스타트업 데이어와 진행한 모델링 프로젝트
pdf file Click here
-
2021.09.29 기준 최고 성능 모델
No. pre-trained model train step MAP Min 파라미터 조정 사항 19 ssd mobilenet v2 FPNLite 320x320 2000 0.929 13m box coder = {5,5,2,2}, warmup_learning_rate: 0.024, loss.classfication_weight = 1.3 -
별도의 hyperparameter 조정없이 pre-trained model을 변경하며 학습을 진행했을 때, 가장 성능이 좋은 모델은 ssd mobilenet v2 FPNLite 320x320였음.
-
비교 대상 모델
| 계열 | 모델 | 성능 (MAP, IoU = 0.5) |
|---|---|---|
| MobileNet 계열 | SSD MobileNet V2 FPNLite 320x320 | 0.85 |
| MobileNet 계열 | SSD MobileNet V2 FPNLite 640x640 | 0.803 |
| MobileNet 계열 | SSD MobileNet v2 320x320 | 0.797 |
| Resnet 계열 | ssd_resnet50_v1_fpn_keraㄴ | 0.414 |
| Resnet 계열 | ssd_resnet101_v1_fpn_640x640_coco17 | 0.317 |
| Resnet 계열 | ssd_resnet152_v1_fpn_640x640_coco17 | 0.26 |
-
Resnet보다는 Mobilenet을 활용한 모델이, 640x640보다는 320x320모델이, 특징추출 과정에서 FPN을 활용하는 모델이 성능이 좋은 경향이 있음.
-
이후 기본 pre-trained model을 ssd mobilenet v2 FPNLite 320x320로 고정하고, 최적 하이퍼 파라미터 조합을 찾음
| 조정사항 | 특징 | 최적 하이퍼 파라미터 |
|---|---|---|
| L2 regularizer weight | 작을수록 정확도 높아짐 | 최적의 파라미터 |
| Box coder scale | Scale 줄일수록 정확도 높아짐. | Default {10,10,2,2} {5,5,2,2} |
| warmup_learning_rate | learning_rate 조정 비율을 최적화 | Default = 0.026666000485420227 0.0024 |
| loss.classification weight | 분류 성능에 가중치를 둠 | (localization보다 classification이 더 불안정했음) 1.3 |
- Data augmentation 도 여러가지 방법을 시도해 보았지만 mAP 향상에 큰 도움이 되진 못하였습니다.
- 최종 모델에는 data augmentaiton이 디폴트 값으로 설정되어 있습니다.


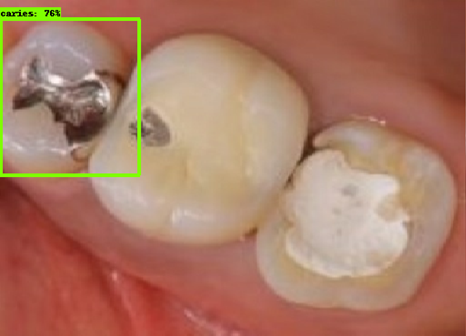
| 모델예측 | 정답 |
|---|---|
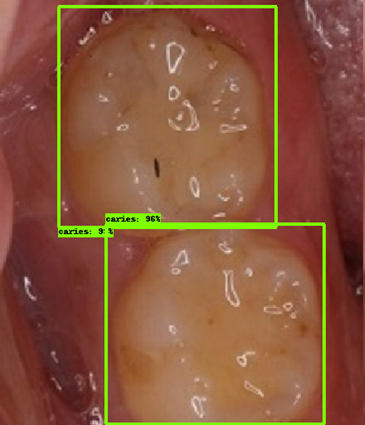 |
 |
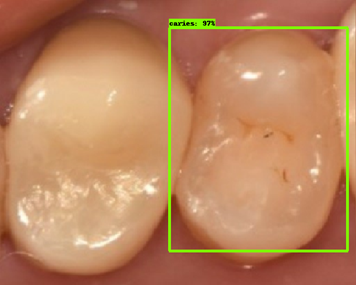 |
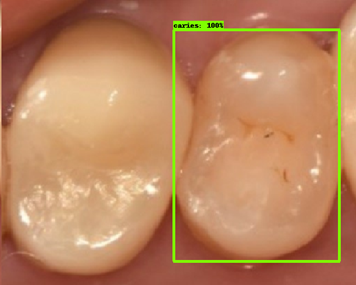 |
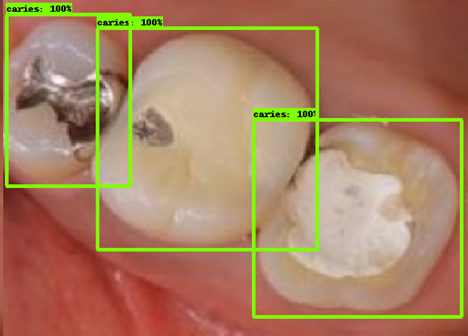
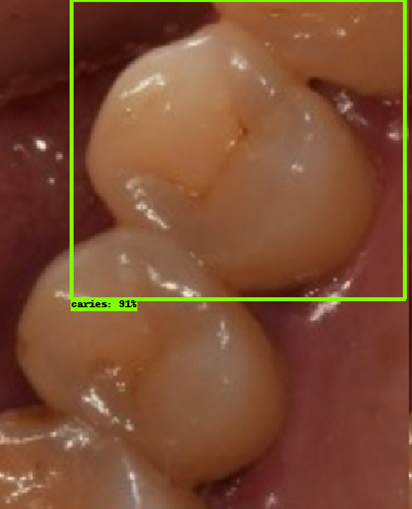
| 모델예측 | 정답 |
|---|---|
 |
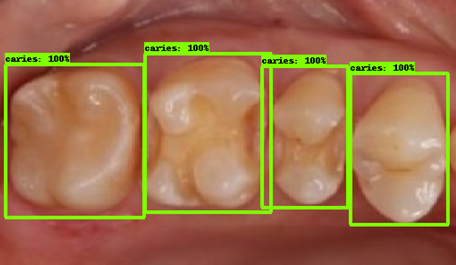 |
 |
 |
 |
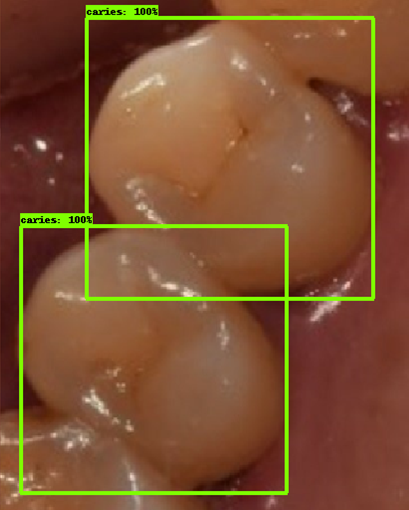 |
- 인식이 잘 되지 않은 케이스들을 보면, 사람의 눈으로 뚜렷하게 충치로 판단되는 치아를 모델이 잡아내지 못하는 경우도 있었지만, 그보다는 사람의 눈으로도 충치로 분류하기 어려운 경우에 모델역시 잘 분류해내지 못하는 것을 볼 수 있었습니다. 예를 들어, 인식이 잘되지 않은 첫번째 케이스, 세번째 케이스를 보면 정답지에는 충치 치아로 분류되어 있지만, 사람이 한눈에 보기에도 충치라고 판단하기 어려운 사진들이었습니다. 이러한 경우에 모델은 잘 잡아내지 못하고 있습니다.