This repository provides code example for few popular Reinforcement Learning algorithms implemented by distributed reinforcement learning framework Oneagent. These examples are meant to serve as a tutorial of Oneagent and a learning resources of reinforcement learning.
-
DQN(Deep Q-Learning)
- DQN Vanilla
- Double DQN
- Dueling DQN
-
PPO(Proximal Policy Optimization)
- continuous PPO
- Discrete PPO
-
DDPG(deep deterministic policy gradient)
Each folder in corresponds to one or more implementation of reinforcement learning algorithm.
All code is written in Python 3 and pytorch, uses RL environments from OpenAI Gym.
-
Oneagent(need to add the link)
-
pytorch: version 1.9.0+cu111
-
gym: version 0.15.7
OneAgent强化学习框架创造性的使用微服务架构, 把强化学习的三个步骤分拆成 env, actor,learner 三个模块.
• env(服务端): 环境, 根据智能体所做出的动作做出反馈(reward)并对环境进行推演。
• actor(服务端):根据观察到的环境信息作为输入, 通过神经网络计算输出动作
• leaner(服务端):根据环境与actor交互所生成的轨迹(当前环境, 奖励, 所选动作, 更新后的环境, 所选动作概率)进行训练, 更新模型。
接下来为大家演示一下如何使用Oneagent框架进行DQN的训练
class Actor(Worker):
def __init__(self, **kwargs):
super().__init__()
self.policy = None
self.eval_cnt = 1
# 初始化DQN智能体
# 其中智能体可以替换为PPO智能体, DDPG智能体等不同的智能体
def initialize_policy(self):
env_name = 'CartPole-v1'#config.get_args().env_id
env = gym.make(env_name)
action_dim = env.action_space.n
state_dim = env.observation_space.shape[0]
self.policy = DQN_Agent(state_dim = state_dim, action_dim = action_dim)
# 推理服务
@service(response=True)
# 通过设置response=True, 使请求端在本远程服务没有完成之前进行阻塞
# 在推理服务中应该一直设为true
def policy_eval(self, state):
if self.policy is not None:
# state为模拟器/ENV发送的环境信息
# 智能体根据环境信息推理出动作
action = self.policy.action(state, self.ENV_A_SHAPE)
self.eval_cnt += 1
return action
# 订阅广播服务'policy_update', 接收learner更新后的模型
@event_handler('policy_update')
def handler(self, model):
if self.policy is None:
self.initialize_policy()
logger.info("successfully updated actor model")
# 更新模型参数
self.policy.model.load_state_dict(model)
logger.info('recv msg, update policy')
class Learner(Worker):
def __init__(self, **kwargs): # rank
super().__init__()
# 初始化模型, 设定更新参数
self.initialize_model()
# 初始化广播组件
self.ed = EventDispatcher()
