 robot with RG2 gripper (Figure 1).
+ 
+
+ Figure 1: UR5 manipulator with a peg attached to its gripper. The mating part is placed on the ground in the scene. CoppeliaSim caters to a variety of different robotic tasks. Feel free to come up with your own challenge and design your own simulation! [RLBench](https://github.com/stepjam/RLBench/tree/master/rlbench/task_ttms) (the robot learning benchmark and learning environment) also provides more off-the-shelf, advanced simulation environments.
+
+4. Create **a gym environment wrapped around the simulation scene**:
+
+```python
+import os
+import cv2
+import logging
+import numpy as np
+
+from gym import Space
+from gym.spaces.box import Box
+from gym.spaces.dict import Dict
+from pyrep import PyRep, objects
+
+from catalyst_rl.rl.core import EnvironmentSpec
+from catalyst_rl.rl.utils import extend_space
+
+
+class CoppeliaSimEnvWrapper(EnvironmentSpec):
+ def __init__(self, visualize=True,
+ mode="train",
+ **params):
+ super().__init__(visualize=visualize, mode=mode)
+
+ # Scene selection
+ scene_file_path = os.path.join(os.getcwd(), 'simulation/UR5.ttt')
+
+ # Simulator launch
+ self.env = PyRep()
+ self.env.launch(scene_file_path, headless=False)
+ self.env.start()
+ self.env.step()
+
+ # Task related initialisations in Simulator
+ self.vision_sensor = objects.vision_sensor.VisionSensor("Vision_sensor")
+ self.gripper = objects.dummy.Dummy("UR5_target")
+ self.gripper_zero_pose = self.gripper.get_pose()
+ self.goal = objects.dummy.Dummy("goal_target")
+ self.goal_STL = objects.shape.Shape("goal")
+ self.goal_STL_zero_pose = self.goal_STL.get_pose()
+ self.grasped_STL = objects.shape.Shape("Peg")
+ self.stacking_area = objects.shape.Shape("Plane")
+ self.vision_sensor = objects.vision_sensor.VisionSensor("Vision_sensor")
+
+ self.step_counter = 0
+ self.max_step_count = 100
+ self.target_pose = None
+ self.initial_distance = None
+ self.image_width, self.image_height = 320, 240
+ self.vision_sensor.set_resolution((self.image_width, self.image_height))
+ self._history_len = 1
+
+ self._observation_space = Dict(
+ {"cam_image": Box(0, 255,
+ [self.image_height, self.image_width, 1],
+ dtype=np.uint8)})
+
+ self._action_space = Box(-1, 1, (3,))
+ self._state_space = extend_space(self._observation_space, self._history_len)
+
+ @property
+ def history_len(self):
+ return self._history_len
+
+ @property
+ def observation_space(self) -> Space:
+ return self._observation_space
+
+ @property
+ def state_space(self) -> Space:
+ return self._state_space
+
+ @property
+ def action_space(self) -> Space:
+ return self._action_space
+
+ def step(self, action):
+ done = False
+ info = {}
+ prev_distance_to_goal = self.distance_to_goal()
+
+ # Make a step in simulation
+ self.apply_controls(action)
+ self.env.step()
+ self.step_counter += 1
+
+ # Reward calculations
+ success_reward = self.success_check()
+ distance_reward = (prev_distance_to_goal - self.distance_to_goal()) / self.initial_distance
+
+ reward = distance_reward + success_reward
+
+ # Check reset conditions
+ if self.step_counter > self.max_step_count:
+ done = True
+ logging.info('--------Reset: Timeout--------')
+ elif self.distance_to_goal() > 0.8:
+ done = True
+ logging.info('--------Reset: Too far from target--------')
+ elif self.collision_check():
+ done = True
+ logging.info('--------Reset: Collision--------')
+
+ return self.get_observation(), reward, done, info
+
+ def reset(self):
+ logging.info("Episode reset...")
+ self.step_counter = 0
+ self.env.stop()
+ self.env.start()
+ self.env.step()
+ self.setup_scene()
+ observation = self.get_observation()
+ return observation
+# -------------- all methods above are required for any Gym environment, everything below is env-specific --------------
+
+ def distance_to_goal(self):
+ goal_pos = self.goal.get_position()
+ tip_pos = self.gripper.get_position()
+ return np.linalg.norm(np.array(tip_pos) - np.array(goal_pos))
+
+ def setup_goal(self):
+ goal_position = self.goal_STL_zero_pose[:3]
+ # 2D goal randomization
+ self.target_pose = [goal_position[0] + (2 * np.random.rand() - 1.) * 0.1,
+ goal_position[1] + (2 * np.random.rand() - 1.) * 0.1,
+ goal_position[2]]
+ self.target_pose = np.append(self.target_pose,
+ self.goal_STL_zero_pose[3:]).tolist()
+ self.goal_STL.set_pose(self.target_pose)
+
+ # Randomizing the RGB of the goal and the plane
+ rgb_values_goal = list(np.random.rand(3,))
+ rgb_values_plane = list(np.random.rand(3,))
+ self.goal_STL.set_color(rgb_values_goal)
+ self.stacking_area.set_color(rgb_values_plane)
+
+ self.initial_distance = self.distance_to_goal()
+
+ def setup_scene(self):
+ self.setup_goal()
+ self.gripper.set_pose(self.gripper_zero_pose)
+
+ def get_observation(self):
+ cam_image = self.vision_sensor.capture_rgb()
+ gray_image = np.uint8(cv2.cvtColor(cam_image, cv2.COLOR_BGR2GRAY) * 255)
+ obs_image = np.expand_dims(gray_image, axis=2)
+ return {"cam_image": obs_image}
+
+ def collision_check(self):
+ return self.grasped_STL.check_collision(
+ self.stacking_area) or self.grasped_STL.check_collision(self.goal_STL)
+
+ def success_check(self):
+ success_reward = 0.
+ if self.distance_to_goal() < 0.01:
+ success_reward = 0.01
+ logging.info('--------Success state--------')
+ return success_reward
+
+ def apply_controls(self, action):
+ gripper_position = self.gripper.get_position()
+ # predicted action is in range (-1, 1) so we are normalizing it to physical units
+ new_position = [gripper_position[i] + (action[i] / 200.) for i in range(3)]
+ self.gripper.set_position(new_position)
+```
+For our reinforcement learning project we use [Catalyst RL](https://github.com/Scitator/catalyst-rl-framework), a distributed framework for reproducible RL research. This is just one of the elements of the marvellous [Catalyst](https://github.com/catalyst-team/catalyst) project. Catalyst is a [PyTorch ecosystem](https://pytorch.org/ecosystem/) framework for Deep Learning research and development. It focuses on reproducibility, rapid experimentation and codebase reuse. This means that the user can seamlessly run training loop with metrics, model checkpointing, advanced logging and distributed training support without the boilerplate code. We strongly encourage you to get familiar with the [Intro to Catalyst](https://medium.com/pytorch/catalyst-101-accelerated-pytorch-bd766a556d92) and incorporating the framework into your daily work!
+
+We reuse its general Catalyst RL environment (`EnvironmentSpec`) class to create our custom environment. By inheriting from the `EnvironmentSpec`, you can quickly design your own environment, be it an [Atari game](https://gym.openai.com/envs/#atari), [classic control task](https://gym.openai.com/envs/#classic_control) or [robotic simulation](https://gym.openai.com/envs/#robotics). Finally, we specify states/observations, actions and rewards using OpenAI's gym [spaces](https://gym.openai.com/docs/#spaces) type.
+
+### A brief summary of the `CoppeliaSimEnvWrapper` in `src/env.py`
+
+This class wraps around the general RL environment class to launch the CoppeliaSim with our custom scene. Additionally, in the beginning of every episode, it initialises the properties of the mating part: 2D position in the workspace (`setup_goal()` method), as well as its colour.
+
+The environment wrapper contains following methods:
+
+* `get_observation()`, capture a grayscale image as an observation.
+
+* `distance_to_goal()`, compute the distance between the target and current position. The distance is used in reward design.
+
+* `success_check()`, check whether the goal state is reached. If yes, significantly boost agent's reward.
+
+* `collision_check()`, check whether an agent collided with any object.
+
+
+Episode termination occurs when the robot gets too far from the target, collides with any object in the environment or exceeds the maximum number of time steps. Those conditions are specified at the end of `step()` method and are checked at each step taken in the environment by the agent. Once the episode terminates, the whole cycle is repeated for the next episode.
+
+### Defining the RL algorithm
+
+So far we have created an environment and specified how the agent can act (action space) and what the agent observes (observation space). But the intelligence of the robot is determined by the neural network. This "brain" of the robot is being trained using Deep Reinforcement Learning. Depending on the modality of the input (defined in `self.observation_space` property of the environment wrapper) , the architecture of agent's brain changes. It could be a multi-layer perceptron (MLP) or a convolutional neural network (CNN).
+Catalyst provides an easy way to configure an agent using a `YAML` file. Additionally, it provides implementations of state-of-the-art RL algorithms like `PPO, DDPG, TD3, SAC` etc. One could pick the type of the algorithm by changing `algorithm:` variable in `configs/config.yml`. The hyper-parameters related to training can also be configured here.
+
+In this tutorial, an off-policy, model-free RL algorithm [TD3](https://arxiv.org/pdf/1802.09477.pdf) is used.
+
+
+
+Figure 2: Architecture of the actor and critic in our TD3 algorithm.
+
+As depicted in Figure 2, the actor and critic(s) (TD3 concurrently learns two value networks) are modelled as `agent` classes in Catalyst. We customize them and configure the config file by setting `agent: UR5Actor` and `agent: UR5StateActionCritic`. The details of the neural network architecture for both actor and critic(s) can be configured by further editing the `YAML` file.
+
+The CNN network `image_net`, used to process camera images, can be created as shown below. The layers of network are defined by `channels `, `bias `, `dropout `, `normalization ` (booleans) and `activation ` functions (strings). These parameters are used by the function `get_convolution_net` in `src/network.py`.
+
+```
+image_net_params:
+ history_len: *history_len
+ channels: [16, 32, 32, 32, 16]
+ use_bias: True
+ use_groups: False
+ use_normalization: True
+ use_dropout: False
+ activation: ReLU
+```
+A MLP can be created using the block shown below. In our example, `main_net`, `action_net` are created
+in similar fashion through `get_linear_net` function.
+
+```
+features: [64, 64]
+use_bias: False
+use_normalization: False
+use_dropout: False
+activation: ReLU
+
+```
+Once the actor and critic network architectures are defined, we are ready to start the training.
+
+## Training
+ Figure 3: **Samplers** explore the environment and collect the data. **Trainer** uses the collected data to train a policy. Both the trainer and samplers are also configurable in `configs/config.yml`. The sampler starts with a random policy and after certain transitions, governed by `save_period` variable, the sampler updates its policy with the latest trainer weights. As the training progresses, the sampler keeps on gathering data collected by better policies while the trainer improves the policy until convergence. All the collected data is stored in a database. Source: [Sample Efficient Ensemble Learning with Catalyst.RL](https://arxiv.org/pdf/2003.14210.pdf).
+
+Once the parameters of trainer and sampler (in the tutorial we use a single sampler) are configured, the training process can be started by launching `scripts/run-training.sh`.
+
+This opens a tmux session, which starts sampler, trainer, database, and tensorboard to monitor the training process.
+
+**Once you clone our repository, install CoppeliaSim and PyRep, you are ready to start training**. Even though Catalyst is very much focused on reproducibility, due to asynchronous manner of training we can not guarantee the convergence of the training pipeline. If you don't see a progress of the robot after ~1h of training, you can try changing random seed, noise and action step values. In any case, we encourage you to play with the parameters and alter the code to your liking.
+
+**You can launch the pipeline by running** `scripts/run-training.sh`. The moment the training starts, the agents progress can be also monitored visually in the CoppeliaSim simulation.
+
+## Final Results
+
+Figure 4: Reward per episode, collected over around 10k episodes.
+
+Once the policy converges, you can either test it (run inference) in the simulator or directly on the real robot. This is can be done by editing `configs/config_inference.yml` and passing the path of converged policy (.pth file) to `resume:` variable. Finally, launch run `scripts/run-inference.sh`.
+
+### **Inference on a real robot**
+
+
+## About the Team
+This tutorial is based on the research done at [ARRIVAL](https://arrival.com/?gclid=CjwKCAjwnef6BRAgEiwAgv8mQby9ldRbN6itD_fEpRZ2TdgFBeKltK-EPSVPNUhvdoH2s8PnNAYMLxoC5OAQAvD_BwE) by the outstanding robotics team:
+* [Damian Bogunowicz](https://dtransposed.github.io)
+* [Fedor Chervinskii](https://www.linkedin.com/in/chervinskii/)
+* [Alexander Rybnikov](https://www.linkedin.com/in/aleksandr-rybnikov-9a264ab0/)
+* [Komal Vendidandi](https://de.linkedin.com/in/komal-vendidandi).
+
+The team is creating flexible factories of the future for the assembly of Arrival electric vehicles. One of the topics we are actively working on is transferring the knowledge obtained in the simulation to the physical robot. We encourage you to check out our recent research publication: [Sim2Real for Peg-Hole Insertion with Eye-in-Hand Camera](https://arxiv.org/pdf/2005.14401.pdf). If you have any questions about the contents of that tutorial or simply want to chat about robots, feel free to reach out to us!
+
+
+
+
+
+
+
diff --git a/_posts/2021-01-03-Prisoners-Geography.md b/_posts/2021-01-03-Prisoners-Geography.md
new file mode 100644
index 0000000000..65427a0bcd
--- /dev/null
+++ b/_posts/2021-01-03-Prisoners-Geography.md
@@ -0,0 +1,432 @@
+---
+layout: post
+title: "Notes - Prisoners of Geography (Tim Marshall)"
+author: "Damian Bogunowicz"
+categories: blog
+tags: [politics, geography]
+image: prisoners.jpeg
+
+---
+
+Over the christmas holidays I finally managed to finish one of my 2020 lockdown projects. After reading the (excellent) book by Tim Marshall, **"Prisoners of Geography"**, I discovered three important facts:
+- Tim Marshall is an **amazing** author.
+- I have been much more ignorant about the global geopolitics than I thought.
+- To build a solid and lost-lasting understanding of geopolitics I need to re-read most of the chapters, explore some topics on my own and take thorough notes.
+
+So...those are fruits of my work: **the summary of every chapter in the book**. Please note, that the summary is very subjective. There were some chapters which I almost skipped (Europe, duh!), while some regions were so fascinating, that I spent a lot of time going deep into the effects of Earth's geography on its politics and international relations.
+
+I have also created a [.pdf version for easier reading](https://github.com/dtransposed/dtransposed.github.io/blob/master/assets/geography.pdf). Enjoy!
+
+# Russia
+
+  +
+
+- > "There is nothing which they admire so much as strength, and there is nothing for which they have less respect than for military weakness." - Churchill
+
+- > ' - Are you European or are you Asian? - Neither, I am Russian.'
+
+- > "I am dreaming of a day when Russian soldiers can wash their boots in the warm waters of the Indian Ocean and switch to year-round summer uniforms" - Zhirinovsky
+
+
+
+ ## Geography
+
+- The Russian Federation consists of **21 countries**. Even though it is **twice the size of the USA**, its population is smaller than that of Nigeria or Pakistan. Nowadays, it takes about six days to cross the country.
+
+- Its agricultural growing season is short, the country struggles to adequately distribute what is grown around the **eleven time zones** which Moscow governs.
+
+- You can see Russia from America (Alaska).
+
+- 75 percent of its territory is in Asia, while only 22 percent of its population lives there.
+
+- **Siberia** is Russia's *treasure chest*, containing the majority of the mineral wealth. But it's also a harsh land with poor soil for farming and large stretches of swampland.
+
+- Much of the Russian Federation is not ethnically Russian and pays little allegiance to Moscow (e.g. states of Chechnya or Dagestan). While most of its states were historically separate countries, there are many 'Stans', which borders were deliberately drawn by Stalin as to weaken each state by ensuring it had large minorities of people from other states.
+
+- The biggest Russian dream: **to control a warm water port**, where the water does not freeze in winter and has free access to world's major trading routes.
+
+- Russia is the **world's second biggest supplier of natural gas** (Nord Stream, Yamal, Blue Stream). However, in the future, the USA can become Russia's competitor on the European market through the export of LNG (Liquefied Natural Gas).
+
+
+
+ ## History
+
+- Russia dates back to the **9th century**. Back then it was known as Kievan Rus'. Continuous mongol raids forced the Slavic ancestors to flee to Moscow. Unfortunately, the Grand Principality of Muscovy was difficult to defend - it lacked natural fortifications such as mountains, deserts or big rivers. This is why **Ivan the Terrible** has decided to use *attack as a defence* and aggressively expanded the country to make sure that it gains a solid buffer zone (the hinterland). In the 16th century, the country had access to Ural Mountains, the Caspian Sea and Arctic Circle.
+
+- **Peter the Great** and **Catherine the Great** had the ambitions to make Russia a part of the *western world*. They pushed Russia into the modern era. This is when the country further expanded and gained the territory of the Ukraine and Baltic States.
+
+- After the Second World War the Soviet Union stretched from the Pacific to Berlin, from the Arctic to the boarders of Afghanistan. It was a **superpower** only rivalled by the USA.
+
+- *Russian's Vietnam*: **The Soviet Afghan War** (1979-1989). The pro-soviet government took power through a coup in Afghanistan and pushed for an aggressive secular modernisation program and suppressed opposition. A lot of Islamist groups that opposed these measures began an armed insurgency against the government. The USSR sent its troops to support the pro-soviet government. The US and China also supported the rebels because of their geopolitical concerns about Soviet influence in Afghanistan. The war was bloody and costly to both sides. With the opening of the USSR's political processes and media in the early 80s, opposition to the war grew immensely. Eventually, the USSR withdrew.
