Add llama.cpp LLM, brining support for locally hosted LLMs #8
Conversation
|
Awesome, thanks for adding @Zetaphor I tested out the llama agent, but noted that it was much slower with that Python binding than when I ran llama.cpp directly. There is also an issue about this here: abetlen/llama-cpp-python#49 Maybe there is a faster binding available? Also I think we should have the same interface for the LLMs, for example the LLama one now doesn't support the The parameters which are defined in the model are not passed on to the |
@mpaepper I am not sure if the python binding is entirely responsible for the high response time. The binding |
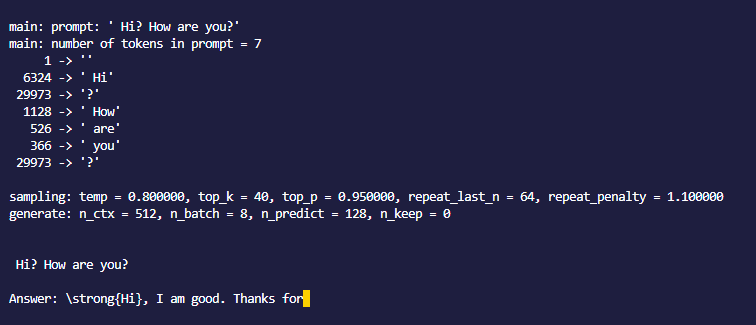
|
For me, llama.cpp runs a few seconds and with the binding it's more like 30 seconds |
|
I see, it's a lot faster for you, I'm kind of confused why it is taking so much time on my side. The owner of the For you, it might take longer because python and C++ are quite different in terms of execution time, since python is an interpreted language, unlike C++. It may be why it takes around 30 seconds. However, I am not sure if it's why, and I'm sure you know better than I do on this field. |
This PR adds the
llama-cpp-pythonpackage which adds support for locally hosted language models.This includes llama and GPT4All.