# 设定更新参数
...........
def initialize_model(self):
env_name = 'CartPole-v1'#config.get_args().env_id
env = gym.make(env_name)
action_dim = env.action_space.n
state_dim = env.observation_space.shape[0]
self.policy = DQN_Agent(state_dim = state_dim,
action_dim = action_dim)
network_weight = self.policy.model.state_dict()
self.ed.fire("policy_update", payload= network_weight)
logger.info("initialize policy netork")
@service(response=False, batch=5)
def send_to_learner(self, experiences):
# 将传入的经验片段压入DQN智能体的经验池中
for experience in experiences:
experience = Experience(*experience)
self.policy.store_experience(experience)
result.append(None)
loss = self.policy.train()
if self.train_cnt % self.update_tar_interval == 0:
policy = self.policy.model.state_dict()
# 广播更新后的模型参数
self.ed.fire("policy_update", payload=policy)
return result
# 注册远程service服务
@remote
def policy_eval():
pass
@remote
def send_to_learner():
pass
def ensured_policy_eval(state):
while True:
data = policy_eval(state)
if data is not None:
return data
else:
time.sleep(1)
start = time.time()
for i_episode in range(1, max_episode):
state = env.reset()
#state = torch.FloatTensor(state)
ep_reward = 0
reward_list = []
for t in range(1, 1000):
# actor choose action
action = ensured_policy_eval(state)
# step action on env
next_state, reward, done, info = env.step(action)
# add reward to sum reward
ep_reward += reward
#next_state = torch.FloatTensor(next_frame)
#experience = Experience(*[state, reward, action, next_state, 0 if done else 1])
# send this experience to learner to learn
send_to_learner([state, reward, action, next_state, 0 if done else 1])
state = next_state
step += 1
if step % 1000 == 0:
end = time.time()
time_consumption = end - start
print("The time consumption for 1000 frames : %s, speed : %s"%(time_consumption, 1000/time_consumption))
start = time.time()
if done:
break
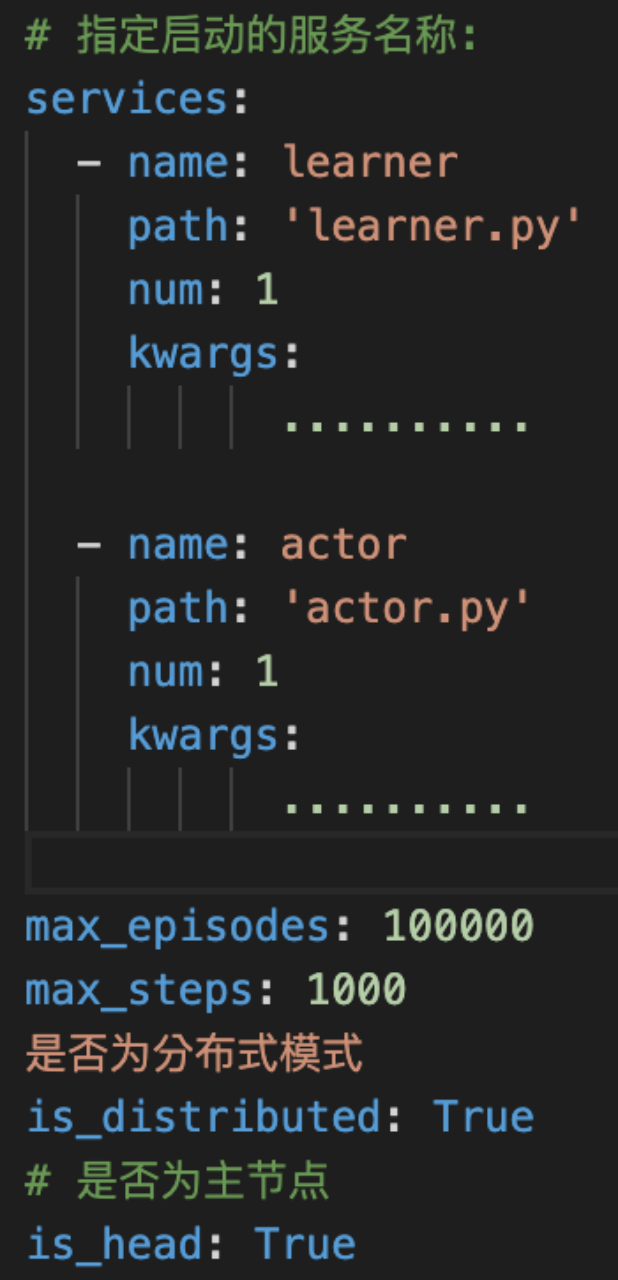
go to /algorithm/algorithm.yaml to edit training configuration
single version

distributed version
master node
slave node
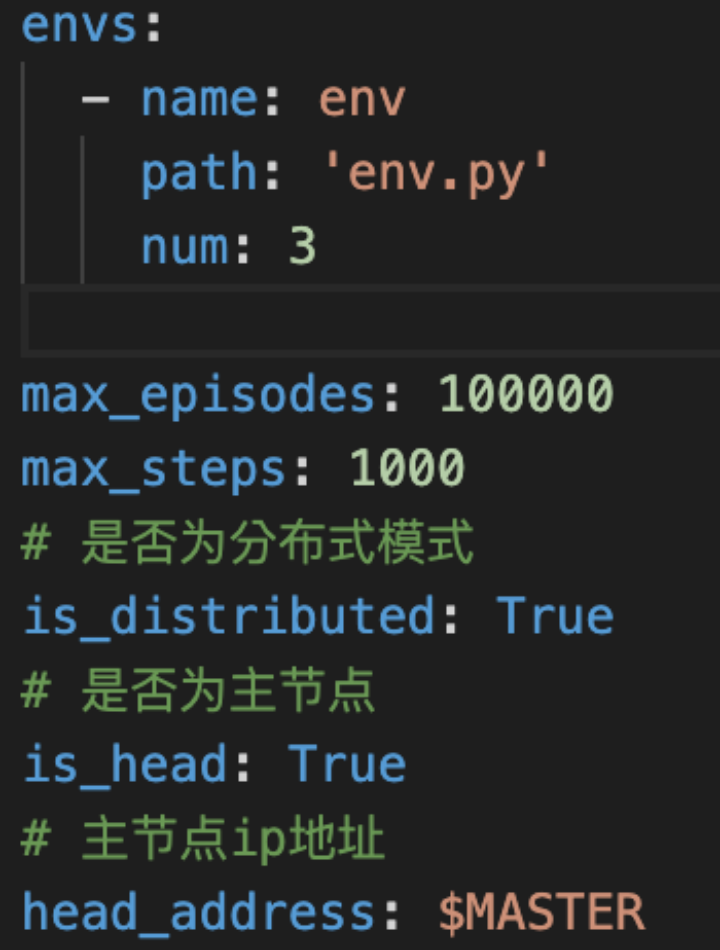
go to /algorithm
execute oneagent -c algorithm.yaml