+
+- Ukraine's president **Viktor Yanukovych** sparked massive protests when he turned down a deal that would have brought Ukraine closer to the EU in favour of closer ties with Russia. After he fled the country, a new, more pro-Western government was elected that promptly signed that deal. Putin's regime, seeing Ukraine as a necessary buffer and **viewing Ukraine not entering NATO and the EU as a vital national interest**, launched a covert war of aggression in the east of the country (where there are lots of Russian speakers and pro-Russian sentiment is higher) and engineered the annexation of Crimea. Similar modus operandi in Georgia and Moldova.
+
+
+
+# China
+
+  +
+
+- > China is a civilisation pretending to be a nation. - Lucian Pye.
+
+- **The Han people** make up 90 percent of the Chinese population and they dominate Chinese business and politics. **Mandarin** Chinese, which originated in the North, is the dominant language in the media and politics.
+
+- Chinese thought prizes **the collective above the individual**.
+
+- The West frowns upon the Communist Party's resistance to democracy and individual rights. If the population were to be given a free vote, the unity of the Han might begin to crack or, more likely, the countryside and urban areas would come into conflict. That in turn would embolden the people of the buffer zones, further weakening China. The deal is: **we make you better off, you follow our orders**. So long as the economy keeps growing, this grand bargain may last.
+
+- Catch 22: China needs to keep industrialising as it modernises and raises standards of living, but that very process threatens the production. **If the Chinese cannot solve this problem, there will be social unrest.**
+
+- There are now around **500 mostly peaceful protests a day** across China over a variety of issues. If you introduce mass unemployment, or mass hunger, that tally will explode and we may see social unrest of the unimaginable scale.
+
+- Having spent 4000 years consolidating its land mass, **China is now building a blue water navy**. Gradually the Chinese will put more and more vessels into the seas off their coast, and into the Pacific. Each time one is launched, there will be less space for the Americans in the China seas.
+
+- Even though it was said that creating a railroad system in Tibet was impossible, the Chinese proved them wrong. Since 2006 **Lhasa, the capital of Tibet**, is connected with the rest of the China and the *Iron Roosters* bring Han people and the modern world directly to the ancient kingdom.
+
+## Geography
+
+- **North China Plain** is the birthplace of Chinese civilisation and one of the most densely populated areas in the world.
+- It is often true, that when China opens up to trade with the West, the coastland region prosper (Shanghai, Hong-Kong, Macau) but **the inland areas are neglected**.
+- In the North, China shares the boarder with Mongolia. This is where **the Gobi Desert,** a massive early warning defence line, is located.
+- The natural southern boarders with **Laos and Burma** are composed of the jungle and mountains.
+- From the West we have the **Karakoram** mountain range and two crucial regions: Tibet and Xinjiang.
+- **Xinjiang** is an important buffer territory: it boarders 8 countries, is valuable for its oil and is a home to China's nuclear weapon testing sites. But the Muslim Uyghur people rebel against the wave of Han settlers. For the past several years China has been cracking down on religious minorities.
+
+## History
+
+- The Chinese has used the ***attack as a defence*** strategy for millennia to become a country that it is now.
+- The erection of **the Great Wall of China** started in the 200 BCE during the reign of Quin dynasty. It took 2000 years to complete the project.
+- The construction of **the Grand Canal** (world's longest man-made water between Yellow River and Yangtze) started in 600BCE under the reign of Sui dynasty.
+- After the **reign of the mongols** in the 13th century (the Yuan dynasty), the empire was retrieved by the Han people- start of the Ming dynasty.
+- The **century of humiliation**, also known as the hundred years of national humiliation, is the term used in China to describe the period of intervention and subjugation of the Chinese Empire and the Republic of China by Western powers, Russia and Japan in between 1839 and 1949.
+- From 1927-1950, China fought an extended civil war. The fighters were **Mao Zedong's Communists and Chiang Kai-Shek's authoritarian party of the Republic of China**. In 1949, the Communists completely stomped Kai-Shek, forcing him to run to the island of Taiwan.
+- In **Taiwan**, Kai-Shek continued to claim to rightfully rule all of China. The US supported this idea completely until the 1970s. Still, even today Taiwan is officially known as the Republic of China and claims the mainland. China proper calls Taiwan a runaway province, and most nations don't recognise Taiwan as a country anymore (Beijing won't do business with anyone who does). Matter of fact, the only thing stopping China from "retaking its renegade province" is American protection.
+- The 1980s saw the rise of a (predominantly student) democratic movement in China, which opposed the authoritarian communist government. It reached a culmination point at the beginning of June 1989, when **protesters and the regime faced off on Tiananmen Square**. During the violent crackdown that happened on June 3/4, an unknown number of people were killed, with some estimates ranging in the thousands. The iconic picture was taken the day after the massacre. The name of the man blocking the tanks isn't known.
+- **Tibet** is now ruled by the Chinese in the similar fashion as Inner Mongolia or Xinjiang. Tibet is crucial for the Han people, because it is the *China's water tower*. The Han Chinese moved into Tibet: now they comprise the majority of people and control all the economic resources. The Tibetan people are a minority in their own country. The head of the Tibetan people, the Dalai Lama, lives in exile in India. He was driven out by the Chinese in 1959. The Chinese do not perceive Tibet through the prism of human rights, but geopolitical security.
+
+
+
+# USA
+
+  +
+
+- > God has a special providence for fools, drunkards, and the United States of America. - Otto von Bismarck
+
+- One of the early principles of the USA was to **steer clear of permanent alliances** with any portion of the foreign world. This was the case until 1941, when the Americans intervened in the WWII.
+
+## Geography
+
+- The USA can be divided into **three regions**: East Coast Plain (fertile soil, short navigable rivers), the Great Plains (Mississippi river which start in Minneapolis and flows all the way down to the Gulf of Mexico) and the East Coast (Sierra Nevada mountains).
+
+## History
+
+- > There is on the globe one single spot, the possessor of which is our natural and habitual enemy. It is New Orleans. - Thomas Jefferson
+
+ **Louisiana Purchase** was so cheap because Napoleon needed cash for his wars a lot more than he needed a big hunk of real estate in North America. The US desperately wanted to secure free passage in the Mississippi.
+
+- **The Florida Treaty** of 1819 was a treaty between the United States and Spain that ceded Florida to the USA and defined the boundary between the USA and New Spain. It settled a standing border dispute between the two countries and was considered a triumph of American diplomacy.
+
+- The **Monroe Doctrine** is a key part of US foreign policy. President **James Monroe** issued the policy in 1823. It stated that North and South America were no longer open to colonisation. It also declared that the United States would not allow European countries to interfere with independent governments in the Americas.
+
+- After the **Mexican Wa**r the boarder of the USA expanded to the bank of the Rio Grande in the South.
+
+- Under the **Homestead Act** (1862), a person who cultivated a piece of land for 5 years was entitled to its ownership.
+
+- *Seward's folly*. On March 30, 1867, Secretary of State William H. Seward agreed to **purchase Alaska from Russia for 7.2 million dollars**. The press accused him of purchasing snow, but minds were changed with the discovery of major gold deposits in 1986. Decades later huge reserves of oil were also found.
+
+- The **Marshall Plan**, also known as the European Recovery Program, was a US program providing aid to Western Europe following the devastation of World War II. It was enacted in 1948 and provided more than 15 billion dollars to help finance rebuilding efforts on the continent.
+
+- The **destroyers-for-bases deal** was an agreement between the United States and the United Kingdom on September 2, 1940, according to which 50 US Navy destroyers were transferred to the Royal Navy from the United States Navy in exchange for land rights on British possessions. This was de facto beginning of the ubiquitous presence of the American military on the territories of western countries. Even now, the final say regarding NATO's decision belong to the Washington.
+
+- **Korean War**: Japan annexed Korea in 1910, and governed it as a colony until their defeat in WWII. After WWII, the Soviet Union occupied the north of the Korean Peninsula, and the USA occupied the southern part. Shortly afterwards, they each set up puppet governments in their parts of Korea. In 1950, North Korea attacked the South in an attempt to re-unite Korea. After initial success, they were almost completely defeated by the response of the US and other UN allies. However, China intervened on the side of North Korea and helped them fight to a stalemate, and after three years of war, the border was back roughly where it was in the beginning, and a truce was signed.
+
+## The Vietnam War
+
+- After communism took over and the USSR grew into power, they still had spheres of influence over areas of Asia. The perception is that they were **spreading communism across the globe and the US was determined to stop them** from 'creating' more communist nations or bolstering current ones.
+
+- The US and the USSR were in the middle of the Cold War. They couldn't just fight and get it over with without starting a gigantic war, so **they fought the war by proxy**. Vietnam was one of the areas where the Cold War warmed up.
+
+- Vietnam was, prior to WWII, a French colony. The French lost control to Japan for a while before deciding they were going to gain control back. The French had a rather hard time beating the communists and **the US agreed to help out** because France was a friend and, "because.... communism!"
+
+- 20 years of off an on combat later the fighting between the original combatants were forgotten and it turned into US vs. Minh conflict with supporting roles from e.g. Australia.
+
+## Cuba
+
+- Cuba was initially a Spanish colony. By the 1890s, it was fighting for its **independence from Spain**. The American press bristled with stories of Spanish cruelty against the glorious Cuban freedom fighters and urged the U.S. to step in. In 1898, an American ship, **the USS Maine**, was blown up in Havana Harbor. The American press hysterically declared it to be Spanish sabotage and the U.S. Congress finally declared **war on Spain**. Spain's dying colonial empire was no match for the newly industrialised U.S. and the Spanish lost the last of their New World colonies.
+
+- Although the war had allegedly been fought for Cuban independence, Cuba came out of the war under the effective thumb of the U.S. The new U.S.-friendly Cuban government gave the Americans **pretty much whatever they wanted, including a perpetual lease on a naval base at Guantanamo Bay.**
+
+- Some sixty years later, in 1959, **Fidel Castro overthrew that U.S.-friendly Cuban government and established a communist regime** friendly to the Soviet Union. From the U.S. perspective in the midst of the Cold War, this constituted going over to the side of the enemy. Castro further angered the U.S. by nationalising resources and industries which were owned by U.S. corporations. In 1960, the U.S. responded with the embargo, which is still in effect.
+
+- Hoping to mitigate the threat of U.S. missiles in Turkey, **the Soviet Union began placing nuclear missiles in Cuba** in 1962, resulting in the Cuban missile crisis. The crisis was resolved with the removal of Soviet missiles from Cuba, a pledge from the U.S. to never invade Cuba, and a secret deal guaranteeing the removal of U.S. missiles from Turkey.
+
+- From that point on, the **U.S. and Cuba continued to be hostile**. They were on opposite sides of the Cold War, with Cuba doing all it could to support communist movements around the world while the U.S. sought to prop up anti-communist regimes. In the 1980s, this led the Reagan administration to declare Cuba to be a state-sponsor of terrorism.
+
+
+
+
+
+# Europe
+
+  +
+
+> - For those who didn't live through this themselves and who especially now in the crisis are asking what benefits Europe's unity brings, the answer despite the unprecedented European period of peace lasting more than 65 years and despite the problems and difficulties we must still overcome is: peace. - Helmut Kohl
+
+## Geography
+
+- Europe's geography has given the Europeans a significant head start. Instead of fighting for survival, the Europeans could focus on **developing technology, philosophy and arts**.
+- Europe has barely any deserts or volcanoes. **Flooding or earthquakes are extremely rare**.
+- **One of the main factors of Europe's success were its rivers**. They are long, flat and navigable, perfect for trade. European rivers usually never meet, this is why so many countries are confined within a relatively small piece of land. Rivers act as natural boundaries. This is especially true for the **Danube**, which was used as a natural fortification by the Roman Empire, Ottoman Empire and Austro-Hungarian Empire. European coastline is also very useful - one can find a lot of natural harbours there.
+
+- **Northern Europe** is usually perceived as richer than the south. This can be attributed to the fact, that:
+ - Northern countries are **clustered tightly together**. If a Spaniard or Portuguese wished to trade with the North, they had to cross the Pyrenees.
+ - **Protestants**, with their work ethics, propelled northern countries towards prosperity. This does not apply to catholic Bavaria, obviously.
+ - The South has fewer coastal plains for agriculture. Southern countries more often **suffered from droughts and natural disasters.**
+
+## History
+
+- In contrast to e.g. the USA, Europe **grew organically over millennia** and remains divided between its geographical and linguistic regions.
+
+
+
+
+
+# Africa
+
+  +
+
+
+> - History might have turned out differently if African armies, fed by barnyard-giraffe meat and backed by waves of cavalry mounted on huge rhinos, had swept into Europe to overrun its mutton-fed soldiers mounted on puny horses. - Jared Diamond
+
+> - Sometimes you will hear leaders say: I’m the only person who can hold this nation together. If that’s true then that leader has truly failed to build their nation. - Barack Obama
+
+## Geography
+
+- The geography of the Africa is **partially "responsible" for its status as one of the least developed continents**. The history shows that the innovation used to spread from the east to the west (or other way round), but not from the north to the south. Because the continent is in large enclosed by the Sahara desert, the Atlantic and Indian Ocean, **technological revolutions and new ideas could not reach Africa for thousands of years.**
+- Africa is **much bigger compared to how it's depicted on the Mercator world map**. The Mercator projection inflates the size of objects away from the equator, so it is quite difficult to acknowledge how huge, in reality, Africa is (3x bigger than the USA).
+- Vertically, Africa is divided into **four regions**: Sahara, Sahel, jungle area and the "mediterranean-like" south.
+- **African coastline is smooth**, which means that the natural harbours of Africa are not very useful for sea trade.
+- Africa undoubtedly has some **magnificent, great rivers** - the Niger, the Kongo, the Zambezi or the Nile. Sadly, they are almost useless when it comes to trade. The great rivers do not connect, are hardly navigable and full of waterfalls.
+- Because of its climate, Africa is the home to a **vast, virulent diseases** such as malaria, yellow fever or HIV.
+- Africa is both **blessed and coursed by the abundance of natural resources**. Even though the continent is richly endowed, it is mostly the outsiders who benefit from plundering them.
+
+## History
+
+- Despite occasional trade between Arabs/Europeans and the Africans, the former **mostly kept the technology to themselves and took away whatever they found**, mainly natural resources and slaves.
+- Another reason why **no advanced trading networks were built across communities are local languages**. More than thousands of languages exists in Africa, but (before colonialism) there was no force, which could dominate a significant part of the continent. There was no "lingua franca".
+- There are 56 countries in Africa. The Africans can be thought of as **true prisoners of geography**: imprisoned by the natural barriers and well as the colonisers, who divided the continent to their liking. The Africans had internal conflicts (e.g. Zulus vs Xhosas), but the Europeans are the primary cause of the modern wars.
+- There are **Chinese businessmen** everywhere in Africa. The third of China's import comes from Africa. China builds rail connection from Mombasa to the Nairobi. Because the Chinese **don't ask difficult questions about human rights or demand economic reform**, they are a very good trade partner for many African leaders.
+- **It's great to see that the state of the continent is improving**. The poverty has fallen, while healthcare and education levels have risen. Many African countries are English speaking, which is an advantage in the global economy. However, Africa is still very much **dependent on global prices for minerals and energy**. Manufacturing output levels remain close to where they were in the 1970s. The continent is not free from corruption or numerous hot (or merely frozen) conflicts.
+
+## Democratic Republic Of Kongo
+
+- One of the biggest failures of colonialism was the creation of the **Democratic Republic of Kongo** (DRC). In practice, it is neither democratic nor it is a republic. The **second largest country in Africa** (75 million people), bigger than Spain, France and Germany combined. It is the home of the second biggest **tropical rainforest**. Inhabited by about 200 ethnic groups.
+- **The official language is French**. This is the legacy of the country being a Belgian colony from 1960 to 1966. Under the rule of the King Leopold (hence the name Léopoldville), the country, rich in natural resources, has been exploited by the colonialists.
+- **Civil Wars**: Kinshasa backed the rebel side in Angola war. Thus, it has gotten closer to the USA, which was also supporting rebel movement against soviet-backed Angolan government. Each side poured millions of dollars' worth of arms.
+- When Cold War ended nobody cared about Zaire (Congo). The country has but one great feature, the abundance of natural resources: cobalt, copper, diamonds, gold, silver, zinc, coal and manganese. **China buys approximately 50 percent of DRC's export, but the country does not get richer**. It has a development index 186 out of 187. Note, 18 countries in Africa are in the bottom of this list. Everybody wants the piece of DRC and it has no power to bite back.
+
+
+## African World War
+
+- The 1994 **Rwandan genocide** was the spark that lit the regional fire. In the Rwandan genocide, Hutu-power groups (called the *Interahamwe*) led mass killings of Tutsis and pro-peace Hutus, murdering 800,000 people in approximately 100 days. In response, the Tutsi-led Rwandan Patriotic Front overthrew the Rwandan Hutu government. During and after the genocide, an estimated 2 million refugees, mostly Hutu, poured over Rwanda’s western border into the Congo.
+- The refugee camps in eastern Congo served **as de facto army bases for the exiled Interhamwe and Army for the Liberation of Rwanda**. They terrorised and robbed the local population until October 1996, when **Tutsi led an uprising to force the Rwandans out of the Congo, sparking the First Congo War**.
+- In response, Rwandan and Ugandan (backed by Burundi and Eritrea) armies invaded the Congo. The combined effort was called the **Alliance of Democratic Forces for the Liberation of Congo-Zaire**. By December, they controlled eastern Congo, and in May 1997 they marched into Kinshasa and overthrew Mobutu’s government.
+- However, the government forces **did not give up** and - with the involvement of Angola, Namibia and Zimbabwe - continued the fight.
+
+- **More than twenty fractions were involved in the war**. Conflict in numbers: tens of thousands deaths due to the conflict, six million deaths due to disease and malnutrition. About 50 percent of victims were children under the age of five. Many ongoing conflicts in Africa are the echoes of the African World War.
+
+## Egypt
+
+- The Suez Canal controls **2.5 percent of the world's oil and 8 percent of entire trade**. Closing the canal would add several days of transit time to the overseas deliveries.
