Language: python3.9
Framework: django, django-rest-framework
Storage: mariadb
# request
curl --location --request POST 'http://localhost:8000/boards/' \
--header 'Accept: application/json' \
--header 'Content-Type: application/json' \
--data-raw '{
"url" : "https://school.iamservice.net/organization/19710/group/2091428"
}'
# response
{
"count": 10,
"data": [
{
"id": 497,
"url": "http://school.iamservice.net/articles/view/135836925",
"title": "2022년 겨울철 교육시설물 안전점검 실시 결과",
"body": "<p style=\"text-align: left;\">\n<br>\t\t\n<br>\t\t2022년 겨울철 학교시설물 안전점검 결과를 붙임과 같이 공개합니다.<br><br>붙임 2022년 겨울철 교육시설물 안전점검 실시 결과 1부.</p>",
"published_datetime": "2022-12-27T00:00:00+09:00",
"site": "IAM",
"attachment_list": [
{
"file_name": "교육시설 안전점검 실시 결과(2022 겨울철).pdf"
}
]
}
]
}게시물 크롤링이 지원되는 지원되는 url의 형태는 아래와 같습니다.
-
BBC feeds
-
네이버 블로그
- https://blog.naver.com/PostList.nhn?blogId=sntjdska123&from=postList&categoryNo=51
- querystring에 blogId가 포함된 형태만 지원.
-
아이엠스쿨 기관 프로필
- 각 게시물의 id로 추정되는 logNo들을 포함하는 api로 json요청
path: PostTitleListAsync.naver
query : blogId, categoryNo(optional), currentPage, countPerPage
- 각 게시물의 html수집
path: PostView.naver
query : blogId, categoryNo(optional), logNo
- 각 게시물의 id가 있는 api를 통해 json요청
기존 Path: https://school.iamservice.net/organization/1674
변경 Path: https://school.iamservice.net/api/article/organization/1674
- response로 받은 json의 view_link property를 통해 각 게시물 html 수집
본문이 동적으로 js render되기 때문에 webdriver사용.
- http://feeds.bbci.co.uk/news/rss.xml 페이지에서 게시물 url탐색 후 수집
크롤링시 데이터에 👏와 같은 이모티콘이 있는 경우에 오류가 나는 경우가 존재했습니다.
먼저 데이터베이스와 컬럼의 인코딩을 모두 확인해보았는데도 utf8mb4로 잘 설정되어있었습니다.
데이터 베이스 인코딩 뿐만아니라 django의 settings.py의 charset또한 utf8mb4로 맞춰주어야 데이터를 알맞게 인코딩해서 넘겨줄수 있다는 점을 알았습니다.
BBC의 작성일자는 영국시간(UTC)이고 아이엠스쿨과 네이버 블로그의 시간은 (UTC+9)입니다.
이처럼 사이트마다 작성시간이 달라질 수 있는 부분이 존재했습니다.
크롤링 후 각 데이터에 timezone을 설정해줬습니다. 네이버 블로그에서 나온 데이터에는 아래와 같이 Asia/Seoul의 datetime임을 나타내도록했습니다.
datetime.replace(tzinfo=zoneinfo.ZoneInfo("Asia/Seoul"))위처럼하면 13시 5분의 데이터는 UTC+9의 13시 5분 데이터로써 DB에는 4시 5분으로 저장됩니다.
DB의 데이터는 전부 UTC 시간을 저장하도록 했습니다.
중복 게시물 처리를 하기 전까지의 crawler는 get_posts()요청이 들어오면 바로 url의 index페이지를 확인 후, 10개의 게시물을 확인하는 요청을 보냈습니다.
중복 게시물 처리를 위해서는 db조회를 하기 위한 게시물의 unique key 가 필요했고,
중복 게시물을 걸러낸후에는 게시물을 요청하기위해 필요한 데이터가 필요했습니다. (Ex) url, json)
따라서 크롤러 내부에 어떤 게시물을 가져올지에 대한 데이터 유지가 필요했습니다.
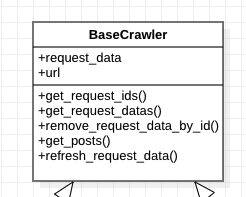
최상위 클래스인 BaseCrawler클래스에서 request_data라는 이름의 dictionary로 필요한 데이터를 유지했습니다.
-
key : 게시물의 unique id
-
value: 게시물을 가져오기 위해 필요한 Data
중복인 게시물은 remove_request_data_by_id()를 통해 request_data에서 삭제했습니다.
API를 하나만드는 것이기때문에 되도록이면 django내부의 기능만을 사용하려했습니다.
하지만 API응답을 위한 django.core.serializers가 응답을 커스텀하기에 직관적이지 않았습니다.
또한 TIME_ZONE설정을 자동으로 반영해주지 않았습니다.
반면 django-rest-framework는 두가지 기능을 모두 편리하게 지원해줘 사용했습니다.