This readme serves as a documentation to understand our work done porting the Incompact3d application to use non-blocking communication.
This app uses a lot of communication by using the group of routines "transpose_*_to_*(src, dst)" that belong to the decomp2d module. The
same module also provides their analogous functions that can be used to make such routines non-blocking. Said non-blocking functions divide the original
function into a "_start" function and a "_wait" function that starts the communication in the background and waits until such communication is finished, respectively.
Our work was guided by a human algorithm we developed to port each transpose communication. We proceed to explain it:
In the first place, we had to change the files transpose_*_to_*.f90 and change each NBC call for its associated MPI call. Then, we made use of the following algorithm:
- Identify the last time the src variable was updated, and put the _start function just after it. The rationale for this is that we want to start the communication as soon as possible while having the correct value in the src variable.
- Identify the next time the dst variable is going to be used, and put the _wait function just before it. The rationale for this is to have the communication in the background for as long as possible, and to ensure that the dst variable has been fully updated and ready to use.
- Declare the buffer variables (sbuf and rbuf) at the beginning of each subroutine as allocatable, and having the same number of dimensions as its corresponding original variable (see the example below to understand it fully). E.g. if there is a src variable named "ta1" its send buffer variable will be "sbufta1" and have the same dimensions and size as "ta1".
- Allocate the buffer variables so that they have the same size on each dimension as its corresponding original variable.
- Add the deallocate lines at the end of the subroutine.
In file navier.f90:
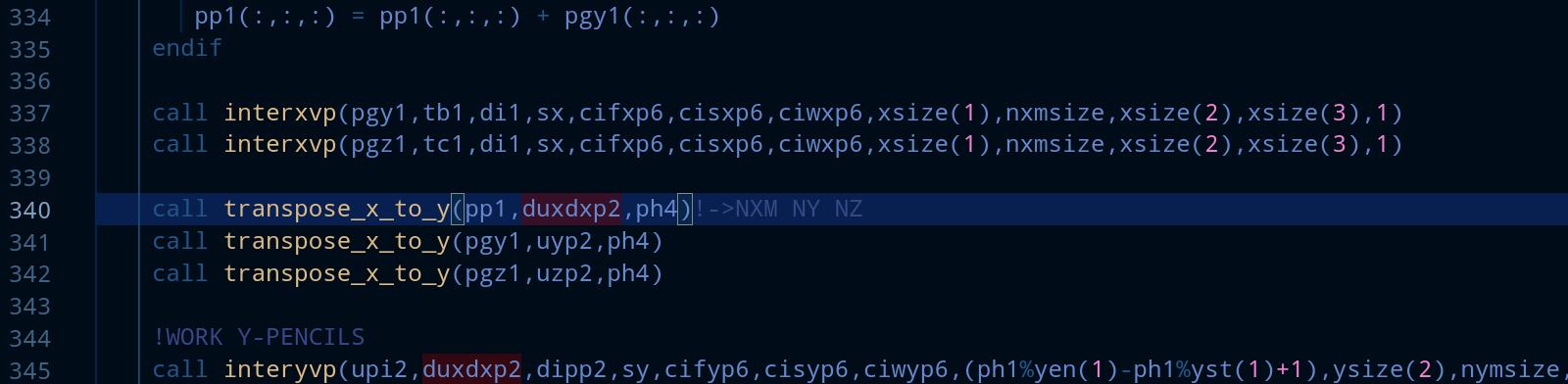
We will port the function transpose_x_to_y(pp1,duxdxp2,ph4). src=pp1 and dst=duxdxp2.
- We see that the last time pp1 was updated is on line 334.