+- The African rivers are in general not good for trade, but good for **hydroelectricity**.
+- **River Nile affects 10 countries**. However, as Herodotus said: **Egypt is the Nile and the Nile is Egypt**. The majority of Egyptians live within a few miles of the Nile. Measured by the area in which people dwell, Egypt is one of the most densely populated countries in the world.
+
+- Despite the long history of conflicts with the Israel, the likely quarrel right now is with Ethiopia - **the issue over the Nile**. Ethiopia is Africa's water tower. Due to its geography, it can collect big amounts of water from the Nile - over twenty dams built. Recently, Ethiopia has built The Grand Ethiopian Renaissance Dam. Now it needs to be filled with water.
+- As a result, **Egypt is worried about the reduced river flow in its part of the Nile**. It demands the guarantees from Ethiopia that water the flow will never be stopped.
+
+## Nigeria
+
+- **Subsaharan Africa's largest producer of oil**. While the south benefits from high quality oil, the north complains that profits are not shared suitable across all the regions.
+- Nigeria is the most **important economy** in the Africa.
+- The branch of Islamic State, **Boko Haram**, is operating in the north of Nigeria. They form alliances with the jihadists up north in the Sahel region. They are known for terrorist activities which damage Nigeria's reputation abroad as a place to do business.
+
+## Angola
+
+- **Subsaharan Africa's second-largest oil producer**. Former Portuguese colony.
+- After gaining the independence, Angola was devastated by the **civil war from 1975 to 2002**. Cuba and the Soviet Block supported the socialists. South Africa and the USA supported the insurgent anti-communist.
+
+## RSA
+
+- **The Republic of South Africa** is the second biggest play on the continent in terms of economy.
+- It has access to two oceans, natural wealth (gold, silver and coal). It has very moderate climate and fertile land that allows for large scale food production. It is also not threatened by typical African diseases like malaria.
+- **Cape of Good Hope** allows for the control of the sea lanes between the Atlantic and Indian oceans.
+
+
+
+
+
+# Middle East
+
+  +
+
+
+## Geography
+
+- **Greater Middle East** stretches from Mediterranean Sea to mountains of Iran. From the Black Sea to the Arabian Sea of Oman.
+- It is **a fertile region** (Mesopotamia with Tiger and Euphrates rivers), also rich in oil and gas.
+- **Rub al-Khali**, vast desert region in the southern Arabian Peninsula, constituting the largest portion of the Arabian Desert.
+
+## History
+
+- **Ottoman Empire, which ruled those lands never tried too hard to divide local people into artificial countries**. Only after the fall of the Ottoman Empire, the British and French started to divide the land and create countries such as Syria, Lebanon, Iraq or Palestine (**Sykes-Picot agreement)**.
+- **Sunni Islam** (85 percent of all followers): orthodox, believed that the successor of the prophet ought to be chosen using Arab tribal traditions.
+- **Shia Islam** (15 percent of all followers): believed that the caliph is to be divinely appointed, and that blood was the main factor of succession.
+- **Middle East is a set of nation states ruled by leaders, who tend to favour whichever branch of islam they themselves come from.**
+- In **Iraq**, Shias never accepted never accepted sunni lead government controls holy cities of Najaf and Karbala (where martyrs Ali and Hussain are buried).
+- **Kurdistan** is a fairly large area which exists in Turkey, Syria, Iraq, and Iran. Kurds have their own culture and language, but unfortunately political boarders have split them all up, and they are subject to the laws of all these different nations. They have no proper nation of their own, even though they have historically lived in their own region and some have been granted regional autonomy.
+- Before the 2003 invasion of Iraq by the US, **Saddam Hussein** and his regime did terrible things to the Kurds. This includes bombing at least one village with mustard gas. Because of this, as well as underlying discrimination, the Kurdish people have been seeking their own nation. It's been proposed that Kurdistan be carved out of the northern section of Iraq.
+- **The demise of Saddam Hussein** started due to Iraq's occupation of Kuwait (first USA-Iraq war). After that Iraq was targeted with sanctions of many different kinds. As trade was not too easy, Saddam Hussein started eventually to sell energy with other currencies then the US Dollar. Right then, at the same moment, USA "noticed" that Iraq has "problems with not-too-democratic government and lack of civil liberties". The second USA-Iraq war started.
+- **Gaza and West Bank** were created in the aftermath of the 1948 war. "Gaza" is the part of Palestine that the Egyptian army captured. The "West Bank" is the part of Palestine that the Jordanian army captured. "Israel" is the part of Palestine that the Jewish militias captured. From 1948-1967, the Jews developed a state on the land they captured. Jordan tried to integrate the West Bank into its own state. Egypt tried to make Gaza a vassal state of Egypt. Noone recognised a "Palestinian state" because nobody claimed a Palestinian ethnicity. Fast forward to 1967 when Egypt was bombing Israeli ships. There were UN peacekeepers between Egypt and Israel but Nasser (king of Egypt) told the UN to leave the border. Syria and Lebanon attacked Israel by way of artillery. Egypt, Syria, Lebanon, and Jordan collected their armies on the border of Israel. So Israel decided that waiting to be attacked was silly. They attacked the armies of invasion that were collected on their unrecognized borders. War broke out. Israeli armies advanced into Gaza and the West Bank. Cease-fire agreements were signed while the Israeli army was still in this area (that Jordan and Egypt called their own, without any reference to the yet-unborn Palestinians).
+- **Lebanon** is a tiny country in the middle east. It's bordered by Syria from the north and east, Israel from the south, and the Mediterranean Sea from the west. Syria has been in a deadly civil war since 2012. Lebanon and Israel are officially "at war" since the inception of Israel, though currently there isn't any war going on, and the last real war between the two countries happened in 2006 and lasted only 30 days.
+- **The Arab Spring** was the uprising of peoples in middle eastern countries against their governments (usually religious governments). Once it began, different ideas and ideals carried through the Arab world and other countries followed suit in hopes of each creating new governments. Some have been successful, others not so much.
+
+
+
+
+
+# India and Pakistan
+
+  +
+
+
+- > Pakistan has decided to bleed India with thousand cuts. It's the policy of Pakistan. The creation of Bangladesh, which happened with the help of India, was a very humiliating defeat for them, and they feel that this is one way of avenging that defeat. They are avenging this defeat by causing casualties to our security forces and creating mayhem amongst the people. - General Bipin Rawat
+
+- Pakistan stands for *pure land*. **It is one state, but not one nation.**
+
+- The official language of Pakistan is **Urdu**, the mother tongue of all the people who fled India in 1947.
+
+## Geography
+
+- The problem of Bangladesh is not that has little access to the sea, but **the sea has too much access to Bangladesh** (devastating floods).
+- The Kashmir issue is partially one of national pride, but it is also strategic. Full control of Kashmir would give India **a window into Central Asia and a boarder with Afghanistan**. It would also deny Pakistan a boarder with China and thus diminish the usefulness of a Chinese-Pakistani relationship.,
+
+## History
+
+- When India was partitioned between Hindu and Muslim areas, there existed quite a few nominally independent areas called the Princely States, who were in theory given the choice of remaining independent or joining India or Pakistan. In practice varying degrees of coercion were employed to make them join one of the countries, up to and including an armed invasion by India in the case of Hyderabad. **The Kashmir had a Muslim majority so Pakistan felt it should be part of it, but Kashmir's ruler joined India**. Pakistan invaded and started the first of several wars.
+
+- Pakistan is, in all aspects, **weaker than India**. The country received just 17 percent of national reserves of original India after end of the colonial times.
+
+- For a lot of the western and northern parts of China, it would be a shorter distance to ship products from ports in Pakistan. This is why the Chinese spent around $40 billion on a **China Pakistan Economic Corridor**, a road which goes from the border to Gwadar and then on the port itself. The corridor allows China to bypass the problematic Strait of Malacca.
+- Gwadar could have been the reason, why USSR invaded Afghanistan - **to gain access to the warm-water port**.
+
+- Islam, cricket, the intelligence services, the military and the fear of India are what holds Pakistan together. **Is has been in a state of civil war for more than a decade.**
+- Situated at over 20,000 feet, the **Siachen Glacier** is the highest battleground (1984) on Earth, with both countries (India and Pakistan) maintaining a permanent military presence in the region.
+
+
+
+# South America
+
+  +
+
+## Geography
+
+- South America is a living proof, that **if the geography is against you, then you are bound to have limited economic success**. The continent has just few deep, natural harbours.
+
+## History
+
+- It is believed that the first human populations of South America **either arrived from Asia into North America via the Bering Land Bridge**, and migrated southwards or alternatively from Polynesia across the Pacific.
+- The USA developed very quickly due to the fact, that small landholders used to own the land. However, in the South America, there were **powerful landowners and serfs - this is led to significant inequality**. Also, the first European settlers stayed near the coast. They built roads to connect the interior with the coastal capitals, but **neglected the connection between the towns in the heart of the continent**. This resulted in the majority of wealth being transferred from each region to the coast.
+- **The Treaty of Tordesillas** (1494) neatly divided the *New World* of the Americas between the two superpowers - Spain and Portugal. The countries adhered to the treaty without major conflict between the two. This why Spanish language is being spoken in South America (with exception of Brazil and French Guiana).
+- The two leading figures of the South American wars of independence were **Simon Bolivar in the North and José de San Martín in the South**. Their paths met in Ecuador, where the modest and unselfish San Martín came off second best. While he is honoured in Argentina as a national hero, in South America Bolivar is revered almost as a god. Bolivarianism is a mix of pan-American, socialist and national-patriotic ideals fixed against injustices of imperialism, inequality and corruption.
+- **South America was a proxy battlefield of the Cold War**. This environment has allowed dictatorships to flourish. The continent experienced economic instability mixed with a loss of faith in democratic institutions. The military was more efficient than a legislature. One thing unique to Latin American states was the heavy involvement of foreign governments, especially the United States, in their internal affairs.
+- **China has been investing heavily in South America**, especially in Argentina, Venezuela and Ecuador. It has replaced USA as Brazil's main trading partner. In return, China hopes for the support in the UN for its national claims back home (e.g. regarding Taiwan). It has been confirmed that Beijing is the major weapon supplier to South American countries.
+- The basic idea of the **Monroe Doctrine** is that the United States has historically had a special relationship with countries in our hemisphere, and an obligation to intervene if those countries were threatened by European expansion or colonialism.
+- Even though France, the Netherlands, and the UK still have nominal colonies in the hemisphere, the US is not going to intervene in these territories, nor will they ever under any foreseeable circumstances. This is why the US did not take a real side in the Falkland island war. The islands were invaded by Argentina, an act of aggression which they can't condone but can't side with the UK as it would be completely **contrary to the Monroe doctrine if the US sided with a European power against a Latin American Country**.
+
+## Bolivia
+
+- After loosing in the War of the Pacific (over guano and saltpeter discovered in the Atacama Desert) in 1904, **Bolivia became landlocked**. Up to this day the relationships between Chile and Bolivia remain hostile.
+- **Chile is in dire need of a stable gas supply and Bolivia possesses vast gas reserves**. However, it is very unpopular in Chile to speak about buying natural resources from the old enemy. Even though some Bolivian leaders (e.g. Evo Morales) have been proposing to strike a deal, the pride of the Chileans does not let them buy gas from the Bolivians.
+
+## Panama
+
+- Panama is famous for the **Panama Canal** (1914), which connects the Atlantic Ocean with the Pacific Ocean.
+- Even though there were plans to build a **second canal in Nicaragua**, the investment seems to have failed. Initial agreement between the president Daniel Ortega and Chinese billionaire Wang Jing stalled. There are rumours of insufficient financing and overall abandonment of the project.
+- Because of very good relationships with the USA, some can accuse the country of being an ***American lackey***.
+
+## Brazil
+
+- Brazil can be seen as the most **powerful country on the continent**. It is almost as big as the USA.
+- The future of the **Amazon rainforest** seems bleak. It falls victim to slash-and-burn agriculture, a method of growing food in which farmers and cattle ranchers deliberately cut down and burn forestland to clear it for crops and livestock. However, once the rainforest is cut it will not grow back.
+- Even though the **Amazon is huge and navigable**, its coast is muddy and it's difficult to build on it.
+- Brazil's seven larges ports move **fewer goods** than a single port in New Orleans.
+- 25 percent of Brazilians live in **favela slums**.
+- To develop the interior of the country, **the capital of Brazil has been moved from Rio de Janeiro to Brasilia**.
+
+## Argentina
+
+- **Runner-up in the competition of the most powerful country on the continent**.
+- It can boast with a quality of land **comparable to the European countries**. It actually used to be richer than France or Italy in the past, but lost its wealth due to mismanagement.
+- **Vaca Muerta** is a geologic formation located in northern Patagonia. It is well known as the host rock for major deposits of shale oil and shale gas. Argentina requires massive investment to make use of those deposits. But out of national pride it will refuse to strike a deal with any company which has previously taken advantage of the gas fields around the Islas Malvinas...
+- ... a.k.a the Falkland Islands. This oversea territory by Argentina is currently owned by the UK. Argentina claims ownership of the Falklands. The control of the islands was the cause of the **Falkland War in 1982**. Had Argentina waited a few more years, the British Navy would likely have been unable to react to the invasion of the Falklands since the last remaining aircraft carrier of the UK was set to be retired that very year. In a 2013 referendum, 99.8% of the population voted in favour of remaining with the United Kingdom, with three dissenting votes in total. The territorial dispute with Argentina is ongoing, and it became more relevant since the discovery of gas fields near the islands.
+
+
+
+# The Arctic
+
+  +
+
+> - Offshore fields especially in the Arctic, are without any exaggeration, our strategic reserve for the twenty-first century. - Vladimir Putin
+
+> - They have cities in arctics, we only have villages. - Melissa Bert
+
+- Polar region located at the northernmost part of Earth. The Arctic consists of the Arctic Ocean, adjacent seas, and parts of Alaska (United States), Finland, Greenland (Denmark), Iceland, Canada, Norway, Russia, and Sweden. Its name comes from Greek word **arktikos - near the Bear** (reference to Ursa Major). The first known explorer of the Arctic was Pytheas of Massalia (he called it Thule).
+- After Pytheas, there were other prominent explorers fascinated by the Arctic. **Roald Amudsen** has sailed in 1918 from Norway, through the Arctic Sea and Bering Strait to California. In 1926, Amundsen and 15 other men made the first crossing of the Arctic in the airship Norge. While flying over the Arctic they dropped Norwegian, Italian and American flags. **Shinji Kazama** reached the North Pole on 21 April 1987 on a motorbike.
+- It is the fact, that the **climate is changing and biological shuffle is under way**. Ice melts and recedes, animals migrate, sea levels are rising. The climate change is perpetuated by the albedo effect (when ice is replaced by water or land, the lower albedo value reflects less and absorbs more energy, resulting in a warmer Earth). Maldives, Bangladesh and Netherlands are in grave risk of flooding. However, there are also benefits of the process: many transport routes are becoming available, local populations benefit from new food sources.
+- Northwest Passage links Atlantic and Pacific Ocean and can **facilitate transport from Europe to China**. This means that the shipping companies would be less dependent on the Suez and Panama canals. In 2014 the first cargo ship, Nunavik sailed the Northwest Passage without an aid of an icebreaker.
+- As the ice slowly melts, we **are getting access to natural oil and gas reserves of the Arctic**. ExxonMobil, Shell, Rosneft are all applying for licenses to operate in this region. It would be difficult to work in this harsh environment (endless nights, frozen sea, waves forty feet high). We should be concern about the presence of the companies in the Arctic. There is a thread that they will not be concerned about potential environmental consequences and may accelerate the climate changes.
+- There are **many legal disputes over the governance of the Arctic**. However, the colonisation of the Arctic will be different from e.g. *race to conquer* Africa. This new race has rules a formula and a forum for decision making
+
+## Russia vs the USA
+
+- **Russia has the heaviest presence in the polar region**. Very eager to establish dominance in the north. Planted a rust-proof titanium Russian flag on the seabed in 2007 as a statement of their ambition.
+- There have been claim that Arctic Ocean should be renamed to **Russian Ocean** (Lomonosov Ridge argument). They are claims to Spitzbergen (Svalbard Islands). Norwegian islands are densely inhabited by Russian coal-mine workers.
+- The Russian fleet could **be easily blocked** on the Baltic Ocean (Skagerrak Strait) and GIUK region by NATO forces.
+- **Russia is building an arctic army**. 6000 combat soldiers station in the Murmansk region. There have been large-scale exercises performed with 155,000 soldiers, thousands of tanks, jets and ships. The Russians have 32 icebreakers to their disposal. 6 of them are nuclear. They consider building a floating nuclear power plant.
+- **The USA is not even close to dominate the Arctic**. The USA has one, single icebreaker.
+
+
+
+# Korea and Japan
+
+  +
+
+
+- The recent relationship between both Koreas, Japan and the USA has resembled a long-lasting Mexican stand-off. **Solving the North Korean problem may have properties of a self-fulfilling prophecy**. One on hand world leaders should intervene against the regime. However, they are aware that the collapse of North Korea will, without any doubt, cause huge chaos to every party involved.
+
+- For most of the history Korea was a *hermit country*. Confined between its seas and Yalu river, it always attempted to shield itself from the violent neighbours. **The Japanese occupation** (starting in 1910) may serve as an example. Back then, it was forbidden to speak Korean, teach Korean history or cultivate Korean traditions. To this day, those past events are a source of resentment for the Koreans.
+- After the defeat of Japan (1945), **the Americans divided Korea in two parts, along the 38 parallel**. The Soviets had been commended to halt before the boarder, and so they did. From now on the Communist regime reigned over the North Korea (first under Soviet, later the Chinese banner). South Korea remained under American supervision. The Koreans did not have any say regarding the division of their country.
+
+- Shortly after, both Americans and Soviets started loosing interest in the peninsula. This is why in 1950, North Korea (backed by communist China) decided to march south with the ambition to reunite Korea under the communist reign. However, losing South Korea was not an option for Americans. They could not afford to show any sign of weakness in the face of the Cold War. They quickly stopped the North Korean army and regained south territory. **Technically, both Koreas are still at war - the treaty was never signed.**
+
+## South Korea
+
+- **Seoul, the capital of South Korea is located just 30 miles away from the DMZ**. It is home to half of the South Korean population (50 million in total). The proximity to North Korea is why South Korea strives for relative peace. It is afraid of 100 000 artillery pieces aimed at all times directly at the city. Additionally, it is believed that North Korea can quickly move their troops into the city through secret, underground tunnels. Finally, about 100 000 undercover agents (sleeper cells) are stationing in the city.
+
+## North Korea
+
+- **The least democratic state in the world**, famous for its combination of fierce nationalism, communism and fierce self-reliance. Population of about 25 million people. It is being estimated that 150 000 political prisoners are being held in the "re-education" camps on the North Korean territory. North Korean army is one of the biggest in the world. Its economy is 80 times weaker than South Korean's.
+
+- Even if the North agreed to *surrender* and join South Korea, it would be extremely difficult to merge the advanced, rich South with the poor, underdeveloped North.
+
+## China
+
+- **China's goal is to keep North Korea stable for two reasons**. Firstly, it does not want to become a home to millions of refugees fleeing from the Korean regime. Secondly, China is North Korea's only trade partner.
+
+## Japan
+
+- Japan has been always **conveniently separated from the outside world**. However, its geography is at the same time problematic. Japan is a mountainous country, where it is difficult to farm or establish river trade. It has also very little natural resources. This is why it remains one of the biggest importers of oil and natural gas.
+
+- The **hunger for natural resources** was one of the reasons for Japan to participate in the second world war. Even though the USA has threatened Japan to halt their oil supplies, Nippon answered with Pearl Harbor attack and further conquests in the South-East Asia. Due to the mountainous terrain, the Americans were unable to invade the Japanese islands. This is why they resorted to nuclear bombings of Hiroshima and Nagasaki.
+
+- Nowadays, **Americans are allowing Japan to rebuild their army**. Both countries regard are ready to compromise in the face of the looming, Chinese dominance.
diff --git a/_posts/2021-04-05-Mixed-Martial-Maths.md b/_posts/2021-04-05-Mixed-Martial-Maths.md
new file mode 100644
index 0000000000..5ee67da1e1
--- /dev/null
+++ b/_posts/2021-04-05-Mixed-Martial-Maths.md
@@ -0,0 +1,699 @@
+---
+layout: post
+title: "Mixed Martial Maths - Simple Reasoning Tools For Complex Phenomena"
+author: "Damian Bogunowicz"
+categories: blog
+tags: [mathematics, reasoning, engineering,approximation]
+image: mmm.jpg
+
+---
+Recently I have been interested in obtaining a very particular skill. I have seen this ability demonstrated by many excellent individuals - not in only in the tech world, but also in finance or consulting industry.
+
+I am talking here about the art of back-of-the-napkin (or back-of-the-envelope) calculation, also known as guesstimation or order-of-magnitude analysis.
+
+In your professional and private life you may be often presented with difficult question, where the insight is much more important than the precision of the final answer. For example:
+
+> How many weddings are performed each day in Japan?
+
+or
+
+> How many total miles do Americans drive in a year?
+
+The challenge lies in the complexity of the problem, not in the quality of the obtained result. Giving the exact answer to any of those riddles is the least important thing. The crucial issue is: how to even begin answering the question?
+
+Those challenges, at least in the context of engineering or physics, are called [Fermi problems](https://en.wikipedia.org/wiki/Fermi_problem). Surprisingly, there are many professions where one may grapple with those type of questions on the daily basis:
+
+- consultants, who are often asked to estimate the size of something with no, or little, data available.
+- software engineers, who need to approximate the task complexity to efficiently plan new development of features and release timelines.
+- economists, who often use incomplete information to create economic forecasts.
+- scientists, who look for estimates for the problem before turning to more sophisticated methods calculate a precise answer.
+- engineers, who use low-cost thought experiments to test ideas before committing to them.
+
+Science and engineering, our modern ways of understanding and altering the world, are said to be about accuracy and precision. But accuracy and precision are what modern computers are for. Humans are indispensable when it comes to insight.
+
+Even though we improve our insight through experience and knowledge, the complexity is what makes our "mental registers overflow" and wash away all the understanding. The goal of this article is to present several reasoning tools, which will allow you to harness the complexity of the modern world and make you less wrong on the daily basis.
+
+## Motivation and Further Reading
+
+Over the past year I was actively trying to improve my general problem solving ability, as well as train my brain to reason from first principles. I went through some impressive blog posts (you can never go wrong with [waitbutwhy](https://waitbutwhy.com/2015/11/the-cook-and-the-chef-musks-secret-sauce.html)), YouTube videos (you can never go wrong with [Grant Sanderson](https://www.youtube.com/watch?v=QvuQH4_05LI&t=485s)) and many helpful reddit threads. One of them mentioned [Sanjoy Mahajan](http://web.mit.edu/sanjoy/www/), an excellent MIT professor, who has been educating his students on the art of approximation for more than a decade. I have thoroughly studied his fascinating book: "The Art of Insight in Science and Engineering: Mastering Complexity". Only recently I have discovered that his lectures are also [available online](http://web.mit.edu/6.055/). Long story short, I found the material fascinating and created a substantial amounts of messy study notes. I have decided to structure them in the form of list - a list of nine simple reasoning tools for harnessing complexity. I hope that the toolbox will also be useful for you my dear reader.
+
+### Tool # 1 Divide and Conquer
+
+Let's get familiar with the first reasoning tool. Whenever you are required to estimate some complex value, do not let the task formulation overwhelm you. Break hard problems into manageable pieces - **divide and conquer**!
+
+#### Counting to a Billion
+
+I will be mentioning **divide-and-conquer** reasoning in conjunction with other reasoning tools throughout this blog post. This is why I am just briefly introducing a simple problem to illustrate the point. Let's answer the following question:
+
+> How long would it take to count to a billion?
+
+The purpose of divide-and-conquer is to be break the problem into smaller, digestible pieces and then combine them into a full solution.
+
+First let's think about how long it takes to say a number out-loud. For relatively small numbers it takes me about $$0.5$$ second, while I need up to $$5$$ seconds to say: $$999,999,999$$. We can use the best- and worse-case scenario to compute an "average" time necessary to say a number.
+
+To combine quantities produced by our "mental hardware" (especially lower and upper bounds), we shall use geometric mean, rather than arithmetic mean. This is because geometric mean operates on a logarithmic scale and this is compatible with how humans perceive quantities - through ratios.
+
+$$
+t_{mean} = \sqrt{t_{max} \cdot t_{min}}=\sqrt{5 \cdot 0.5} \approx 1.6s
+$$
+
+An average time to say a number out-loud is about $$1.6$$ second. Now, we can complete the assignment by calculating how much time it takes to say a number out-loud billion times!
+
+$$
+t_{tot} = t_{mean} \cdot 10^9 = 1.6s\cdot 10^9
+$$
+
+This is equivalent to about $$51$$ years, quite some time!
+
+We broke one, seemingly overwhelming problem into two, fairly easy ones. While the complexity of the example was pretty modest, the usefulness of **divide-and-conquer** reasoning will be demonstrated later on in this write-up.
+
+**Conclusion: No problem is too difficult! Use divide-and-conquer reasoning to dissolve difficult problems into smaller pieces.**
+
+### Tool # 2 Harness the Complexity Using Abstractions
+
+**Divide-and-conquer** reasoning is very useful, but not powerful enough on its own to deal with the complexity of the world.
+
+#### And All That Jazz
+
+Imagine that you just bought a huge collection of vinyl records. You are a very tidy person and want to organise your records in some orderly way. Surely, you do not want to spend hours looking for this one record every time you feel like playing something particular. Perhaps you could use **divide-and-conquer** to divide your newly acquired collection into groups, e.g. segregate the records by release date. However, it could be much more convenient to build some kind of structure or hierarchy for our collection. In our example, this could be grouping the records into genres. As the next step, we could expand this hierarchy and build tree-like representation of our collection by grouping jazz records into sub-genres: bebop, acid jazz, jazz rap.
+
+Creating an adequate representation (abstraction) of the vinyl collection allows us to browse the complex structure quick and seamlessly.
+
+#### When in Rome, Do Not Do As the Romans.
+
+Have you ever noticed how ridiculously impractical, in the context of modern mathematics, Roman numerals are? It seems pointless to use them for any kind of useful algebra. XXVII times XXXVI is equivalent to $$27 \cdot 36$$. However, because of the level of abstraction inadequate for this operation, it feels so unnatural to perform multiplication in this notation. The modern number system, based on the abstractions of value and zero, makes the operation surprisingly simple. Even if you cannot do mental multiplication fast, you could use its properties to compute:
+
+$$
+27 \cdot 36 = (20+7) \cdot (30+6) = 20\cdot 30 + 7\cdot 30 + 20\cdot 6 + 7\cdot6 =
+$$
+
+$$
+=600+210+120+42=810+162=972
+$$
+
+But why did the Romans do, seemingly, such a poor job? You can find the answer [here](https://www.encyclopedia.com/science/encyclopedias-almanacs-transcripts-and-maps/roman-numerals-their-origins-impact-and-limitations). The Romans were not concerned with pure mathematics, which usually requires high degree of abstraction. Instead they used mathematics to figure personal and government accounts, keep military records, and aid in the construction of aqueducts and buildings.
+
+**Conclusion: Good abstractions amplify our intelligence and bad abstractions make us confused. An example of good abstraction: “Could you slide the chair toward the table?". An example of bad abstraction: “Could you, without tipping it over, move the wooden board glued to four thick sticks toward the large white plastic circle?”.**
+
+### Tool # 3 Find What Remains Unchanged
+
+**Divide-and-conquer** and **abstractions** help us to combat complexity by introducing order and structure. The upcoming tools help us to find some useful properties of the problem. Once the property is found, we are allowed to discard some portion of the complexity without any repercussions.
+
+It is particularly beneficial to discover an existence of some **invariants** in the problem. **Invariants** mean that there exists some form of **conservation** or **symmetry** in the system. Hence, some part of complexity is a mirror copy of the remaining complexity and can be safely discarded.
+
+#### A Rat-Eaten Chessboard
+
+  +
+
+
+Imagine a basement, where you keep your old chess set. A rat comes out and gnaws on your antique chessboard. As a result, the animal chews off two diagonally opposite corners out your standard $$8 \times 8$$ chessboard. In the basement you also keep a box of rectangular $$2 \times 1$$ dominoes.
+
+> Can these dominoes tile the rat-eaten chessboard i.e. can we lay down the dominoes on the chessboard, so that every square is covered exactly once?
+
+What we could try to do is to start placing dominoes naively, hoping that we spot some patterns or just stumble upon the solution. Most likely we would get overwhelmed by the number of possible move sequences. Instead of using brute force, let us identify some quantity, which remains unchanged, no matter how many dominoes pieces are on the board. In general, this quality is the **invariant**.
+
+Since each domino covers exactly one white and one black square on the chessboard, the following relationship $$x$$ between uncovered black squares and uncovered white squares remains unchanged. This is true, not matter how many dominoes are laying on the chessboard at any given time.
+
+$$
+x = \text{uncovered}_{\text{white}} - \text{uncovered}_{\text{black}}
+$$
+
+A regular $$8 \times 8$$ chessboard initially has $$32$$ black squares and $$32$$ white squares. Our perturbed chessboard is missing $$2$$ black squares. This means that:
+
+$$
+x_{initial} = 32-30=2
+$$
+
+Now, we succeed if there are no empty squares on the nibbled chessboard (and no overlapping dominoes). This means finishing the game with no uncovered white or black squares:
+
+$$
+x_{final} = 0-0 = 0
+$$
+
+Because $$x_{final} \neq x_{initial}$$ ($$x$$ is always equal to $$2$$ after every move until no further moves are available), we cannot tile the nibbled chessboard with dominoes. We can reach this conclusion immediately once we find a meaningful invariant.
+
+Whenever facing a complex problem, it is helpful to look for the **conserved** quantity. Finding the **invariant** allows for creation of a high-level abstraction layer of the problem. Operating on this abstraction layer can directly lead to the solution without delving into the messy complexity of the problem at hand. Often, however, the invariant is given, so we can analyse the actions that preserve it. Those actions, which take advantage of the **symmetry** of the problem and preserve it, are called **symmetry operations** .
+
+#### Carl Friedrich's Math Assignment
+
+The fans of mathematical anecdotes surely know the one about the young Carl Friedrich Gauss. As a young student he was given the following problem:
+
+> Find the sum numbers from $$1$$ to $$100$$.
+
+It took just several minutes until the prodigy child quickly returned with the answer: $$5050$$. What was the trick?
+
+Gauss found the **invariant**, the sum, which does not change when the terms are added "forward" (from the lowest number to the highest) or "backward" (from the highest number to lowest) - hence he also discovered the corresponding **symmetry operation**.
+
+$$
+S = 1+2+3+ \cdots + 99 + 98 + 100 = 100+99+98+\cdots+3+2+1
+$$
+
+Having found the symmetry of the problem, the solution is easy to compute. By adding the "forward" and backward" representation of the sum we end up with:
+
+$$
+2S = 101+101+101+\cdots+101+101+101 = 101\cdot100
+$$
+
+$$
+S=\frac{10100}{2} = 5050
+$$
+
+#### Finding vertex without the calculus
+
+  +
+
+
+Let's find the maximum of the simple function:
+
+$$
+f(x)=-x^2+2x
+$$
+
+Your instinct may tell you to use calculus to solve the problem, but why should we use a sledgehammer to crack a nut? Let's do what Gauss did with a sum of series - use the invariant and related symmetry operation to crack the puzzle efficiently.
+
+The invariant of the problem is the location of the minimum. We can safely guess that there is some symmetry available to be exploited (the equation represents a second-order polynomial, which has a parabolic shape).
+
+We can factor the function:
+
+$$
+f(x)=-x^2+2x=x(-x+2)
+$$
+
+Since multiplication is commutative ($$x(-x+2) = (-x+2)x$$) , we have found our symmetry operation: $$x \leftrightarrow -x+2$$. This operation turns $$2$$ into $$0$$ or $$3$$ into $$-1$$ (and vice-versa). The only value unchanged (left invariant) by the symmetry operation is $$1$$, the solution to our problem!
+
+Interestingly, I have also been recently reading completely unrelated book by Benoit Mandelbrot. It was interesting to stumble upon his testimony about invariants in the context of financial engineering:
+
+> Invariance makes life easier. If you can find some [market] properties that remain constant over time and place, you can build better and more useful models and maker sounder [financial] decisions - Benoit B. Mandelbrot, "The (mis)Behaviour of Markets"
+
+**Conclusion: When approaching a problem look for things which don't change - the invariant or the conserved quantity. Finding it and taking advantage of the related symmetry often simplifies a complex problem.**
+
+### Tool #4 Use Proportional Reasoning
+
+Proportional reasoning is yet another powerful weapon, which allows to avoid complexity by taking a clever mental shortcut. Instead of spending time and effort to find some unknown quantity directly, we can estimate it through some relationship with the other, well-known quantity.
+
+#### Counting McDonald's Restaurants
+
+If a person approached you on the street and asked: "how many McDonald's restaurants are there in your country?", you would be probably quite baffled. If not due to the surprising nature of the question, then certainly by the difficulty of the estimate. Most of the people I asked usually were overstating the number - some of the estimates were off by two orders of magnitude! They would surely give an accurate answer, if they knew about the proportional reasoning.
+
+My hometown in Poland has, give or take, $$400$$ thousand inhabitants. We surely had about $$5$$ McDonald's outlets back when I was attending middle high. Poland has population of $$40,000,000$$. By applying simple proportional reasoning I can estimate that there are...
+
+$$
+\text{restaurants}_\text{poland} = \text{restaurants}_\text{hometown}\cdot \frac{\text{population}_\text{poland}}{\text{population}_\text{hometown}} = 5 \cdot \frac{4 \cdot 10^7}{4 \cdot 10^5} = 500
+$$
+
+ ...McDonald's restaurants in Poland. The actual number is $$462$$ (data from $$2019$$ according to [wikipedia](https://en.wikipedia.org/wiki/List_of_countries_with_McDonald%27s_restaurants)). Pretty neat huh?
+
+#### To Fly or Not to Fly
+
+Proportional reasoning can be effective, even when facing a seemingly daunting problem:
+
+> Which mean of transport is more fuel-efficient: a plane or a car?
+
+A physicist or an economist could answer this question by applying full-fledged analysis, but there is no need to do so. The only required piece of domain knowledge is the high-school physics knowledge.
+
+For cars travelling at highway speeds, most of the energy is consumed by fighting drag (air resistance). Planes on the other hand, not only need the energy to fight drag, but also to generate lift.
+
+At a plane's cruising speed, lift and drag are comparable. Lift plus drag is twice the lift alone. Neglecting lift ignores only a factor of two, which is fine for our approximation. As a result, we end up with two drag energies, one for a car and one for a plane.
+
+To investigate, which mean of transport is more fuel-efficient, we can compute the ratio of drag energies for both vehicles. In general, drag energy of a body depends on its cross-sectional area, velocity and the density of the medium around that body:
+
+$$
+\frac{E_{plane}}{E_{car}} = \frac{\rho_{plane}}{\rho_{car}} \cdot \frac{A_{cs, plane}}{A_{cs, car}} \cdot (\frac{v_{plane}}{v_{car}})^2
+$$
+
+Our goal is to find out the ratio on the left hand side. We can do this by estimating the terms on the right hand side.
+
+##### Air density
+
+Rather than estimating air density at the cruising altitude (plane) and at sea level (car) separately, let's think about their ratio. Planes fly high - Mount Everest high. I know that climbers have difficulty breathing on the peak of the mountain due to lower oxygen density. This means that the density of the air decreases with altitude. Compared to the sea level, I am guessing the density ratio of $$2$$ (sea level to plane's cruising altitude).