- duxdxp2 is going to be used at 345. Here we can see that we can overlap the calculation made on lines 337-338 with the communication that is needed from pp1 to duxdxp2. After adding the _start and _wait directives the code looks like this:
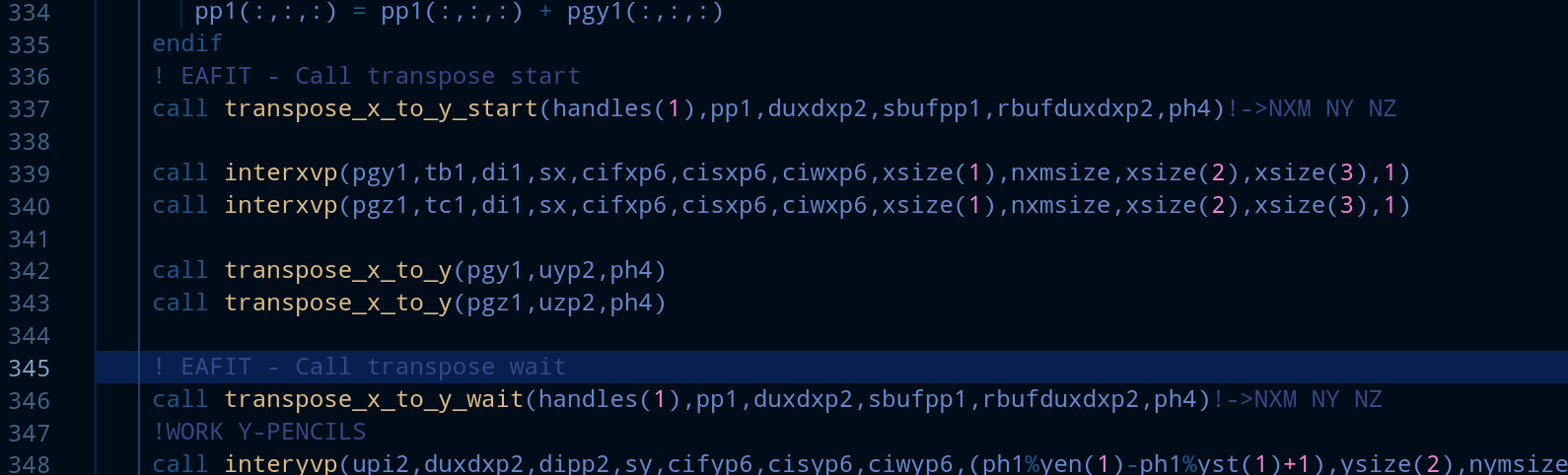
3 and 4. We declare the buffer variables and allocate them using the sizes of their respective original vectors:


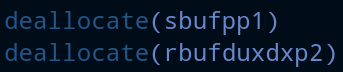
- We deallocate them at the end of the subroutine.
We identificated that not all transpose_*_to_* calls were worth to use its associated non-blocking behaviour. Because they were modificated right before they were used, so overlapping was not really happening. An example of this situation can be the following

In this case we can see that the transpose output variable is used almost immediately in the for loop, and the input variable is modified right before the transpose call
For improving performance, we ran mpiP profiler to identify which files did the most MPIALLTOALL calls, and change them to non blocking behaviour. The files we identified were the following
- src/BC-Cylinder.f90
- src/BC-TGV.f90
- src/forces.f90
- src/implicit.f90
- src/navier.f90
- src/transeq.f90
All these in addition to modifications in decomp2d changing from NBC to MPI call. Note: all these files were ported by the subteam that was working in coding challenge task; Vincent, Samuel and Manuela
- We found out that the non blocking strategy is not always the best option; depends on the context and how many different communication routines are being executed on the DPU.
- Overlapping computation and communication with DPU hides the latency in data transfer from the CPU perspective, so it improves performance.
- Overlapping computation and communication with DPUs is a way to improve performance by letting the CPU handle only what it really needs to compute, and relaying the communication to specialized hardware.
- The usage of Infiniband sightly affects the performance, since it is kernel by pass, we gain that time because we don't have to retrieve data from kernel, then, we gain that latency time.
- When one has too many communications on the background, they are not optimal and can be degreading for the performance. One should be aware of the quantity of communications going on the background. Had we have more time we would start to study how to make the number of background communications optimal for the BluField-2.
- Reuse of buffer variables to minimize wasted space.