+
+##### Cross-section
+
+Once again, we shouldn't care much for each value separately. Let us directly estimate the ratio! How many car cross-sections can "fit" into a cross-section of a plane? I am pretty sure that in terms of width, plane's round fuselage cross-section (I am neglecting the wings) could be occluded by three cars parked next to each other. Probably the same thing applies in the vertical dimension. If we stacked three cars on top of each other they could "cover" the plane horizontally. This means that the cross-section ratio is about $$3 \cdot 3 = 9$$
+
+
+  +
+
+##### Velocities
+
+Here, I feel pretty comfortable with estimating each velocity separately. A car travels at around $$100$$km/h, while a plane travels at almost $$1000$$km/h. This means velocity ratio of $$10$$.
+
+Finally, we can compute the drag energy ratio:
+
+$$
+\frac{E_{plane}}{E_{car}} = \frac{1}{2} \cdot 12 \cdot (10)^2 = 450
+$$
+
+Given the common knowledge, that the fuel efficiency of a car and plane, per passenger, are roughly the same, I am pretty happy with this estimate. A car needs one "unit" of energy per person (assuming an average person drives to and from work alone). Conversely, a plane, which carries about 500 people, needs approximately one unit of energy per person as well.
+
+Notice how **divide-and-conquer**, as well reasoning from first principles, were efficiently utilised in this analysis as well!
+
+**Conclusion: Instead of spending time and effort to compute some unknown quantity directly, try to estimate it (using proportions) through some other, related, well-known quantity.**
+
+### Tool #5 Dimensional Analysis
+
+Dimensional analysis makes it possible to say a great deal about the behaviour of a physical system - e.g. it facilitates the analysis of relationships between different physical quantities or even deduction of the underlying equations.
+
+#### Dimensional Analysis "a la Huygens"
+
+
+  +
+
+ Image credit: [Khan Academy](https://www.khanacademy.org/computing/computer-programming/programming-natural-simulations/programming-oscillations/a/trig-and-forces-the-pendulum)
+
+Let's take a look at example which illustrates the basic method of dimensional analysis. Dimensional analysis, together with some physical intuition, allows us to find the equation for the period of oscillation for simple pendulum (a.k.a Huygens's law for the period).
+
+The procedure consists of 4 steps.
+
+##### 1. List relevant quantities
+
+We make a list of all the physical variables and constants on which the answer might depend. Which quantities could influence the period of oscillation of the pendulum? Well, my intuition tells me that the mass of the bob matters, as well as the length of the string. The oscillation happens because the gravity is acting on the pendulum, so let's account for that as well. To sum it up:
+
+| Quantity | Symbol | Unit |
+| -------- | ------ | --------------- |
+| period | $$T$$ | $$s$$ |
+| gravity | $$g$$ | $$\frac{m}{s^2}$$ |
+| mass | $$M$$ | $$kg$$ |
+| length | $$L$$ | $$m$$ |
+
+
+
+##### 2. Form independent dimensionless groups
+
+Those quantities shall be combined in the functional relation, such that the equation is dimensionally correct. How many independent relations (dimensionless group) are necessary to solve the problem? This is defined by the [Buckingham Pi theorem](https://en.wikipedia.org/wiki/Buckingham_π_theorem):
+
+> Number of independent dimensional groups = number of quantities - number of independent dimensions
+
+How many quantities do we have? Four - period, gravitational acceleration, mass and string's length. How many independent dimensions do we have? Three - mass, time and distance. The acceleration is derived from distance and time so we do not consider it. We end up with $$4-3=1$$ dimensional group.
+
+Assume that the product of listed quantities, each raised to some unknown power, shall be dimensionless:
+
+$$
+T^{\alpha}g^{\beta}M^{\gamma}L^{\theta} = C
+$$
+
+where $$C$$ is some dimensionless constant.
+
+##### 3. Make the most general dimensionless statement
+
+We solve system of four equations (choose the unknowns so that all the physical units in the equation cancel out) and obtain:
+
+$$
+\alpha=2, \beta=1, \gamma=0, \theta=-1
+$$
+
+$$
+T^{2}g^{1}M^{0}L^{-1} = C \implies T = C\sqrt{\frac{g}{l}}
+$$
+
+We have found our dimensionless relation. Note that mass was actually superfluous and vanished in the process.
+
+Also, note that the dimensionless constant $$C$$ is universal. The same constant applies to a pendulum on Mars or a pendulum with a different string length. Once we find the constant, we can reuse it for the wide range of different applications.
+
+##### 4. Use physical knowledge to narrow down the possibilities
+
+The last element is finding the dimensionless constant. How? Sure, you can solve the pendulum differential equation, but how about a small experiment? Take something which resembles a simple pendulum (e.g. I used my key chain) and make it oscillate. Write down the length and the period and plug it into equation to estimate $$C$$. If the value is close to $$6$$, well done! It is in fact $$2\pi$$!
+
+
+#### A Picture Worth a Thousand Tons of TNT
+
+  +
+
+ In the desert of New Mexico, the scientists and military servicemen of the ultra secret Manhattan Project watched as the first atomic bomb - code-named Trinity - was set off ($$1945$$).
+
+Estimating the period of the pendulum was just a warm up exercise. Time for something more exciting - estimation of the atomic bomb energy. Yes, this example will surely make us appreciate the power of the dimensional analysis.
+
+The first explosion of an atomic bomb happened in New Mexico in $$1945$$. Several years later a series of pictures of the explosion, along with a scale bar of the fireball and timestamps, were released out to the public. However, the information about the blast energy (yield) remained highly classified for years.
+
+However, with the use of the pictures and the dimensional analysis, the great scientists G.I Taylor estimated the secret value pretty accurately.
+
+Which quantities matter when it comes to the blast energy estimation? Let's see what information does the photograph (above) provide us. Obviously the radius of the fireball at the given time point is valuable. The bigger the radius at the given time point, the greater the power of the explosion. What else matters? Probably the density of the surrounding medium, air.
+
+| Quantity | Symbol | Unit |
+| ----------- | ------ | -------------------------- |
+| energy | $$E$$ | $$\frac{kg \cdot m^2}{s^2}$$ |
+| time | $$t$$ | $$s$$ |
+| radius | $$R$$ | $$m$$ |
+| air density | $$\rho$$ | $$\frac{kg}{m^3}$$ |
+
+Four quantities and three independent dimensions give us one independent dimensional group.
+
+Once again, we solve a system of equations and compute the dimensionless relationship:
+
+$$
+E^{\alpha}t^{\beta}R^{\gamma}\rho^{\theta} = C
+$$
+
+$$
+\alpha=1, \beta=2, \theta=-5, \gamma=-1
+$$
+
+$$
+E^{1}t^{2}R^{-5}\rho^{-1} = C \implies E = C\frac{\rho R^5}{t^2}
+$$
+
+Finding $$C$$ in the analogous way to the previous example is difficult (unless you have some spare atomic bombs). I can spill the beans and tell you, that G.I Taylor estimated it (using experimental data) to be close to $$1$$.
+
+While air density can be looked up, the radius and time can be read off from the photograph. At $$t=0.016$$ seconds we can say that $$R \approx 150$$ metres. Let's plug in the numbers to find the energy.
+
+$$
+E = \frac{1.2 \cdot 150^5}{0.016^2} \approx 10^{14}J
+$$
+
+$$10^{14}$$ Joules is equivalent to $$25$$ kilo-tons of TNT. Taylor has reported the value of $$22$$ kilo-tons in $$1950$$, while Fermi, who also used guesstimation to compute the yield obtained result of $$10$$ kilo-tons in $$1945$$. The actual, classified yield was $$20$$ kilo-tons. Not bad for the back-of-the-envelope calculation...
+
+**Conclusion: Dimensional analysis allows us to establish the form of an equation, or more often, to check that the answer to a calculation as a guard against many simple errors.**
+
+### Tool #6 Round and Simplify
+
+The tools presented so far allowed for discarding complexity without any information loss. But when going gets tough, we need to sacrifice the quality (accuracy) of the obtained solution for the ability to quickly solve a task at hand.
+
+#### Rounding to the Nearest Power of Ten
+
+This application of approximation is incredibly simple, yet very effective. By rounding to the nearest power of ten, complex calculations boil down to addition and subtraction of integer exponents.
+
+> Let's estimate the number of minutes in a month.
+
+Let's write down directly how many minutes are there in a 30 day month:
+
+$$
+1\text{ month} \times \frac{30 \text{ days}}{\text{month}} \times \frac{24\text{ hours}}{\text{day}} \times \frac{60\text{ minutes}}{\text{hour}} = 30 \times 24 \times 60 \text{ minutes}
+$$
+
+You may find it quite challenging to multiply all the numbers quickly. So let's round each factor to the nearest power of $$10$$. For example, because $$60$$ is a factor of almost $$2$$ away from $$100$$, but a factor of $$6$$ away from $$10$$, it gets rounded to $$100$$. We apply same rule for the other factors:
+
+$$
+30 \times 24 \times 60 \approx 10 \times 10\times 100 = 10^{1+1+2} = 10^4
+$$
+
+The exact value is $$43,200$$, so the estimate of $$10,000$$ is too small by $$23$$ percent. This is a reasonable price to pay for the ability to estimate such a big number without any effort.
+
+#### How High
+
+By combining approximations and simplifications with previously mentioned tools - **invariants** and **divide-and-conquer**, we can easily find to answer to the following (tough) question:
+
+> How does the jump height of an animal depend on its size?
+
+We want simple, so let's not get involved into the unnecessary complexity. Start with the first simplification: assume that the animal starts from rest and directly jumps upward.
+
+Fine, now we can try to start constructing some physical model to illustrate the problem. But which? The jump height seems to depend on so many factors: shape of the animal, amount of its muscles, efficiency of those muscles, whether the animal is bipedal or not and so on...
+
+Once again, start simple. We may use principle of **conservation** to define two quantities:
+
+- $$E_\text{supplied}$$ - the amount of energy needed for an animal to reach jumping height $$h$$.
+
+- $$E_\text{demanded}$$ - the maximum amount of energy that an animal can generate using its muscles.
+
+We can analyse both energy terms separately and then use the fact that they must be in equilibrium (like supply and demand in economics).
+
+  +
+
+A tree that summarises our model. Notice the use of **divide-and-conquer** reasoning.
+
+Energy demanded is the amount of energy needed for an animal to reach jumping height $$h$$. The type of energy, which is responsible for bodies being lifted up away from the Earth's surface is potential energy. It depends on the height $$h$$, body mass $$m_\text{body}$$ and gravity $$g$$. We can discard the gravity term - all the considered animals experience the same gravitational acceleration.
+
+$$
+E_\text{demanded} \propto m_\text{body}h
+$$
+
+Energy supplied is the maximum amount of energy an animal can generate using its muscles. This energy is simply a product of the muscle mass $$m_\text{muscle}$$ and the muscle energy density. Note that we are introducing another simplification: we treat all different muscles in the animal's body as one, homogenous tissue: all the muscles contribute equally to the jump. We can go even further and say that the muscle energy density is the same for all the living creatures. Some might say that this is too much of a simplification, but my guts tells me otherwise: all muscles use similar "biological technology". They have similar organic composition so why not treat them (approximately) equally? This assumption allows for consider the muscle energy density as constant so:
+
+$$
+E_\text{supplied} \propto m_\text{muscle} \cdot \text{energy density}_\text{muscle} \propto m_\text{muscle}
+$$
+
+Neat. The next question is what is the relationship between the muscle mass $$m_\text{muscle}$$ and body mass $$m_\text{body}$$? My guts tells me that this quantity does not only depends on the type of an animal (I would be surprised if this ratio was the same for a bull and a pig), but also on the age and gender (it would be different for an athletic male adult versus an old woman).
+
+Once again, let's simplify and throw away this information - treat the ratio as a constant. Yes, on hand we assume (courageously) that all animals have the same muscle to body mass ratio, but on the other hand we get to peel off the next layer of complexity.
+
+$$
+E_\text{supplied} \propto m_\text{muscle} \propto m_\text{body}
+$$
+
+Now we can compare the demanded and supplied energy to obtain the following relationship:
+
+$$
+m_\text{body}\propto m_\text{body}h
+$$
+
+Which means that jump height is in fact independent of the body mass of the animal!
+
+$$
+m_\text{body}^0 \propto h
+$$
+
+How can this be true? Let's think about it. Very small animals can jump very high. Think about insects such as fleas, grasshoppers or locust. But larger animals, such as crocodiles and turtles are very poor jumpers! Tigers, lions, humans and monkeys can jump very high. But can elephants jump at all? Let's allow the data to provide some answers:
+
+
+  +
+
+
+The data does in fact confirm our finding. For all the different animals, which mass spans from micrograms to tons (up to 8 orders of magnitude) the jumping height varies by tens of centimetres. The predicted scaling of constant $$m_\text{body}^0 \propto 1 \propto h$$ is surprisingly accurate.
+
+**Conclusion: When the problem overwhelms you, do not be afraid to lower your standards. Approximate first, worry later. Otherwise you never start, and you can never learn that the approximations would have been accurate enough—if only you had gathered the courage to make them.**
+
+### Tool #7 Consider Easy Cases First
+
+A correct analysis works in all cases—including the simplest ones. This principle is the basis of our next tool for discarding complexity: the method of easy cases. Easy cases help us check and, more surprisingly, guess solutions.
+
+To find easy cases, we need to find the appropriate dimensionless quantity $$\beta$$. The value of $$\beta$$ divides the system behaviour in three regimes: $$\beta \ll 1$$, $$\beta \approx 1$$, $$\beta \gg 1$$. The behaviour of the system in those three regimes (and the relationship between those regimes) often gives us great insight and reveals many useful facts.
+
+#### The Area of an Ellipse
+
+Let's use the method of easy cases to solve a simple problem: determine the area of an ellipse.
+
+We know that an ellipse is this peculiar, circle-like object with two focal points, hence two radii. We can be pretty confident that the area of the ellipse will depend on those two radii and since their ratio is a dimensionless quantity, we can use it as our $$\beta$$. Let's investigate the behaviour of $$\beta$$ for three regimes:
+
+| Regime 1 | Regime 2 | Regime 3 |
+| :----------------------------------------------------------: | :----------------------------------------------------------: | :----------------------------------------------------------: |
+| $$\frac{r_{1}}{r_{2}} =\beta \ll 1$$ | $$\frac{r_{1}}{r_{2}} =\beta \approx 1$$ | $$\frac{r_{1}}{r_{2}} =\beta \gg 1$$ |
+|  |
|  |
|  |
+| The area of the ellipse tends to $$0$$. | The ellipse becomes a radius with the area $$r_{1}^{2}\pi$$ (or $$r_{2}^{2}\pi$$ ). | The area of the ellipse tends to $$0$$. |
+
+Regime 2 suggests that $$r_{1}^{2}\pi$$ or $$r_{2}^{2}\pi$$ may be the answer, but we know that those are particular cases of an ellipse. On the other hand, regimes 1 and 3 suggest, that there is a symmetry in the problem. Perhaps, in the general equation we need to include both $$r_1$$ and $$r_2$$? This implies that interchanging $$r_{1}$$ and $$r_{2}$$ shall have no effect on the area of the ellipse. Those two pieces of information suggest that the correct equation should be:
+
+$$
+A=r_{1}r_{2}\pi
+$$
+
+Indeed, this equation is correct for all three regimes.
+
+#### Clearing the Atmosphere
+
+Many phenomena around us are the result of the physical state of equilibrium achieved by the nature. An example of such a system, which is governed by the natural balance, is our atmosphere. We know that there are forces acting on the atmosphere, but since it is (approximately) at rest, some physical equilibrium is present.
+
+Let's test the usefulness of **easy-cases** method to answer the following question:
+
+> What is the height of Earth's atmosphere?
+
+When we think about the height, we are interested in forces which act perpendicular to the surface of the earth. All the bodies on our planet are being pulled towards the Earth due to gravitation. Why is the atmosphere not collapsing - pulled all the way to the ground? This is due to the thermal energy of atmosphere's molecules. In absence of gravity the air molecules would basically scatter towards the space.
+
+So from the perspective of one "atmosphere molecule" there are two competing effects: gravity and thermal energy. Since both quantities are some form of energy, their ratio is a dimensionless quantity:
+
+$$
+\beta = \frac{E_\text{gravity}}{E_\text{thermal}}=\frac{mgh}{k_{b}T}
+$$
+
+Let's think about the behaviour of the system in terms of **easy-cases** regimes:
+
+| Regime 1 | Regime 2 | Regime 3 |
+| :----------------------------------------------------------: | :---------------------------------------------------: | :----------------------------------------------------------: |
+| $$\beta \ll 1$$ | $$\beta \approx 1$$ | $$\beta \gg 1$$ |
+| The dispersion of the molecules is stronger than the gravity - atmosphere expanding. | State of equilibrium - the atmosphere remains stable. | The dispersion of the molecules is weaker than the gravity - atmosphere contracting. |
+
+Nature is biased towards equilibria so we should use regime 2 to continue with our problem - computing the height of the atmosphere. Temperature of the atmosphere is about $$300$$ Kelvins, mass of the atmosphere can be approximated as a mass of a nitrogen molecule (Earth's atmosphere is mostly nitrogen) and gravitational acceleration and Boltzmann constant are known to us.
+
+$$
+h = \frac{Tk_b}{mg} \approx \frac{300 \cdot 1.38 \cdot 10^{-23}}{4.65 \cdot 10^{-26}\cdot 9.81} \approx 9000\text{m}
+$$
+
+In reality Earth's atmosphere stretches from the surface of the planet up to as far as $$10,000$$ kilometres above (after that, the atmosphere blends into space).
+
+**Conclusion: When the going gets tough, the tough lower your standards. A correct solution works in all cases, including the easy cases. Therefore, look at the easy cases first. Often, we can completely solve a problem simply by understanding the easy cases.**
+
+### Tool #8 Look for the Spring-like Behaviour
+
+The ideal spring, which you may know from high-school physics, produces a restoring force proportional to the displacement from equilibrium and stores an energy proportional to the displacement squared.
+
+$$
+\Delta E= F\Delta x = -k\Delta x \cdot \Delta x = k(\Delta x)^2
+$$
+
+We have already established, that the nature likes equilibria. If you swing a system out of balance, it usually wants to restore its initial stability. So yes, you've guessed it: many physical process "contain" a spring. Spring models are therefore very useful abstraction that can be used to speak about the connections between chemical bonds, trajectories of the planets or biomechanics of the human body. It is also useful in the material engineering.
+
+#### Young's Modulus as a Spring Constant
+
+Most engineering students at some point encounter the quantity known as Young's modulus. It is a fundamental property of every material, which describes its stiffness - how easily it bends or stretches. However it is not directly visible, how every material can be envisioned as a huge set of tiny springs and masses.
+
+
|
+| The area of the ellipse tends to $$0$$. | The ellipse becomes a radius with the area $$r_{1}^{2}\pi$$ (or $$r_{2}^{2}\pi$$ ). | The area of the ellipse tends to $$0$$. |
+
+Regime 2 suggests that $$r_{1}^{2}\pi$$ or $$r_{2}^{2}\pi$$ may be the answer, but we know that those are particular cases of an ellipse. On the other hand, regimes 1 and 3 suggest, that there is a symmetry in the problem. Perhaps, in the general equation we need to include both $$r_1$$ and $$r_2$$? This implies that interchanging $$r_{1}$$ and $$r_{2}$$ shall have no effect on the area of the ellipse. Those two pieces of information suggest that the correct equation should be:
+
+$$
+A=r_{1}r_{2}\pi
+$$
+
+Indeed, this equation is correct for all three regimes.
+
+#### Clearing the Atmosphere
+
+Many phenomena around us are the result of the physical state of equilibrium achieved by the nature. An example of such a system, which is governed by the natural balance, is our atmosphere. We know that there are forces acting on the atmosphere, but since it is (approximately) at rest, some physical equilibrium is present.
+
+Let's test the usefulness of **easy-cases** method to answer the following question:
+
+> What is the height of Earth's atmosphere?
+
+When we think about the height, we are interested in forces which act perpendicular to the surface of the earth. All the bodies on our planet are being pulled towards the Earth due to gravitation. Why is the atmosphere not collapsing - pulled all the way to the ground? This is due to the thermal energy of atmosphere's molecules. In absence of gravity the air molecules would basically scatter towards the space.
+
+So from the perspective of one "atmosphere molecule" there are two competing effects: gravity and thermal energy. Since both quantities are some form of energy, their ratio is a dimensionless quantity:
+
+$$
+\beta = \frac{E_\text{gravity}}{E_\text{thermal}}=\frac{mgh}{k_{b}T}
+$$
+
+Let's think about the behaviour of the system in terms of **easy-cases** regimes:
+
+| Regime 1 | Regime 2 | Regime 3 |
+| :----------------------------------------------------------: | :---------------------------------------------------: | :----------------------------------------------------------: |
+| $$\beta \ll 1$$ | $$\beta \approx 1$$ | $$\beta \gg 1$$ |
+| The dispersion of the molecules is stronger than the gravity - atmosphere expanding. | State of equilibrium - the atmosphere remains stable. | The dispersion of the molecules is weaker than the gravity - atmosphere contracting. |
+
+Nature is biased towards equilibria so we should use regime 2 to continue with our problem - computing the height of the atmosphere. Temperature of the atmosphere is about $$300$$ Kelvins, mass of the atmosphere can be approximated as a mass of a nitrogen molecule (Earth's atmosphere is mostly nitrogen) and gravitational acceleration and Boltzmann constant are known to us.
+
+$$
+h = \frac{Tk_b}{mg} \approx \frac{300 \cdot 1.38 \cdot 10^{-23}}{4.65 \cdot 10^{-26}\cdot 9.81} \approx 9000\text{m}
+$$
+
+In reality Earth's atmosphere stretches from the surface of the planet up to as far as $$10,000$$ kilometres above (after that, the atmosphere blends into space).
+
+**Conclusion: When the going gets tough, the tough lower your standards. A correct solution works in all cases, including the easy cases. Therefore, look at the easy cases first. Often, we can completely solve a problem simply by understanding the easy cases.**
+
+### Tool #8 Look for the Spring-like Behaviour
+
+The ideal spring, which you may know from high-school physics, produces a restoring force proportional to the displacement from equilibrium and stores an energy proportional to the displacement squared.
+
+$$
+\Delta E= F\Delta x = -k\Delta x \cdot \Delta x = k(\Delta x)^2
+$$
+
+We have already established, that the nature likes equilibria. If you swing a system out of balance, it usually wants to restore its initial stability. So yes, you've guessed it: many physical process "contain" a spring. Spring models are therefore very useful abstraction that can be used to speak about the connections between chemical bonds, trajectories of the planets or biomechanics of the human body. It is also useful in the material engineering.
+
+#### Young's Modulus as a Spring Constant
+
+Most engineering students at some point encounter the quantity known as Young's modulus. It is a fundamental property of every material, which describes its stiffness - how easily it bends or stretches. However it is not directly visible, how every material can be envisioned as a huge set of tiny springs and masses.
+
+
+  +
+
+ Image source: "The Art of Insight in Science and Engineering: Mastering Complexity"
+
+Young's modulus is a function of two values: stress (the force applied to a material, divided by the its cross-sectional area) and strain (deformation of material that results from an applied stress).
+
+$$
+Y = \frac{\text{stress}}{\text{strain}}
+$$
+
+While stress is straightforward to compute (using force applied and the cross-section of the block of material, $$\text{stress} = \frac{F}{A}$$), it can be quite difficult to compute material's strain. However, we can easily estimate it through modelling a block of material as a system of springs and masses. Imagine that a block of material is in fact a bundle of tiny, elastic fibres.
+
+
+  +
+
+
+Each fibre is a chain (series) of springs (bonds) and masses (atoms).
+
+
+  +
+
+
+Since strain is the fractional length change, the strain in the block is the strain in each fibre:
+
+$$
+\text{strain} = \frac{\Delta x}{a}
+$$
+
+Where $$\Delta x$$ is the extension of the spring and $a$ is the length of the bond between two atoms at rest.
+
+How to compute $$\Delta x$$? Using the spring equation for a single fibre:
+
+$$
+\frac{F}{N_\text{fibres}} = k\Delta x
+$$
+
+Where $$F$$ is the force acting on the block of material, $$N_\text{fibres}$$ is the number of fibres in the block, $$k$$ is the spring constant and $$\Delta x$$ is the spring extension.
+
+How many fibres are there in the block of materials? We know $$A$$, the cross-section of the block of material. We also know the approximate cross-section of one fibre - $$a^2$$, so:
+
+$$
+N_\text{fibres} = \frac{A}{a^2}
+$$
+
+Notice, how we used **divide-and-conquer** reasoning to break down the problem into smaller components. Now let's collect of the established information and derive the equation for Young's modulus:
+
+$$
+Y = \frac{\text{stress}}{\text{strain}} = \frac{\frac{F}{A}}{\frac{\Delta x}{a}}=\frac{Fa}{A\Delta x} = \frac{Fa}{A\frac{F}{kN_\text{fibres}}}= k\frac{aN_\text{fibres}}{A}=k\frac{a\frac{A}{a^2}}{A}=\frac{k}{a}
+$$
+
+So Young's modulus has actually a neat micro-level interpretation. It a direct function of the interatomic spring constant $$k$$ and the distance between atoms in the material's lattice.
+
+**Conclusion: Many physical processes contain a minimum-energy state where small deviations from the minimum require an energy proportional to the square of the deviation. This behavior is the essential characteristic of a spring. A spring is therefore not only a physical object but a transferable abstraction.**
+
+### Tool #7 Probabilistic Reasoning
+
+The final element in our toolbox is **probabilistic reasoning**. Bayesian thinking is a very useful [every-day "philosophy"](https://www.youtube.com/watch?v=BrK7X_XlGB8)- so it should come as no surprise, that we would like to include it in our back-of-the-envelope calculations. **Probabilistic reasoning** is a nice sprinkle on top of **divide-and-conquer**. It allows us to do the same decomposition of the problem as before, but now the estimated values are not point estimates anymore, they are probability distributions - confidence intervals.
+
+#### Setzen Alles Auf Eine (Land-)Karte
+
+> Let's estimate the area of Germany.
+
+##### Method 1: Quick Order-of-Magnitude Estimation
+
+To compute the area of a country, we can do quick order-of-magnitude estimation. Imagine that Germany has perfectly rectangular area. Given, that we speak in terms of kilometres, could the area of Germany be $$10 \times 10$$? Absolutely not! $$100 \times 100$$? Still, too little. $$1000 \times 1000$$, probably too much... So it seems that the good estimate is somewhere between $$10^5$$ and $$10^6$$. I am pretty sure about that, so I may give 2-to-1 odds that the correct value lies in that range. 2-to-1 odds means that I attach probability $$P\approx 2/3$$ to this statement.
+
+
+ .png) +
+
+
+$$
+A_\text{order-of-magnitude} = 10^5...10^6 \text{ }[\text{km}^2]
+$$
+
+##### Method 2: Divide-and-Conquer
+
+This is the result obtained from rough estimation. Now let's use **divide-and-conquer** reasoning. The rectangular area is product of two values: height and width.
+
+The height of Germany is a bit more than a distance between Hamburg and Munich. Having spent a lot of time travelling between those cities in the past, I know that it takes about $$8$$ hours by car to cross Germany north to south. This implies the distance of $$1200$$ kilometres. While I am not sure about the exact value, I think that it's not less than $$800$$, but not more than $$1500$$ kilometres. Once again, I attach probability of $$P\approx 2/3$$ to this statement.
+
+Germany is certainly longer than wider, so the width is less than the height. To travel from Hamburg to the Dutch border it takes about $$5$$ hours or so. I am not really sure, but I bet that it is not less than $$300$$, and not more than $$600$$ kilometres.
+
+$$
+h_\text{divide-and-conquer} = 800...1500 \text{ }[\text{km}]
+$$
+
+$$
+w_\text{divide-and-conquer} = 300...600 \text{ }[\text{km}]
+$$
+
+$$
+A_{min, \text{divide-and-conquer}} = 800 \cdot 300 = 240,000 \text{ }[\text{km}]
+$$
+
+$$
+A_{max, \text{divide-and-conquer}} = 600 \cdot 1500 = 900,000 \text{ }[\text{km}]
+$$
+
+
+ .png) +
+
+
+We can already see the benefits of **divide-and-conquer** over the rough order-of-magnitude estimation - we are much more surer about the actual result. It has significantly narrowed the confidence interval by replacing a quantity about which we have vague knowledge (area), with quantities about which can be approximated much more precisely (width and height). The direct approximation gives us a range which spans over ratio of $$10$$. However, divide-and-conquer gives the ratio of $$\frac{A_{max}}{A_{min}} \approx 3.75$$.
+
+##### Method 3: Divide-and-Conquer + Probabilistic Reasoning
+
+We can express the estimation for height and width as probability distributions: log-normal distributions. There are three reasons for choosing this particular distribution: it is more compatible with our "mental hardware" (humans think in terms of ratios), easy to describe and simple to perform computations with. For example, confidence interval of the height can be characterised by a following (geometric) mean and standard distribution (ratio):
+
+$$
+h_{\mu} = \sqrt{h_{min} \cdot h_{max}}=1095
+$$
+
+$$
+h_{\sigma} = \frac{h_{max}}{h_{\mu}} =\frac{h_{\mu}}{h_{min}} = 1.37
+$$
+
+
+  +
+
+
+Same applies for the width.
+
+
+  +
+
+
+Now to find the area, we can combine those two distributions, which is equivalent of multiplying two point estimates - width and height.
+
+The mean is simply a product of geometric means:
+
+$$
+A_{\mu} = h_{\mu} \cdot h_{\mu}= 464,758\text{ }[\text{km}^2]
+$$
+
+Standard deviation of product of two (independent) normal distributions is:
+
+$$
+\sigma_{3} = \sqrt{\sigma_{1}^2 \cdot \sigma_{2}^2}
+$$
+
+However, in our log-normal form, the standard deviation of area needs to be computed in log space:
+
+$$
+\ln\sigma_{A} = \ln(\sqrt{\sigma_{h}^2 + \sigma_{w}^2}) \implies \sigma_{A} = e^{(\sqrt{(\ln{\sigma_{h}})^2 + (\ln{\sigma_{w}})^2}}=1.60
+$$
+
+By combining **divide-and-conquer** with **probabilistic reasoning** we get the following estimate of the area:
+
+$$
+A_{min, \text{probabilistic reasoning}} = A_{\mu} / A_{\sigma} = 291,094 \text{ }[\text{km}^2]
+$$
+
+$$
+A_{max, \text{probabilistic reasoning}} = A_{\mu} \cdot A_{\sigma} = 742,026 \text{ }[\text{km}^2]
+$$
+
+$$
+A_\text{probabilistic-reasoning} = 291, 094...742,026 \text{ }[\text{km}^2]
+$$
+
+...while the actual area of Germany is $$357,386$$ square kilometres - comfortably included in my predicted range.
+
+
+ .png) +
+
+
+Probabilistic reasoning gives us the values range which spans only over the ratio of $$2.55$$ (variance of the distribution).
+
+How did we produce such accurate estimate? This problem is hard to analyse directly because we do not know the accuracy in advance. But we can analyse a related problem: how divide-and-conquer reasoning increases our confidence in an estimate or, more precisely, decreases our uncertainty.
+
+**Conclusion: In complex systems, the information is either overwhelming or not available. Then we have to reason with incomplete information. The tool for this purpose is probabilistic reasoning, which helps us manage incomplete information. It can e.g. help us to estimate the uncertainty in our divide-and-conquer reasoning.**
diff --git a/assets/1/Picture1.jpg b/assets/1/Picture1.jpg
new file mode 100644
index 0000000000..a0fee60d9f
Binary files /dev/null and b/assets/1/Picture1.jpg differ
diff --git a/assets/1/Picture2.jpg b/assets/1/Picture2.jpg
new file mode 100644
index 0000000000..afcdc559f5
Binary files /dev/null and b/assets/1/Picture2.jpg differ
diff --git a/assets/1/Picture3.jpg b/assets/1/Picture3.jpg
new file mode 100644
index 0000000000..6b096e1090
Binary files /dev/null and b/assets/1/Picture3.jpg differ
diff --git a/assets/1/thinker.jpg b/assets/1/thinker.jpg
new file mode 100644
index 0000000000..dac0133864
Binary files /dev/null and b/assets/1/thinker.jpg differ
diff --git a/assets/10/ReadMe.md b/assets/10/ReadMe.md
new file mode 100644
index 0000000000..8b13789179
--- /dev/null
+++ b/assets/10/ReadMe.md
@@ -0,0 +1 @@
+
diff --git a/assets/10/bi_59.png b/assets/10/bi_59.png
new file mode 100644
index 0000000000..cbd1a8c976
Binary files /dev/null and b/assets/10/bi_59.png differ
diff --git a/assets/10/blog_image.png b/assets/10/blog_image.png
new file mode 100644
index 0000000000..f109a463a7
Binary files /dev/null and b/assets/10/blog_image.png differ
diff --git a/assets/10/blog_image1.png b/assets/10/blog_image1.png
new file mode 100644
index 0000000000..f109a463a7
Binary files /dev/null and b/assets/10/blog_image1.png differ
diff --git a/assets/10/bs_59.png b/assets/10/bs_59.png
new file mode 100644
index 0000000000..13e4ed3b72
Binary files /dev/null and b/assets/10/bs_59.png differ
diff --git a/assets/10/ezgif.com-gif-maker-10.gif b/assets/10/ezgif.com-gif-maker-10.gif
new file mode 100644
index 0000000000..7bd9b52702
Binary files /dev/null and b/assets/10/ezgif.com-gif-maker-10.gif differ
diff --git a/assets/10/ezgif.com-gif-maker-11.gif b/assets/10/ezgif.com-gif-maker-11.gif
new file mode 100644
index 0000000000..bf813da02e
Binary files /dev/null and b/assets/10/ezgif.com-gif-maker-11.gif differ
diff --git a/assets/10/ezgif.com-gif-maker-12.gif b/assets/10/ezgif.com-gif-maker-12.gif
new file mode 100644
index 0000000000..9ccb3f453a
Binary files /dev/null and b/assets/10/ezgif.com-gif-maker-12.gif differ
diff --git a/assets/10/ezgif.com-gif-maker-13.gif b/assets/10/ezgif.com-gif-maker-13.gif
new file mode 100644
index 0000000000..42b882d8a6
Binary files /dev/null and b/assets/10/ezgif.com-gif-maker-13.gif differ
diff --git a/assets/10/test.png b/assets/10/test.png
new file mode 100644
index 0000000000..9ad436d8ad
Binary files /dev/null and b/assets/10/test.png differ
diff --git a/assets/11/ReadMe.md b/assets/11/ReadMe.md
new file mode 100644
index 0000000000..8b13789179
--- /dev/null
+++ b/assets/11/ReadMe.md
@@ -0,0 +1 @@
+
diff --git a/assets/11/Zrzut ekranu 2020-10-11 o 14.10.07.png b/assets/11/Zrzut ekranu 2020-10-11 o 14.10.07.png
new file mode 100644
index 0000000000..137615fe28
Binary files /dev/null and b/assets/11/Zrzut ekranu 2020-10-11 o 14.10.07.png differ
diff --git a/assets/11/Zrzut ekranu 2020-10-11 o 14.11.23.png b/assets/11/Zrzut ekranu 2020-10-11 o 14.11.23.png
new file mode 100644
index 0000000000..b31346a870
Binary files /dev/null and b/assets/11/Zrzut ekranu 2020-10-11 o 14.11.23.png differ
diff --git a/assets/11/Zrzut ekranu 2020-10-11 o 14.11.47.png b/assets/11/Zrzut ekranu 2020-10-11 o 14.11.47.png
new file mode 100644
index 0000000000..0a014db37e
Binary files /dev/null and b/assets/11/Zrzut ekranu 2020-10-11 o 14.11.47.png differ
diff --git a/assets/11/Zrzut ekranu 2020-10-11 o 14.12.14.png b/assets/11/Zrzut ekranu 2020-10-11 o 14.12.14.png
new file mode 100644
index 0000000000..d94632ff49
Binary files /dev/null and b/assets/11/Zrzut ekranu 2020-10-11 o 14.12.14.png differ
diff --git a/assets/11/Zrzut ekranu 2020-10-11 o 14.12.29.png b/assets/11/Zrzut ekranu 2020-10-11 o 14.12.29.png
new file mode 100644
index 0000000000..4ea5017a92
Binary files /dev/null and b/assets/11/Zrzut ekranu 2020-10-11 o 14.12.29.png differ
diff --git a/assets/11/agent_utility.png b/assets/11/agent_utility.png
new file mode 100644
index 0000000000..ca7339ab32
Binary files /dev/null and b/assets/11/agent_utility.png differ
diff --git a/assets/12/TD3.png b/assets/12/TD3.png
new file mode 100644
index 0000000000..bae6ad7f65
Binary files /dev/null and b/assets/12/TD3.png differ
diff --git a/assets/12/blog_related_TD3.png b/assets/12/blog_related_TD3.png
new file mode 100644
index 0000000000..12b3d29bbc
Binary files /dev/null and b/assets/12/blog_related_TD3.png differ
diff --git a/assets/12/graph_plot.001.png b/assets/12/graph_plot.001.png
new file mode 100644
index 0000000000..e4b9382e0d
Binary files /dev/null and b/assets/12/graph_plot.001.png differ
diff --git a/assets/12/logo.png b/assets/12/logo.png
new file mode 100644
index 0000000000..1fbc525c84
Binary files /dev/null and b/assets/12/logo.png differ
diff --git a/assets/12/real_infer.gif b/assets/12/real_infer.gif
new file mode 100644
index 0000000000..965bc49ef7
Binary files /dev/null and b/assets/12/real_infer.gif differ
diff --git a/assets/12/sim_agent.gif b/assets/12/sim_agent.gif
new file mode 100644
index 0000000000..fdd793fd36
Binary files /dev/null and b/assets/12/sim_agent.gif differ
diff --git a/assets/12/sim_env.png b/assets/12/sim_env.png
new file mode 100644
index 0000000000..6428d2d79e
Binary files /dev/null and b/assets/12/sim_env.png differ
diff --git a/assets/12/training.png b/assets/12/training.png
new file mode 100644
index 0000000000..73ba0bbe73
Binary files /dev/null and b/assets/12/training.png differ
diff --git a/assets/12/tutorial_gif.gif b/assets/12/tutorial_gif.gif
new file mode 100644
index 0000000000..bbbbbd7602
Binary files /dev/null and b/assets/12/tutorial_gif.gif differ
diff --git a/assets/13/README.md b/assets/13/README.md
new file mode 100644
index 0000000000..8b13789179
--- /dev/null
+++ b/assets/13/README.md
@@ -0,0 +1 @@
+
diff --git a/assets/13/Untitled Diagram-3.png b/assets/13/Untitled Diagram-3.png
new file mode 100644
index 0000000000..74a30152eb
Binary files /dev/null and b/assets/13/Untitled Diagram-3.png differ
diff --git a/assets/13/image1.png b/assets/13/image1.png
new file mode 100644
index 0000000000..d8f0b61525
Binary files /dev/null and b/assets/13/image1.png differ
diff --git a/assets/13/image10.png b/assets/13/image10.png
new file mode 100644
index 0000000000..13c848e400
Binary files /dev/null and b/assets/13/image10.png differ
diff --git a/assets/13/image11.png b/assets/13/image11.png
new file mode 100644
index 0000000000..d64ad8efcb
Binary files /dev/null and b/assets/13/image11.png differ
diff --git a/assets/13/image12.png b/assets/13/image12.png
new file mode 100644
index 0000000000..c67dc83b76
Binary files /dev/null and b/assets/13/image12.png differ
diff --git a/assets/13/image13.png b/assets/13/image13.png
new file mode 100644
index 0000000000..633c875b84
Binary files /dev/null and b/assets/13/image13.png differ
diff --git a/assets/13/image4.png b/assets/13/image4.png
new file mode 100644
index 0000000000..3a8946fada
Binary files /dev/null and b/assets/13/image4.png differ
diff --git a/assets/13/image5.jpg b/assets/13/image5.jpg
new file mode 100644
index 0000000000..5316eb5208
Binary files /dev/null and b/assets/13/image5.jpg differ
diff --git a/assets/13/image6.svg b/assets/13/image6.svg
new file mode 100644
index 0000000000..7286b4ba50
--- /dev/null
+++ b/assets/13/image6.svg
@@ -0,0 +1,3 @@
+
+
+
\ No newline at end of file
diff --git a/assets/13/image7.png b/assets/13/image7.png
new file mode 100644
index 0000000000..10ed862659
Binary files /dev/null and b/assets/13/image7.png differ
diff --git a/assets/13/image8.png b/assets/13/image8.png
new file mode 100644
index 0000000000..7a34a440bc
Binary files /dev/null and b/assets/13/image8.png differ
diff --git a/assets/13/image9.png b/assets/13/image9.png
new file mode 100644
index 0000000000..640e6a9e88
Binary files /dev/null and b/assets/13/image9.png differ
diff --git a/assets/13/image_Area (divide-conquer).png b/assets/13/image_Area (divide-conquer).png
new file mode 100644
index 0000000000..5532d5c3c2
Binary files /dev/null and b/assets/13/image_Area (divide-conquer).png differ
diff --git a/assets/13/image_Area (order-of-magnitude).png b/assets/13/image_Area (order-of-magnitude).png
new file mode 100644
index 0000000000..537b63496f
Binary files /dev/null and b/assets/13/image_Area (order-of-magnitude).png differ
diff --git a/assets/13/image_Area (probabilistic reasoning).png b/assets/13/image_Area (probabilistic reasoning).png
new file mode 100644
index 0000000000..ea89acee8a
Binary files /dev/null and b/assets/13/image_Area (probabilistic reasoning).png differ
diff --git a/assets/13/image_Height.png b/assets/13/image_Height.png
new file mode 100644
index 0000000000..14c8cfb6bb
Binary files /dev/null and b/assets/13/image_Height.png differ
diff --git a/assets/13/image_Width.png b/assets/13/image_Width.png
new file mode 100644
index 0000000000..a779f05e49
Binary files /dev/null and b/assets/13/image_Width.png differ
diff --git a/assets/13/image_height_.png b/assets/13/image_height_.png
new file mode 100644
index 0000000000..438d64090f
Binary files /dev/null and b/assets/13/image_height_.png differ
diff --git a/assets/13/image_width_.png b/assets/13/image_width_.png
new file mode 100644
index 0000000000..415d7f83c5
Binary files /dev/null and b/assets/13/image_width_.png differ
diff --git a/assets/13/unknown.png b/assets/13/unknown.png
new file mode 100644
index 0000000000..269c677d28
Binary files /dev/null and b/assets/13/unknown.png differ
diff --git a/assets/2/104610626--sites-default-files-images-104609106-chuck.1910x1000.jpg b/assets/2/104610626--sites-default-files-images-104609106-chuck.1910x1000.jpg
new file mode 100644
index 0000000000..7a7df673f6
Binary files /dev/null and b/assets/2/104610626--sites-default-files-images-104609106-chuck.1910x1000.jpg differ
diff --git a/assets/2/28.png b/assets/2/28.png
new file mode 100644
index 0000000000..8c91525641
Binary files /dev/null and b/assets/2/28.png differ
diff --git a/assets/2/29.png b/assets/2/29.png
new file mode 100644
index 0000000000..c7113f33de
Binary files /dev/null and b/assets/2/29.png differ
diff --git a/assets/2/30.png b/assets/2/30.png
new file mode 100644
index 0000000000..4620c434fa
Binary files /dev/null and b/assets/2/30.png differ
diff --git a/assets/2/31.png b/assets/2/31.png
new file mode 100644
index 0000000000..0a86e3eef1
Binary files /dev/null and b/assets/2/31.png differ
diff --git a/assets/2/agent.png b/assets/2/agent.png
new file mode 100644
index 0000000000..bd7a9e6171
Binary files /dev/null and b/assets/2/agent.png differ
diff --git a/assets/2/filtering.gif b/assets/2/filtering.gif
new file mode 100644
index 0000000000..af74cfe5d5
Binary files /dev/null and b/assets/2/filtering.gif differ
diff --git a/assets/2/prediction.gif b/assets/2/prediction.gif
new file mode 100644
index 0000000000..2e75d63dc9
Binary files /dev/null and b/assets/2/prediction.gif differ
diff --git a/assets/2/warehouse.jpg b/assets/2/warehouse.jpg
new file mode 100644
index 0000000000..778b9a3067
Binary files /dev/null and b/assets/2/warehouse.jpg differ
diff --git a/assets/3/Figure_1.gif b/assets/3/Figure_1.gif
new file mode 100644
index 0000000000..9f6feec7f2
Binary files /dev/null and b/assets/3/Figure_1.gif differ
diff --git a/assets/3/Figure_2.png b/assets/3/Figure_2.png
new file mode 100644
index 0000000000..a4ef2e49fe
Binary files /dev/null and b/assets/3/Figure_2.png differ
diff --git a/assets/3/Figure_3.png b/assets/3/Figure_3.png
new file mode 100644
index 0000000000..9c0f4d1ca8
Binary files /dev/null and b/assets/3/Figure_3.png differ
diff --git a/assets/4/1.jpg b/assets/4/1.jpg
new file mode 100644
index 0000000000..f59e6114ac
Binary files /dev/null and b/assets/4/1.jpg differ
diff --git a/assets/4/10.gif b/assets/4/10.gif
new file mode 100644
index 0000000000..61f985ed07
Binary files /dev/null and b/assets/4/10.gif differ
diff --git a/assets/4/2.jpg b/assets/4/2.jpg
new file mode 100644
index 0000000000..81e60f09ff
Binary files /dev/null and b/assets/4/2.jpg differ
diff --git a/assets/4/3.png b/assets/4/3.png
new file mode 100644
index 0000000000..580d800615
Binary files /dev/null and b/assets/4/3.png differ
diff --git a/assets/4/5.png b/assets/4/5.png
new file mode 100644
index 0000000000..3d1b749fd5
Binary files /dev/null and b/assets/4/5.png differ
diff --git a/assets/4/6.png b/assets/4/6.png
new file mode 100644
index 0000000000..55fb86761c
Binary files /dev/null and b/assets/4/6.png differ
diff --git a/assets/4/7.png b/assets/4/7.png
new file mode 100644
index 0000000000..f824052119
Binary files /dev/null and b/assets/4/7.png differ
diff --git a/assets/4/8.png b/assets/4/8.png
new file mode 100644
index 0000000000..a703a428d7
Binary files /dev/null and b/assets/4/8.png differ
diff --git a/assets/4/Readme.md b/assets/4/Readme.md
new file mode 100644
index 0000000000..8b13789179
--- /dev/null
+++ b/assets/4/Readme.md
@@ -0,0 +1 @@
+
diff --git a/assets/5/1.png b/assets/5/1.png
new file mode 100644
index 0000000000..aeb840f0df
Binary files /dev/null and b/assets/5/1.png differ
diff --git a/assets/5/10.png b/assets/5/10.png
new file mode 100644
index 0000000000..249fb2cef0
Binary files /dev/null and b/assets/5/10.png differ
diff --git a/assets/5/11.png b/assets/5/11.png
new file mode 100644
index 0000000000..5581780c20
Binary files /dev/null and b/assets/5/11.png differ
diff --git a/assets/5/12.png b/assets/5/12.png
new file mode 100644
index 0000000000..a246dc4c25
Binary files /dev/null and b/assets/5/12.png differ
diff --git a/assets/5/13.png b/assets/5/13.png
new file mode 100644
index 0000000000..9ce5feab74
Binary files /dev/null and b/assets/5/13.png differ
diff --git a/assets/5/2.png b/assets/5/2.png
new file mode 100644
index 0000000000..262c767616
Binary files /dev/null and b/assets/5/2.png differ
diff --git a/assets/5/3.png b/assets/5/3.png
new file mode 100644
index 0000000000..84b925eca1
Binary files /dev/null and b/assets/5/3.png differ
diff --git a/assets/5/4.png b/assets/5/4.png
new file mode 100644
index 0000000000..ad81b87fe2
Binary files /dev/null and b/assets/5/4.png differ
diff --git a/assets/5/5.png b/assets/5/5.png
new file mode 100644
index 0000000000..3c44be6a72
Binary files /dev/null and b/assets/5/5.png differ
diff --git a/assets/5/6.png b/assets/5/6.png
new file mode 100644
index 0000000000..ce67b41b87
Binary files /dev/null and b/assets/5/6.png differ
diff --git a/assets/5/7.png b/assets/5/7.png
new file mode 100644
index 0000000000..2d223b7233
Binary files /dev/null and b/assets/5/7.png differ
diff --git a/assets/5/8.png b/assets/5/8.png
new file mode 100644
index 0000000000..202c2f9dae
Binary files /dev/null and b/assets/5/8.png differ
diff --git a/assets/5/Readme.md b/assets/5/Readme.md
new file mode 100644
index 0000000000..8b13789179
--- /dev/null
+++ b/assets/5/Readme.md
@@ -0,0 +1 @@
+
diff --git a/assets/6/GEAR-cover.png b/assets/6/GEAR-cover.png
new file mode 100644
index 0000000000..f1f7afb084
Binary files /dev/null and b/assets/6/GEAR-cover.png differ
diff --git a/assets/6/collect-avoid.png b/assets/6/collect-avoid.png
new file mode 100644
index 0000000000..ec57d10c23
Binary files /dev/null and b/assets/6/collect-avoid.png differ
diff --git a/assets/6/final1.gif b/assets/6/final1.gif
new file mode 100644
index 0000000000..1b46669676
Binary files /dev/null and b/assets/6/final1.gif differ
diff --git a/assets/6/final2.gif b/assets/6/final2.gif
new file mode 100644
index 0000000000..1c0279c665
Binary files /dev/null and b/assets/6/final2.gif differ
diff --git a/assets/6/final3.gif b/assets/6/final3.gif
new file mode 100644
index 0000000000..b531d55fe0
Binary files /dev/null and b/assets/6/final3.gif differ
diff --git a/assets/6/greenvol.png b/assets/6/greenvol.png
new file mode 100644
index 0000000000..d73fb77f05
Binary files /dev/null and b/assets/6/greenvol.png differ
diff --git a/assets/6/heurgif.gif b/assets/6/heurgif.gif
new file mode 100644
index 0000000000..04861f6687
Binary files /dev/null and b/assets/6/heurgif.gif differ
diff --git a/assets/6/multiagents.gif b/assets/6/multiagents.gif
new file mode 100644
index 0000000000..9400e0ea7a
Binary files /dev/null and b/assets/6/multiagents.gif differ
diff --git a/assets/6/overview_fleet.mp4 b/assets/6/overview_fleet.mp4
new file mode 100644
index 0000000000..04fff5d594
Binary files /dev/null and b/assets/6/overview_fleet.mp4 differ
diff --git a/assets/6/pca.png b/assets/6/pca.png
new file mode 100644
index 0000000000..20249cb52e
Binary files /dev/null and b/assets/6/pca.png differ
diff --git a/assets/6/presentation.jpg b/assets/6/presentation.jpg
new file mode 100644
index 0000000000..40f4e5543f
Binary files /dev/null and b/assets/6/presentation.jpg differ
diff --git a/assets/6/readme.md b/assets/6/readme.md
new file mode 100644
index 0000000000..4bcfe98e64
--- /dev/null
+++ b/assets/6/readme.md
@@ -0,0 +1 @@
+d
diff --git a/assets/6/scene.png b/assets/6/scene.png
new file mode 100644
index 0000000000..4471f914db
Binary files /dev/null and b/assets/6/scene.png differ
diff --git a/assets/6/segnet.png b/assets/6/segnet.png
new file mode 100644
index 0000000000..dfdd43b1b3
Binary files /dev/null and b/assets/6/segnet.png differ
diff --git a/assets/7/UCB-1-results.png b/assets/7/UCB-1-results.png
new file mode 100644
index 0000000000..8deb2c3198
Binary files /dev/null and b/assets/7/UCB-1-results.png differ
diff --git a/assets/7/example.gif b/assets/7/example.gif
new file mode 100644
index 0000000000..94c63706d5
Binary files /dev/null and b/assets/7/example.gif differ
diff --git a/assets/7/giphy.gif b/assets/7/giphy.gif
new file mode 100644
index 0000000000..86327dc29d
Binary files /dev/null and b/assets/7/giphy.gif differ
diff --git a/assets/7/true_probability.png b/assets/7/true_probability.png
new file mode 100644
index 0000000000..81d6ee194d
Binary files /dev/null and b/assets/7/true_probability.png differ
diff --git a/assets/8/2000.gif b/assets/8/2000.gif
new file mode 100644
index 0000000000..482217f0c0
Binary files /dev/null and b/assets/8/2000.gif differ
diff --git a/assets/8/2001.gif b/assets/8/2001.gif
new file mode 100644
index 0000000000..7a61e0270b
Binary files /dev/null and b/assets/8/2001.gif differ
diff --git a/assets/8/2002.gif b/assets/8/2002.gif
new file mode 100644
index 0000000000..1b98373026
Binary files /dev/null and b/assets/8/2002.gif differ
diff --git a/assets/8/2003.gif b/assets/8/2003.gif
new file mode 100644
index 0000000000..330c4b0009
Binary files /dev/null and b/assets/8/2003.gif differ
diff --git a/assets/8/2004.gif b/assets/8/2004.gif
new file mode 100644
index 0000000000..9ba350b975
Binary files /dev/null and b/assets/8/2004.gif differ
diff --git a/assets/8/2005.gif b/assets/8/2005.gif
new file mode 100644
index 0000000000..9da57ca746
Binary files /dev/null and b/assets/8/2005.gif differ
diff --git a/assets/8/2006.gif b/assets/8/2006.gif
new file mode 100644
index 0000000000..ba0d0b76ea
Binary files /dev/null and b/assets/8/2006.gif differ
diff --git a/assets/8/2007.gif b/assets/8/2007.gif
new file mode 100644
index 0000000000..c62186a14c
Binary files /dev/null and b/assets/8/2007.gif differ
diff --git a/assets/8/3000.gif b/assets/8/3000.gif
new file mode 100644
index 0000000000..ba4f22dac0
Binary files /dev/null and b/assets/8/3000.gif differ
diff --git a/assets/8/3001.gif b/assets/8/3001.gif
new file mode 100644
index 0000000000..7e183fcf13
Binary files /dev/null and b/assets/8/3001.gif differ
diff --git a/assets/8/3002.gif b/assets/8/3002.gif
new file mode 100644
index 0000000000..6eb7ce9dc4
Binary files /dev/null and b/assets/8/3002.gif differ
diff --git a/assets/8/3003.gif b/assets/8/3003.gif
new file mode 100644
index 0000000000..2737a3f05d
Binary files /dev/null and b/assets/8/3003.gif differ
diff --git a/assets/8/3004.gif b/assets/8/3004.gif
new file mode 100644
index 0000000000..dd2e42beab
Binary files /dev/null and b/assets/8/3004.gif differ
diff --git a/assets/8/3005.gif b/assets/8/3005.gif
new file mode 100644
index 0000000000..64b3ab965b
Binary files /dev/null and b/assets/8/3005.gif differ
diff --git a/assets/8/alstm.jpg b/assets/8/alstm.jpg
new file mode 100644
index 0000000000..b8b53b8bd9
Binary files /dev/null and b/assets/8/alstm.jpg differ
diff --git a/assets/8/convalstm.jpg b/assets/8/convalstm.jpg
new file mode 100644
index 0000000000..f15abf295e
Binary files /dev/null and b/assets/8/convalstm.jpg differ
diff --git a/assets/8/cycling.gif b/assets/8/cycling.gif
new file mode 100644
index 0000000000..4811b4d409
Binary files /dev/null and b/assets/8/cycling.gif differ
diff --git a/assets/8/fencing.gif b/assets/8/fencing.gif
new file mode 100644
index 0000000000..233a39f479
Binary files /dev/null and b/assets/8/fencing.gif differ
diff --git a/assets/8/final.gif b/assets/8/final.gif
new file mode 100644
index 0000000000..28d867a6bc
Binary files /dev/null and b/assets/8/final.gif differ
diff --git a/assets/8/shoot_ball.gif b/assets/8/shoot_ball.gif
new file mode 100644
index 0000000000..619a4319ed
Binary files /dev/null and b/assets/8/shoot_ball.gif differ
diff --git a/assets/8/test.md b/assets/8/test.md
new file mode 100644
index 0000000000..8b13789179
--- /dev/null
+++ b/assets/8/test.md
@@ -0,0 +1 @@
+
diff --git a/assets/8/walking.gif b/assets/8/walking.gif
new file mode 100644
index 0000000000..29188f0ed8
Binary files /dev/null and b/assets/8/walking.gif differ
diff --git a/assets/9/batch_1/Data_Space.gif b/assets/9/batch_1/Data_Space.gif
new file mode 100644
index 0000000000..17020ef105
Binary files /dev/null and b/assets/9/batch_1/Data_Space.gif differ
diff --git a/assets/9/batch_1/Likelihood.gif b/assets/9/batch_1/Likelihood.gif
new file mode 100644
index 0000000000..c8ae1780db
Binary files /dev/null and b/assets/9/batch_1/Likelihood.gif differ
diff --git a/assets/9/batch_1/Prior_Posterior.gif b/assets/9/batch_1/Prior_Posterior.gif
new file mode 100644
index 0000000000..e4b4743b38
Binary files /dev/null and b/assets/9/batch_1/Prior_Posterior.gif differ
diff --git a/assets/9/batch_50/Data_Space.gif b/assets/9/batch_50/Data_Space.gif
new file mode 100644
index 0000000000..c96f759fae
Binary files /dev/null and b/assets/9/batch_50/Data_Space.gif differ
diff --git a/assets/9/batch_50/Likelihood.gif b/assets/9/batch_50/Likelihood.gif
new file mode 100644
index 0000000000..6e02b732ee
Binary files /dev/null and b/assets/9/batch_50/Likelihood.gif differ
diff --git a/assets/9/batch_50/Prior_Posterior.gif b/assets/9/batch_50/Prior_Posterior.gif
new file mode 100644
index 0000000000..c6d4e9b8e9
Binary files /dev/null and b/assets/9/batch_50/Prior_Posterior.gif differ
diff --git a/assets/GEAR-cover.png b/assets/GEAR-cover.png
new file mode 100644
index 0000000000..3911b0d9fe
Binary files /dev/null and b/assets/GEAR-cover.png differ
diff --git a/assets/css/main.css b/assets/css/main.css
index 938d2e8e10..7553e15e2a 100755
--- a/assets/css/main.css
+++ b/assets/css/main.css
@@ -12,7 +12,7 @@ body {
@media (max-width: 30em) {
body {
font-size: 14px;
- line-height: 1.5rem;
+ line-height: 2rem;
}
body h1 {
font-size: 1.5rem;
@@ -63,12 +63,12 @@ blockquote {
.container {
margin-left: auto;
margin-right: auto;
- width: 615px;
+ width: 750px;
}
@media (max-width: 1366px) {
.container {
- width: 45vw;
+ width: 55vw;
}
}
diff --git a/assets/e1aa5101d18cc5ed9e9b22670c7794b9_original.jpg b/assets/e1aa5101d18cc5ed9e9b22670c7794b9_original.jpg
new file mode 100644
index 0000000000..8aa8d3565e
Binary files /dev/null and b/assets/e1aa5101d18cc5ed9e9b22670c7794b9_original.jpg differ
diff --git a/assets/gan.jpg b/assets/gan.jpg
new file mode 100644
index 0000000000..9989856554
Binary files /dev/null and b/assets/gan.jpg differ
diff --git a/assets/gan2.jpg b/assets/gan2.jpg
new file mode 100644
index 0000000000..c3cf772e32
Binary files /dev/null and b/assets/gan2.jpg differ
diff --git a/assets/geography.pdf b/assets/geography.pdf
new file mode 100644
index 0000000000..f5d4a5c07c
Binary files /dev/null and b/assets/geography.pdf differ
diff --git a/assets/img/GEAR-cover.png b/assets/img/GEAR-cover.png
new file mode 100644
index 0000000000..3911b0d9fe
Binary files /dev/null and b/assets/img/GEAR-cover.png differ
diff --git a/assets/img/ai-economist.jpg b/assets/img/ai-economist.jpg
new file mode 100644
index 0000000000..48ad6f70ab
Binary files /dev/null and b/assets/img/ai-economist.jpg differ
diff --git a/assets/img/alpha-zero-one.jpeg b/assets/img/alpha-zero-one.jpeg
new file mode 100644
index 0000000000..d84fefa172
Binary files /dev/null and b/assets/img/alpha-zero-one.jpeg differ
diff --git a/assets/img/alpha-zero-one.jpg b/assets/img/alpha-zero-one.jpg
new file mode 100644
index 0000000000..e4705606e4
Binary files /dev/null and b/assets/img/alpha-zero-one.jpg differ
diff --git a/assets/img/alpha-zero-one.png b/assets/img/alpha-zero-one.png
new file mode 100644
index 0000000000..57b4e8fe11
Binary files /dev/null and b/assets/img/alpha-zero-one.png differ
diff --git a/assets/img/attention.jpeg b/assets/img/attention.jpeg
new file mode 100644
index 0000000000..5869d82d94
Binary files /dev/null and b/assets/img/attention.jpeg differ
diff --git a/assets/img/attention.jpg b/assets/img/attention.jpg
new file mode 100644
index 0000000000..83d43ce1b7
Binary files /dev/null and b/assets/img/attention.jpg differ
diff --git a/assets/img/cards.jpg b/assets/img/cards.jpg
deleted file mode 100755
index cd13bf9646..0000000000
Binary files a/assets/img/cards.jpg and /dev/null differ
diff --git a/assets/img/cutting.jpg b/assets/img/cutting.jpg
deleted file mode 100755
index 856f2dc2bd..0000000000
Binary files a/assets/img/cutting.jpg and /dev/null differ
diff --git a/assets/img/face-recognition.jpg b/assets/img/face-recognition.jpg
new file mode 100644
index 0000000000..ab7739aaa1
Binary files /dev/null and b/assets/img/face-recognition.jpg differ
diff --git a/assets/img/forest.jpg b/assets/img/forest.jpg
deleted file mode 100755
index 378b556fb1..0000000000
Binary files a/assets/img/forest.jpg and /dev/null differ
diff --git a/assets/img/gan.jpeg b/assets/img/gan.jpeg
new file mode 100644
index 0000000000..84afd83df5
Binary files /dev/null and b/assets/img/gan.jpeg differ
diff --git a/assets/img/gan.jpg b/assets/img/gan.jpg
new file mode 100644
index 0000000000..0708b3b2d7
Binary files /dev/null and b/assets/img/gan.jpg differ
diff --git a/assets/img/gan2.jpg b/assets/img/gan2.jpg
new file mode 100644
index 0000000000..2b7f754fb2
Binary files /dev/null and b/assets/img/gan2.jpg differ
diff --git a/assets/img/mmm.jpg b/assets/img/mmm.jpg
new file mode 100644
index 0000000000..de9fddf4e0
Binary files /dev/null and b/assets/img/mmm.jpg differ
diff --git a/assets/img/mountains.jpg b/assets/img/mountains.jpg
deleted file mode 100755
index 315a7dc012..0000000000
Binary files a/assets/img/mountains.jpg and /dev/null differ
diff --git a/assets/img/options.jpeg b/assets/img/options.jpeg
new file mode 100644
index 0000000000..2c5b48601d
Binary files /dev/null and b/assets/img/options.jpeg differ
diff --git a/assets/img/options.jpg b/assets/img/options.jpg
new file mode 100644
index 0000000000..2d64332d14
Binary files /dev/null and b/assets/img/options.jpg differ
diff --git a/assets/img/prisoners.jpeg b/assets/img/prisoners.jpeg
new file mode 100644
index 0000000000..084dd3a6e2
Binary files /dev/null and b/assets/img/prisoners.jpeg differ
diff --git a/assets/img/sequential_bayes.jpg b/assets/img/sequential_bayes.jpg
new file mode 100644
index 0000000000..4a09942979
Binary files /dev/null and b/assets/img/sequential_bayes.jpg differ
diff --git a/assets/img/spools.jpg b/assets/img/spools.jpg
deleted file mode 100755
index b977cb7d37..0000000000
Binary files a/assets/img/spools.jpg and /dev/null differ
diff --git a/assets/img/thinker.jpeg b/assets/img/thinker.jpeg
new file mode 100644
index 0000000000..3ca4762f24
Binary files /dev/null and b/assets/img/thinker.jpeg differ
diff --git a/assets/img/thinker.jpg b/assets/img/thinker.jpg
new file mode 100644
index 0000000000..b520ed869a
Binary files /dev/null and b/assets/img/thinker.jpg differ
diff --git a/assets/img/tutorial_gif.gif b/assets/img/tutorial_gif.gif
new file mode 100644
index 0000000000..bbbbbd7602
Binary files /dev/null and b/assets/img/tutorial_gif.gif differ
diff --git a/assets/img/underthehood.jpg b/assets/img/underthehood.jpg
new file mode 100644
index 0000000000..ad49cc4f04
Binary files /dev/null and b/assets/img/underthehood.jpg differ
diff --git a/assets/img/warehouse.jpg b/assets/img/warehouse.jpg
new file mode 100644
index 0000000000..676660b962
Binary files /dev/null and b/assets/img/warehouse.jpg differ
diff --git a/assets/img/whatmatters.png b/assets/img/whatmatters.png
new file mode 100644
index 0000000000..da9f793425
Binary files /dev/null and b/assets/img/whatmatters.png differ
diff --git a/assets/me_blog.jpg b/assets/me_blog.jpg
new file mode 100644
index 0000000000..d5e45669fb
Binary files /dev/null and b/assets/me_blog.jpg differ
diff --git a/assets/thinker.jpg b/assets/thinker.jpg
new file mode 100644
index 0000000000..dac0133864
Binary files /dev/null and b/assets/thinker.jpg differ
diff --git a/assets/warehouse.jpg b/assets/warehouse.jpg
new file mode 100644
index 0000000000..778b9a3067
Binary files /dev/null and b/assets/warehouse.jpg differ
diff --git a/blog_image.png b/blog_image.png
new file mode 100644
index 0000000000..1e1445a20a
Binary files /dev/null and b/blog_image.png differ
diff --git a/favicon.ico b/favicon.ico
old mode 100755
new mode 100644
index 94009d96ae..9396ed0b7c
Binary files a/favicon.ico and b/favicon.ico differ
diff --git a/index.html b/index.html
index 6feb5caa0a..a87e3354f9 100755
--- a/index.html
+++ b/index.html
@@ -8,9 +8,9 @@
{{ post.title }}
- {% if post.image.feature %}
+ {% if post.image %}
-  +
+  {% endif %}
{% endif %}
@@ -21,17 +21,17 @@
{% endfor %}
-{% if paginator.total_pages > 1 %}
{% if paginator.next_page %}
- Older
+ {{ site.data.settings.pagination.previous_page }}
{% else %}
-
+
{% endif %}
+
{% if paginator.previous_page %}
- Newer
+ {{ site.data.settings.pagination.next_page }}
{% else %}
-
+
{% endif %}
-{% endif %}
+
diff --git a/README.md b/info.md
similarity index 100%
rename from README.md
rename to info.md
diff --git a/menu/about.md b/menu/about.md
old mode 100755
new mode 100644
index c5478be43e..4775d48fce
--- a/menu/about.md
+++ b/menu/about.md
@@ -1,5 +1,18 @@
---
layout: page
title: About
----
-Lagrange is a minimalist Jekyll. It is intended to have a clean, content focused interface for blog writing. For more information on how to install and use this theme, check out [the documentation]({{ site.github.url }}{% post_url 2016-01-01-welcome-to-lagrange %}).
+image: imageedit_6_6259696792.jpg
+---
+{:refdef: style="text-align: center;"}
+{:height="400px" width="400px"}
+{: refdef}
+Computer scientist interested in various flavors of machine learning, psychology and financial markets.
+
+I hold a M.Sc degree in Robotics, Cognition and Intelligence from Technical University of Munich, Germany.
+
+I have experience in areas of predictive maintance, autonomous driving and robotics.
+
+I am currently working as a research engineer at ARRIVAL. I am using deep reinforcement learning to to teach real robots how to assemble stuff.
+
+This website is designed to be my personal testing grounds for various projects, assignments, observations and reflexions.
+After hours, I am a lifelong learner, fitness enthusiast and self-proclaimed food aficionado.
diff --git a/menu/writing.md b/menu/blog.md
old mode 100755
new mode 100644
similarity index 98%
rename from menu/writing.md
rename to menu/blog.md
index d2e81bb7ec..b9de9bab83
--- a/menu/writing.md
+++ b/menu/blog.md
@@ -1,6 +1,6 @@
---
layout: page
-title: Writing
+title: Blog
---
{% for post in site.posts %}
diff --git a/menu/contact.md b/menu/contact.md
deleted file mode 100755
index 1cffecf472..0000000000
--- a/menu/contact.md
+++ /dev/null
@@ -1,6 +0,0 @@
----
-layout: page
-title: Contact
----
-
-If you are having any problems, any questions or suggestions, feel free to [tweet at me](https://twitter.com/intent/tweet?text=%40paululele), or [file a GitHub issue](https://github.com/lenpaul/lagrange/issues/new)
diff --git a/menu/projects.md b/menu/projects.md
new file mode 100644
index 0000000000..b7ae39a51e
--- /dev/null
+++ b/menu/projects.md
@@ -0,0 +1,20 @@
+---
+layout: page
+title: Projects
+---
+The growing list of my projects and other pieces of work I was involved in.
+{:refdef: style="text-align: center;"}
+{:height="300px" width="800px"}
+{: refdef}
+Cover image: ["The Robot Uprising"](https://www.kickstarter.com/projects/bryngjones/the-robot-uprising) by Bryn G Jones.
+
+__2020__
+
+1. [__Publication: Sim2Real for Peg-Hole Insertion with Eye-in-Hand Camera__](http://wordpress.csc.liv.ac.uk/smartlab/wp-content/uploads/sites/5/2020/05/ICRA2020ViTac_paper_2.pdf) - at ICRA 2020 ViTac Workshop. Research published while working at [ARRIVAL](https://arrival.com/). [Youtube recording](https://www.youtube.com/watch?v=qOtFIL3aHDg) of the presentation.
+2. **Talk: Applying Sim2Real Transfer To Industrial Robots**- at [Data Science Summit 2020](https://dssconf.pl). Link to the [talk on Youtube](https://www.youtube.com/watch?v=1BG5pC8WbTE).
+3. **Tutorial: Robotic Assembly Using Deep Reinforcement Learning**- on [PyTorch Medium Blog](https://link.medium.com/gwm2y0JdPab) and
+accompanying [GitHub Repository](https://github.com/arrival-ltd/catalyst-rl-tutorial). Created together with the team from [ARRIVAL](https://arrival.com/).
+
+__2019__
+
+1. [__Project - Reinforcement Learning with Unity 3D: G.E.A.R__](https://dtransposed.github.io/blog/GEAR) - design and development of an autonomous garbage collector agent.
diff --git a/test.png b/test.png
new file mode 100644
index 0000000000..9ad436d8ad
Binary files /dev/null and b/test.png differ